2011/4/27 アルゴリズムとデータ構造 145
素朴なアルゴリズム
概要:
テキストとパタンを重ねて,一致するかどうか調べる
一致しなかったら,パタンを 1 つずつずらしていく
入力:テキスト文字列 text, パターン文字列 patn
出力:見つかった場所のインデックス,見つからなかったら -1
を返す
def simple_match(text, patn):
n = len(text); m = len(patn)
for i in range(n - m + 1):
for j in range(m):
if text[i + j] != patn[j]: break
if text[i + j] == patn[j]: return i
return -1
6.
2011/4/27 アルゴリズムとデータ構造 146
素朴なアルゴリズムの計算量
最悪計算量:
テキスト長さ N ,パタンの長さを M とすると, O(NM)
ただし,たいていの場合, 1 文字目で失敗するので実質的
には O(N)
最悪の場合の入力
”テキスト: aaaa...aaaa” (a が N 個 )
”パターン: aa...aab” (a が M-1 個, b が 1 個 )
どうやったら改良できるか?
M 文字目で不一致になった時点で,テキストの 1 ~ M-1
文字目までは a であったことがわかる.
パターンを 1 文字分右にずらして, M-1 文字目から照合す
ればよい
7.
2011/4/27 アルゴリズムとデータ構造 147
Knuth-Morris-Pratt 法( KMP 法)
パターンの照合に失敗したとき,それまで一致した
という事実を用いて,次に照合を開始する位置を決
める
文字が一致しなかったとき,一致した部分から先頭 1 文字
を削った文字列の Suffix( 接尾辞 ) とパターンの Prefix( 接
頭辞 ) で一致する最長のものをそろえる
a b c
a b c a b c
d
a b c d
d
a b c a b d
a b c a b c d
a b c a b d
一致 ×
×
Suffix
Prefix
Suffix
8.
2011/4/27 アルゴリズムとデータ構造 148
Knuth-Morris-Pratt 法( KMP 法)
a b c d a b d
a b c a b c d a b a b c d a b c d a b d e
a b c d a b d
a b c d a b d
a b c d a b d
a b c d a b d
不一致
a b c d a b d
a b c d a b d
9.
2011/4/27 アルゴリズムとデータ構造 149
Knuth-Morris-Pratt 法( KMP 法)
def kmp_match(text, patn):
next = kmp_init(patn)
i = 0
j = 0
