Download to read offline



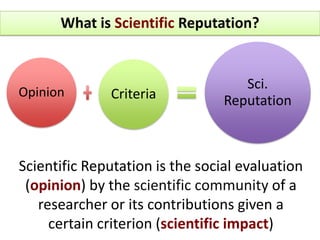

![Science is an Economy of Reputation [Whitley 2000]MotivationImprove support for Decision MakingReadershipAffiliationBibliometrics](https://image.slidesharecdn.com/2011-06-14cristhianparraucount-110615090146-phpapp01/85/2011-06-14-cristhian-parra_u_count-5-320.jpg)
![[Insert footer]DatasetTop H-Index (>200)79 total Replies8 Online SurveysICWE (18)BPM (20)VLDB (15)...http://reseval.org/surveyhttp://www.cs.ucla.edu/~palsberg/h-number.htmlExperiment #1: LiquidReputation Surveys](https://image.slidesharecdn.com/2011-06-14cristhianparraucount-110615090146-phpapp01/85/2011-06-14-cristhian-parra_u_count-6-320.jpg)
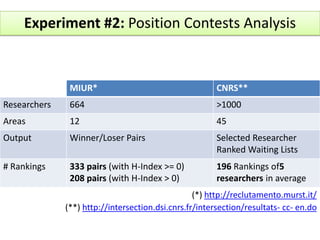

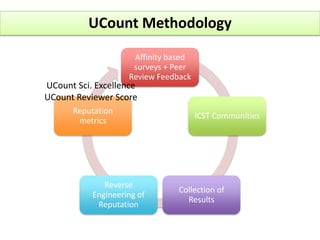
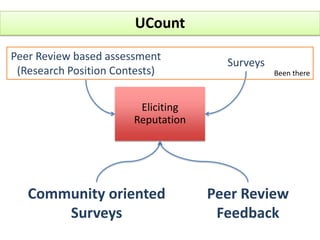
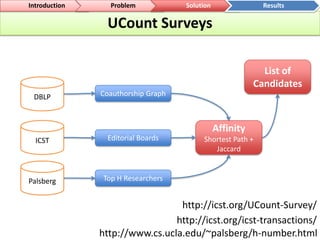
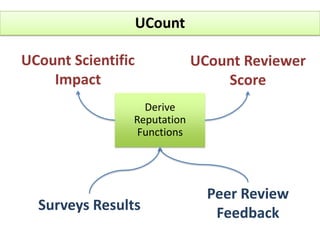

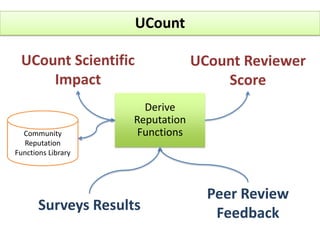




The document outlines a community-driven initiative called 'ucount' aimed at measuring scientific reputation through various methodologies, including surveys and bibliometric analysis. It discusses challenges in accurately capturing reputation and explores the development of reputation functions that integrate multiple features, emphasizing the need for improved decision-making support for researchers. The findings suggest that bibliometrics alone do not effectively describe actual reputation, prompting further exploration into machine learning techniques and reverse engineering approaches.
























































