• しかし、JVM環境でのMemory MappedFileは2GBまでしか
マッピングできません。
http://stackoverflow.com/questions/8076472/why-does-
filechannel-map-take-up-to-integer-max-value-of-data
• Apache Spark MLlib開発責任者のReynold XinさんがGistに
ByteBufferシリーズのパフォーマンス計測を記述していま
す。
これはScalaで書かれていてとても参考になります。
https://gist.github.com/rxin/5087680
more information
MMF can map only map up to 2GB file on JVM.
13.
爆速 No.1
Memory MappedFileで
高速ファイル操作が可能に!
No.1 using MMF, you can operate on files at high speed!
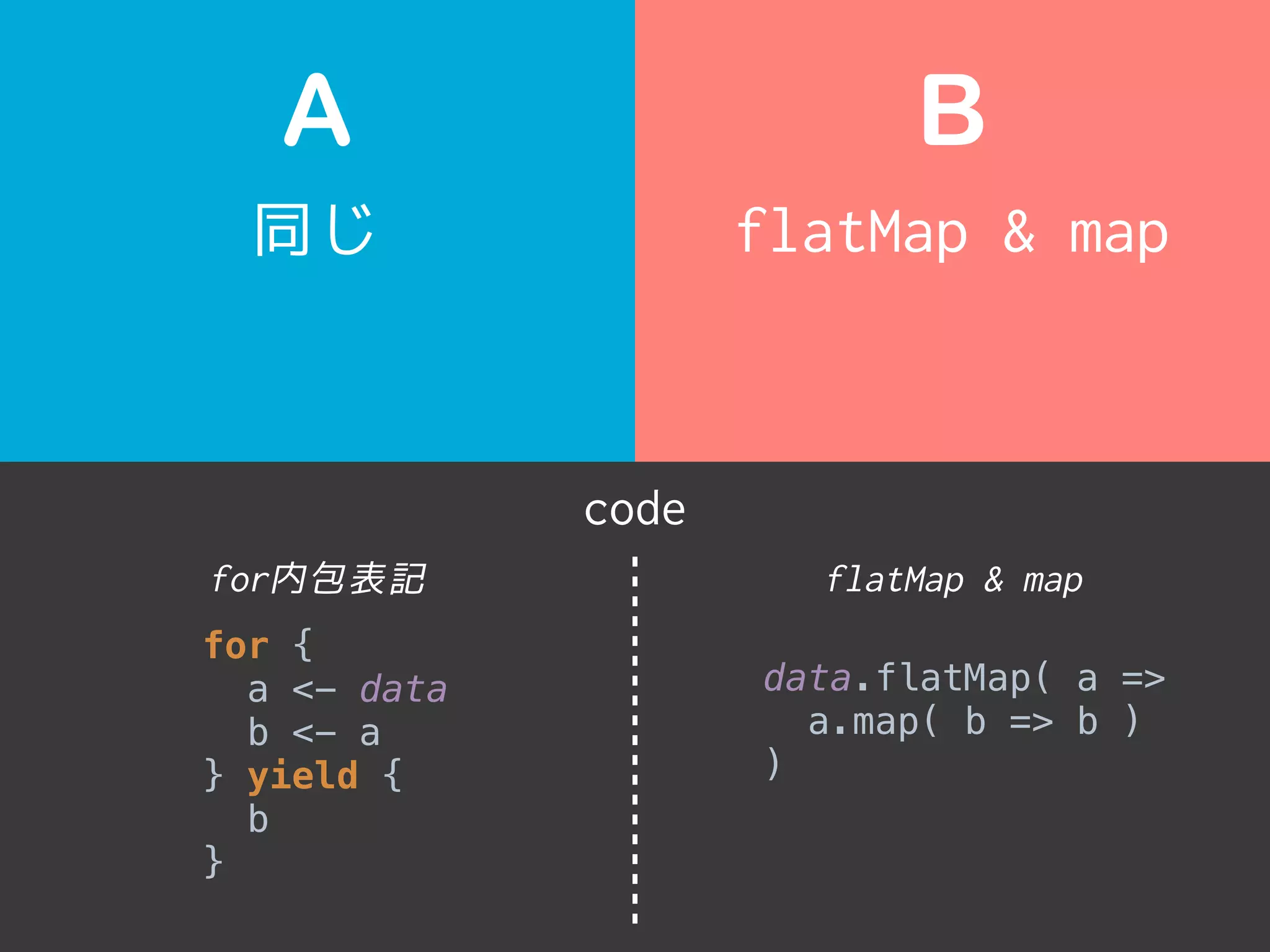
• for内包表記 とflatMap & map は論理的に同じです。
• 下記はデコンパイルしたコードですが全く同じです。
Why are they the same speed?
for comprehension and flatMap&map are logically same.
public Option<String> forComprehension()
{
data().flatMap(new AbstractFunction1()
{
public static final long serialVersionUID = 0L;
public final Option<String> apply(Some<String> a)
{
a.map(new AbstractFunction1()
{
public static final long serialVersionUID = 0L;
public final String apply(String b)
{
return b;
}
});
}
});
}
public Option<String> flatMapAndMap()
{
data().flatMap(new AbstractFunction1()
{
public static final long serialVersionUID = 0L;
public final Option<String> apply(Some<String> a)
{
a.map(new AbstractFunction1()
{
public static final long serialVersionUID = 0L;
public final String apply(String b)
{
return b;
}
});
}
});
}
for comprehension flatMap & map
20.
爆速 No.2
for内包表記 とflatMap & map は
バイト・コードのレベルで同じです。
No.2 for comprehension and flatMap&map are same.
Why is ArrayBufferfaster than Vector?
新しく要素を追加するときのコードを比較してみます。
These processes are absolutely different.
新しいインスタンスに既存の
要素をコピーしてから新しい
要素を追加します。
インスタンスのリサイズを行っ
てから末尾の要素を新要素で
更新します。
var Vector val ArrayBuffer
val b = bf(repr)
b ++= thisCollection
b += elem
b.result()
ensureSize(size0 + 1)
array(size0) =
elem.asInstanceOf[AnyRef]
size0 += 1
this
Vector と ArrayBuffer でプロセスが全く異なります。
29.
Q3-2
可変な “var xs:List”
と
不変な “val xs: ListBuffer”
先頭挿入が速いのはどちらでしょう?
When inserting into List or ListBuffer, which is faster?
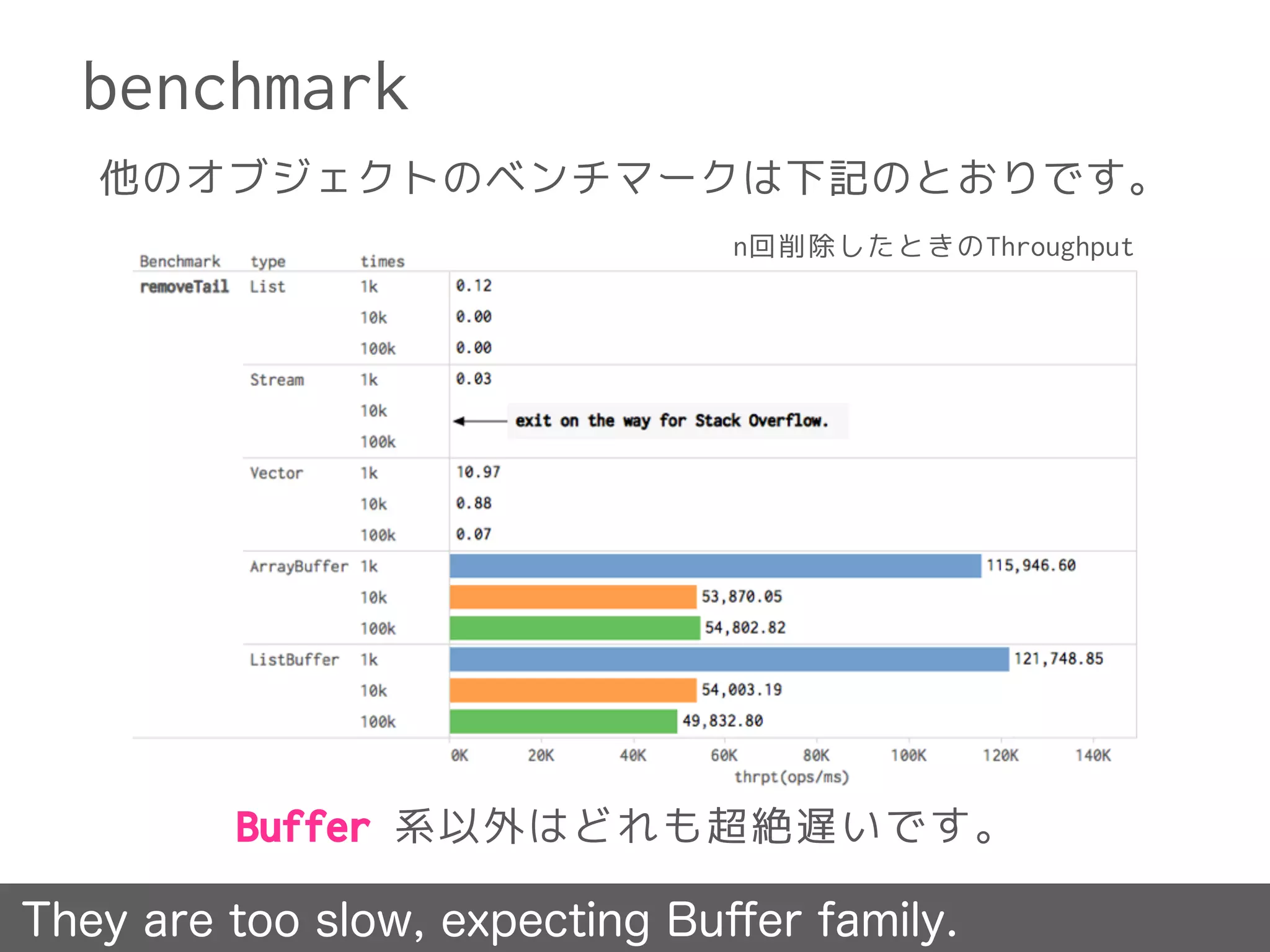
benchmark
List の方が ListBufferよりも速いです。
List is faster than ListBuffer.
n回先頭挿入したときのThroughput
上記のグラフはN個の要素を先頭に追加したときのスループットを表しています。
例えばtypeがList, timesが1kの場合では、1,000個の要素を空のListの先頭に挿
入していったときのスループットを意味しています。