while i + j < len(text):
if patn[j] == text[i+j]:
j = j + 1
if j == len(patn): return i
else:
i = i + j – next[j]
if j > 0: j = next[j]
return -1
10.
2011/4/27 アルゴリズムとデータ構造 1410
パターン照合テーブルの作成
def kmp_init(patn):
table = array(len(patn))
table[0] = -1
table[1] = 0
i = 2
j = 0
while i < len(patn):
if patn[i-1] == patn[j]:
table[i] = j+1; i = i + 1; j = j + 1
elif j > 0:
j = table[j]
else:
table[i] = 0; i = i + 1
return table
2011/4/27 アルゴリズムとデータ構造 1413
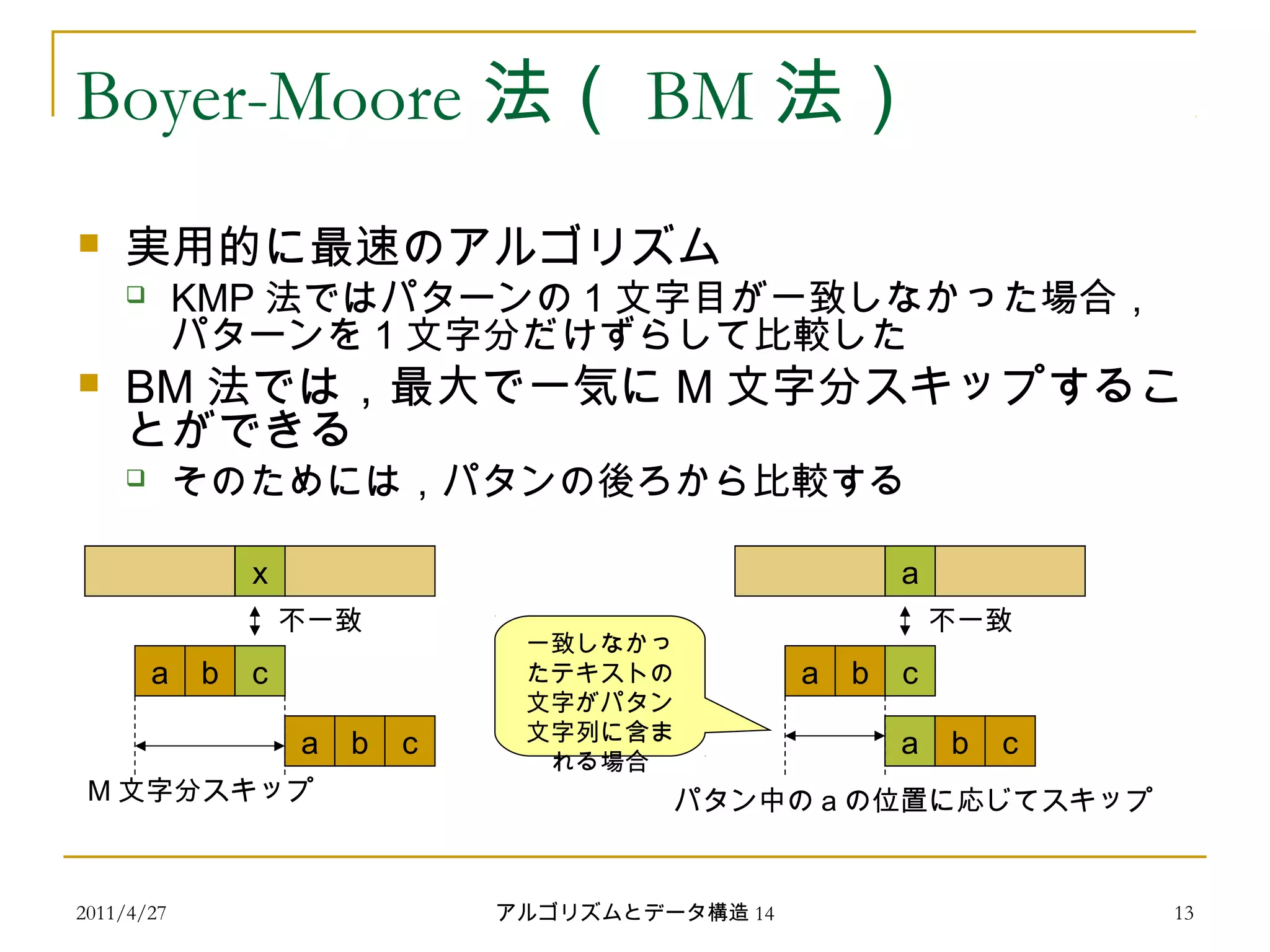
Boyer-Moore 法( BM 法)
実用的に最速のアルゴリズム
KMP 法ではパターンの 1 文字目が一致しなかった場合,
パターンを 1 文字分だけずらして比較した
BM 法では,最大で一気に M 文字分スキップするこ
とができる
そのためには,パタンの後ろから比較する
x
a b c
不一致
a b c
M 文字分スキップ
a
a b c
不一致
a b c
一致しなかっ
たテキストの
文字がパタン
文字列に含ま
れる場合
パタン中の a の位置に応じてスキップ
14.
2011/4/27 アルゴリズムとデータ構造 1414
途中まで一致していた場合
パターンを移動するのではなく,比較位置を移動する
パターンが左側に移動してしまう場合は,右に 1 文字分ずらす
z
不一致
a b c a b
a b
a b c a b
a bc
d
不一致
a b c d e
c d
a b c d e
e x
a b c d e
i i←i+skip
j
j←patn.length-1
j←patn.length-1
i←patn.length-j+1
i
15.
2011/4/27 アルゴリズムとデータ構造 1415
スキップ表の計算
def init_skip(patn):
skip = array(256)
for c in range(256):
skip[c] = len(patn)
for i in range(0, len(patn)-1):
skip[ord(patn[i])] = len(patn) - i - 1
return skip
パタン中に同じ文字が 2 回以上現れる場合,最後のものが優先され
る
”例:パタン never” の場合 c n e v r それ以外の文字
skip[c] 4 1 2 5 5
16.
