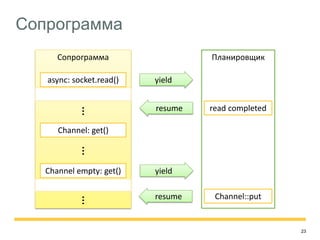
Документ обсуждает использование асинхронности и сопрограмм для обработки данных, предлагал параллельные методы обработки и улучшение производительности без необходимости синхронизации. Рассматриваются проблемы традиционных подходов, такие как контроль потребления памяти и сложности при сетевых взаимодействиях, а также предлагаются решения на основе использования каналов и сопрограмм. Документ также включает примеры реализации таких методов и обсуждает будущие планы по оптимизации и распределенности.






















![24
Обработчики Связь двух каналов
template<typename T_src, typename T_dst, typename F_pipe>
void piping(T_src& s, T_dst& d, F_pipe f, int n = 1)
{
goN(n, [&s, &d, f] {
auto c = closer(d);
f(s, d);
});
}
piping(c1, c2, [](Channel<int>& src, Channel<int>& dst) {
for (int v: src)
dst.put(v + 1);
});
closer: автоматически закрывает канал
goN: асинхронно запускает n сопрограмм](https://image.slidesharecdn.com/yandex-dataprocessing-final-141031074802-conversion-gate01/85/slide-24-320.jpg)
![25
Обработчики Связь двух каналов 1 к 1 (map)
template<typename T_src, typename T_dst, typename F_pipe>
void piping1to1(T_src& s, T_dst& d, F_pipe f, int n = 1)
{
piping(s, d, [f] (T_src& s, T_dst& d) {
for (auto&& v: s)
d.put(std::move(f(v)));
}, n);
}
piping1to1(c1, c2, [](int v) {
return v + 1;
}, 10);
будет запущено 10 обработчиков](https://image.slidesharecdn.com/yandex-dataprocessing-final-141031074802-conversion-gate01/85/slide-25-320.jpg)
![26
Разделение каналов
go([&] {
auto c1 = closer(contentHref);
auto c2 = closer(contentText);
for (auto&& c: content)
{
contentHref.put(c);
contentText.put(c.second);
}
});
Split
Парсинг: текст
Парсинг:
href
host + body
body
host + body
body](https://image.slidesharecdn.com/yandex-dataprocessing-final-141031074802-conversion-gate01/85/slide-26-320.jpg)

![28
Пример обработчика: ссылки Преобразование ссылки из строки в host+path
StrPair parseUrl(const Str& url)
{
static const regex e("http://([wd._-]*[wd_-]+)(.*)", regex::icase);
smatch what;
bool result = regex_search(url, what, e);
if (!result)
return {};
Str host = what[1];
Str path = what[2];
if (path.empty())
path = "/";
return {host, path};
}
piping1to01(filteredUrl, parsedUrl, parseUrl);
piping1to01: игнорирует пустые элементы](https://image.slidesharecdn.com/yandex-dataprocessing-final-141031074802-conversion-gate01/85/slide-28-320.jpg)
![29
Пример обработчика: слова Разделение текста на отдельные слова
void splitWords(const Str& text, Channel<Str>& words)
{
static const regex e("([a-zA-Z]+)");
sregex_token_iterator i = make_regex_token_iterator(text, e, 1);
sregex_token_iterator ie;
while (i != ie)
words.put(*i++);
}
piping1toMany(text, words, splitWords);
piping1toMany: один ко многим](https://image.slidesharecdn.com/yandex-dataprocessing-final-141031074802-conversion-gate01/85/slide-29-320.jpg)












 {
w.setProceed(std::move(proceed));
mutex.unlock();
});
return w.hasValue();
}
значение в очереди => сразу возвращаем
создаем ожидающего и добавляем его в список
устанавливаем обработчик для возобновления выполнения
после продолжения значение записывается в переменную val (при наличии)](https://image.slidesharecdn.com/yandex-dataprocessing-final-141031074802-conversion-gate01/85/slide-42-320.jpg)





































































![[C++ CoreHard Autumn 2018] Actors vs CSP vs Task...](https://cdn.slidesharecdn.com/ss_thumbnails/actorsvscspvstasks-181104072639-thumbnail.jpg?width=640&height=640&fit=bounds)