Why is Listfaster than the others?
要素を先頭挿入するときのコードを比較してみます。
List calculate a little, in case of inserting.
Listは先頭とその他の要素を
別管理しているため、新しい
要素をすぐに作れます。
ListBufferはListとほとんど
一緒なのですが内部変数の再
代入が行われます。
var List val ListBuffer
new
scala.collection.immutable
.::(x, this)
if (exported) copy()
val newElem = new :: (x, start)
if (isEmpty) last0 = newElem
start = newElem
len += 1
this
List ではほとんど計算せずに先頭挿入が行えます。
35.
爆速 No.3
末尾追加のときは ArrayBufferや
ListBuffer を使うと効率が良いです。
しかし先頭挿入のときは List を使うと
良いパフォーマンスが得られます。
No.3 appending => **Buffer, inserting => List are nice.
Q4
可変な “var xs:List”
と
不変な “val xs: ListBuffer”
削除が速いのはどちらでしょう?
When removing from List or ListBuffer, which is faster?
38.
var List
A
val ListBuffer
B
code
varxs: List val xs: ListBuffer
var xs =
List( 1 to n: _* )
// head
xs = xs.tail
// tail
xs = xs.dropRight(0)
var xs =
ListBuffer( 1 to n: _* )
// head
xs.remove(0)
// tail
xs.remove(xs.size - 1)
Why is ListBufferfaster than List?
要素を削除するときのコードを比較してみます。
The operation dropRight of List takes time O(n).
ListのdropRightの操作はO(n)
の時間がかかります。
ListBufferのremove操作は定
数時間です。
var List val ListBuffer
def dropRight(n: Int): Repr = {
val b = newBuilder
var these = this
var lead = this drop n
while (!lead.isEmpty) {
b += these.head
these = these.tail
lead = lead.tail
}
b.result()
}
def remove(n: Int): A = {
:
var cursor = start
var i = 1
while (i < n) {
cursor = cursor.tail
i += 1
}
old = cursor.tail.head
if (last0 eq cursor.tail) last0 =
cursor.asInstanceOf[::[A]]
cursor.asInstanceOf[::[A]].tl
= cursor.tail.tail
43.
benchmark of List’sdropRight
このベンチマークは10倍づつサイズを増やしているので、ス
ループットも底10で対数表示します。
Throughput is just only lowered to linear.
スループットはただ線形に下降しているだけです。
操作時間線形増加の恐怖です。
Q3で出てきたVectorの末尾追加も線形増加なのですが、同じ線形増加でも削除のほうが
増加率が大きいので、パフォーマンスがすごく落ちているように感じます。
List - dropRightのlog(Throughput)
44.
reference benchmark
Comparing dropRightwith take.
dropRight(1) と take(n-1) で同じ機能を実現できる
ので、dropRight と take を比較しました。
take は dropRight より少しだけ速いです。
Throughput of List’ dropRight and take
45.
爆速 No.4
たくさんの要素を削除するときは
ListBuffer やArrayBuffer を使うと
効率が良いです。
No.4 When removing element, **Buffer are good.
削除に限らずなんですが、基本的にはimmutableなオブジェクトよりもmutableな
Buffer系の方が書き込み操作は速いです。
Vector
A
ListBuffer
B
code