2011/4/27 アルゴリズムとデータ構造 1416
BM 法の実現
def bm_match(text, patn):
skip = init_skip(patn)
i = len(patn) - 1
while i < len(text):
j = len(patn) - 1
while text[i] == patn[j]:
if j == 0: return i
i = i - 1; j = j - 1
i = i + max(skip[ord(text[i])],
len(patn) - j)
return -1




![2011/4/27 アルゴリズムとデータ構造 14 4
文字列探索
テキストから,パターンと呼ばれる文字列と一致す
る部分を調べる
Unix の grep コマンド
テキストの長さを n, パターンの長さを m とする
問題
以下を満たすようなインデックス pos を見つける
pattern[0] = text[pos]
pattern[1] = text[pos+1]
…
pattern[m-1] = text[pos + m – 1]
pos が2つ以上ある場合は,最も小さいものを返す
一般的に,テキストはパターン文字列よりずっと大
きい](https://image.slidesharecdn.com/14-170415111014/75/14-4-2048.jpg)
![2011/4/27 アルゴリズムとデータ構造 14 5
素朴なアルゴリズム
概要:
テキストとパタンを重ねて,一致するかどうか調べる
一致しなかったら,パタンを 1 つずつずらしていく
入力:テキスト文字列 text, パターン文字列 patn
出力:見つかった場所のインデックス,見つからなかったら -1
を返す
def simple_match(text, patn):
n = len(text); m = len(patn)
for i in range(n - m + 1):
for j in range(m):
if text[i + j] != patn[j]: break
if text[i + j] == patn[j]: return i
return -1](https://image.slidesharecdn.com/14-170415111014/75/14-5-2048.jpg)



![2011/4/27 アルゴリズムとデータ構造 14 9
Knuth-Morris-Pratt 法( KMP 法)
def kmp_match(text, patn):
next = kmp_init(patn)
i = 0
j = 0
while i + j < len(text):
if patn[j] == text[i+j]:
j = j + 1
if j == len(patn): return i
else:
i = i + j – next[j]
if j > 0: j = next[j]
return -1](https://image.slidesharecdn.com/14-170415111014/75/14-9-2048.jpg)
![2011/4/27 アルゴリズムとデータ構造 14 10
パターン照合テーブルの作成
def kmp_init(patn):
table = array(len(patn))
table[0] = -1
table[1] = 0
i = 2
j = 0
while i < len(patn):
if patn[i-1] == patn[j]:
table[i] = j+1; i = i + 1; j = j + 1
elif j > 0:
j = table[j]
else:
table[i] = 0; i = i + 1
return table](https://image.slidesharecdn.com/14-170415111014/75/14-10-2048.jpg)



![2011/4/27 アルゴリズムとデータ構造 14 15
スキップ表の計算
def init_skip(patn):
skip = array(256)
for c in range(256):
skip[c] = len(patn)
for i in range(0, len(patn)-1):
skip[ord(patn[i])] = len(patn) - i - 1
return skip
パタン中に同じ文字が 2 回以上現れる場合,最後のものが優先され
る
”例:パタン never” の場合 c n e v r それ以外の文字
skip[c] 4 1 2 5 5](https://image.slidesharecdn.com/14-170415111014/75/14-15-2048.jpg)
![2011/4/27 アルゴリズムとデータ構造 14 16
BM 法の実現
def bm_match(text, patn):
skip = init_skip(patn)
i = len(patn) - 1
while i < len(text):
j = len(patn) - 1
while text[i] == patn[j]:
if j == 0: return i
i = i - 1; j = j - 1
i = i + max(skip[ord(text[i])],
len(patn) - j)
return -1](https://image.slidesharecdn.com/14-170415111014/75/14-16-2048.jpg)







































![アルゴリズムのお勉強 アルゴリズムとデータ構造 [素数・文字列探索・簡単なソート]](https://cdn.slidesharecdn.com/ss_thumbnails/random-160606142552-thumbnail.jpg?width=640&height=640&fit=bounds)




