val data =
Vector(1 to n: _* )
( 1 to data.size ) map { _ =>
data( Random.nextInt( n ) )
}
val data =
ListBuffer( 1 to n: _* )
( 1 to data.size ) map { _ =>
data( Random.nextInt( n ) )
}
Stream
A
Array
B
* 再帰的に計算します。
* 計算量O(n)のロジック
です。
code
deffibonacci(
h: Int = 1,
n: Int = 1 ): Stream[Int] =
h #:: fibonacci( n, h + n )
val fibo = fibonacci().take( n )
def fibonacci( n: Int = 1 ): Array[Int] =
if ( n == 0 ) {
Array.empty[Int]
} else {
val b = new Array[Int](n)
b(0) = 1
for ( i <- 0 until n - 1 ) {
val n1 = if ( i == 0 ) 0 else b( i - 1 )
val n2 = b( i )
b( i + 1 ) = n1 + n2
}
b
}
val fibo = fibonacci( n )
Why is Streamso much faster?
Stream implements lazy list evaluated when needed.
• Stream は遅延評価リストを実装しているので必要なときに
だけ計算されます。
• 実際fibonacciメソッド(前ページ)を呼び出した時点ではフィ
ボナッチ数列はまだ計算されていません。
• これが遅延評価の力です。
• しかし数列が具現化されるときにはそれなりの計算時間を
必要とします。
→ 次ページをごらんください。
60.
Why is Streamso much faster?
if the sequence is materialized, it takes calculating time.
Stream の toList を実行したときのベンチマークです。
Stream で toList を実行すると、Array が最も速いです。
これは Array で使っている計算ロジックが再帰による計算
よりも速いことを示します。
長さnのフィボナッチ数列をつくったときのスループット
同じ
A
findPrefixOf
B
code
val re ="""(?<=w+)/.+""" r
val ms = re findAllIn data
if ( ms.isEmpty ) None
else Some( ms.next )
val re = “""w+/""" r
re findPrefixMatchOf data map(
_.after.toString
)
findAllIn と 肯定的後読み findPrefixOf と 量指定子
benchmark of variousregular expressions
Even if given same regex, findPrefixOf is fastest.
同じ正規表現を実行しても findPrefixOf が一番速いです。
findPrefixOf と 肯定的後読みの組み合わせは良いパフォーマンスが
得られます。
1,000回実行時のスループット
70.
findPrefixOf usage infamous library
ルーティング・ツリーはURIパスの先頭から構築するので、
findAllIn よりも findPrefixOf が適しています。
findPrefixOf is used in spray-routing.
implicit def regex2PathMatcher(regex: Regex): PathMatcher1[String] =
regex.groupCount match {
case 0 ⇒ new PathMatcher1[String] {
def apply(path: Path) = path match {
case Path.Segment(segment, tail) ⇒ regex findPrefixOf segment match {
case Some(m) ⇒ Matched(segment.substring(m.length) :: tail, m :: HNil)
case None ⇒ Unmatched
}
case _ ⇒ Unmatched
}
}
:
https://github.com/spray/spray/blob/master/spray-routing/src/main/scala/spray/routing/PathMatcher.scala
PathMatcher.scala line:211
下記は spray-routing のコードを一部抜粋したものです。







![benchmark
上記のグラフは、下記のような2GBのデータから”SUIKA”
という文字列を探したときの平均タイムです。
• ファイルの場合は8秒未満で完了します。
• memcacheの場合は19秒近くかかりました。
• memcacheと同じKVSのRedisでは14秒弱でした。
'''<code>&h</code>''' を用い、<code>&h0F</code> (十進で15)のように表現する。
nn[[Standard Generalized Markup Language|SGML]]、[[Extensible Markup Language|XML]]、
[[HyperText Markup Language|HTML]]では、アンパサンドをSUIKA使って[[SGML実体]]を参照する。
the average for the time searching string - SUIKA .](https://image.slidesharecdn.com/scalaja-160130032955/75/Scala-9-2048.jpg)













![var Vector
A
val ArrayBuffer
B
code
var xs = Vector.empty[Int]
xs = xs :+ a
var xs: Vector val xs: ArrayBuffer
val xs = ArrayBuffer.empty[Int]
xs += a](https://image.slidesharecdn.com/scalaja-160130032955/75/Scala-24-2048.jpg)



![Why is ArrayBuffer faster than Vector?
新しく要素を追加するときのコードを比較してみます。
These processes are absolutely different.
新しいインスタンスに既存の
要素をコピーしてから新しい
要素を追加します。
インスタンスのリサイズを行っ
てから末尾の要素を新要素で
更新します。
var Vector val ArrayBuffer
val b = bf(repr)
b ++= thisCollection
b += elem
b.result()
ensureSize(size0 + 1)
array(size0) =
elem.asInstanceOf[AnyRef]
size0 += 1
this
Vector と ArrayBuffer でプロセスが全く異なります。](https://image.slidesharecdn.com/scalaja-160130032955/75/Scala-28-2048.jpg)

![var List
A
val ListBuffer
B
code
var xs = List.empty[Int]
xs = a :: xs
var xs: List val xs: ListBuffer
val xs = ListBuffer.empty[Int]
a +=: xs](https://image.slidesharecdn.com/scalaja-160130032955/75/Scala-30-2048.jpg)










![Why is ListBuffer faster than List?
要素を削除するときのコードを比較してみます。
The operation dropRight of List takes time O(n).
ListのdropRightの操作はO(n)
の時間がかかります。
ListBufferのremove操作は定
数時間です。
var List val ListBuffer
def dropRight(n: Int): Repr = {
val b = newBuilder
var these = this
var lead = this drop n
while (!lead.isEmpty) {
b += these.head
these = these.tail
lead = lead.tail
}
b.result()
}
def remove(n: Int): A = {
:
var cursor = start
var i = 1
while (i < n) {
cursor = cursor.tail
i += 1
}
old = cursor.tail.head
if (last0 eq cursor.tail) last0 =
cursor.asInstanceOf[::[A]]
cursor.asInstanceOf[::[A]].tl
= cursor.tail.tail](https://image.slidesharecdn.com/scalaja-160130032955/75/Scala-42-2048.jpg)









![Why Array, ArrayBuffer, Vector are fast?
Such as Vector uses Array - constant time - internal.
• Array のランダム・リードは定数時間です。
• ArrayBuffer と Vector は内部的に Array を使っています。
protected var array: Array[AnyRef]
= new Array[AnyRef](math.max(initialSize, 1))
:
def apply(idx: Int) = {
if (idx >= size0) throw new IndexOutOfBoundsException(idx.toString)
array(idx).asInstanceOf[A]
}
例) ArrayBuffer](https://image.slidesharecdn.com/scalaja-160130032955/75/Scala-52-2048.jpg)



![Stream
A
Array
B
* 再帰的に計算します。
* 計算量O(n)のロジック
です。
code
def fibonacci(
h: Int = 1,
n: Int = 1 ): Stream[Int] =
h #:: fibonacci( n, h + n )
val fibo = fibonacci().take( n )
def fibonacci( n: Int = 1 ): Array[Int] =
if ( n == 0 ) {
Array.empty[Int]
} else {
val b = new Array[Int](n)
b(0) = 1
for ( i <- 0 until n - 1 ) {
val n1 = if ( i == 0 ) 0 else b( i - 1 )
val n2 = b( i )
b( i + 1 ) = n1 + n2
}
b
}
val fibo = fibonacci( n )](https://image.slidesharecdn.com/scalaja-160130032955/75/Scala-56-2048.jpg)













![findPrefixOf usage in famous library
ルーティング・ツリーはURIパスの先頭から構築するので、
findAllIn よりも findPrefixOf が適しています。
findPrefixOf is used in spray-routing.
implicit def regex2PathMatcher(regex: Regex): PathMatcher1[String] =
regex.groupCount match {
case 0 ⇒ new PathMatcher1[String] {
def apply(path: Path) = path match {
case Path.Segment(segment, tail) ⇒ regex findPrefixOf segment match {
case Some(m) ⇒ Matched(segment.substring(m.length) :: tail, m :: HNil)
case None ⇒ Unmatched
}
case _ ⇒ Unmatched
}
}
:
https://github.com/spray/spray/blob/master/spray-routing/src/main/scala/spray/routing/PathMatcher.scala
PathMatcher.scala line:211
下記は spray-routing のコードを一部抜粋したものです。](https://image.slidesharecdn.com/scalaja-160130032955/75/Scala-70-2048.jpg)





![[Cloud OnAir] BigQuery の仕組みからベストプラクティスまでのご紹介 2018年9月6日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/dddddd-180906091548-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[C33] 24時間365日「本当に」止まらないデータベースシステムの導入 ~AlwaysOn+Qシステムで完全無停止運用~ by Nobuyuki Sa...](https://cdn.slidesharecdn.com/ss_thumbnails/c33sqlserversasaki-131128193643-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)










































