Downloaded 42 times





![PHP: INSERT, UPDATE
define(‘SNO’,0); // номер space
$key = 12345
$tuple = array($key,‘spb’,’Hello Word’);
# если данные существуют, они замещаются
$res = $tnt->insert(SNO, $tuple);
$res = $tnt->delete(SNO, $key, [$flag]);
$data = array(1 => ’msk’, 2 => ‘Hello Hi++!’);
$res = $tnt->update(SNO, $key, $data);
# $key – всегда первичный ключ
# $data – асс. массив № поля => нов. значение](https://image.slidesharecdn.com/12redistarantool-111004013600-phpapp02/75/12-Redis-Tarantool-7-2048.jpg)
![PHP интерфейс: SELECT
$count = $tnt->select(SNO, $index, $key,[$limit,
$offset]);
# $key – ключ, возможен массив;
# $index – номер индекса, по которому
# осуществляется выборка;
# default $limit = 0хFFFFFFFF, $offset = 0;
# Возвращает количество найденных кортежей
# Выборка данных осуществляется методом
$tuple = $tnt->getTuple();](https://image.slidesharecdn.com/12redistarantool-111004013600-phpapp02/75/12-Redis-Tarantool-8-2048.jpg)


![Auto-increment: PHP
define(S_USER, 1); // номер space USER
define(INC_NO,1); // номер ключа счетчика
define(COUNTER,1); // номер поля счетчика
$key = $tnt->inc(SNO, INC_NO, COUNTER,
[1, true]);
$tnt->insert(NS_USER, $key, $data);](https://image.slidesharecdn.com/12redistarantool-111004013600-phpapp02/75/12-Redis-Tarantool-11-2048.jpg)
![Auto-increment: Lua
function box.auto_increment(spaceno, ...)
max_tuple = box.space[spaceno].index[0].idx:max()
if max_tuple ~= nil then
max = box.unpack('i', max_tuple[0])
else
max = -1
end
return box.insert(spaceno, max + 1, ...)
end
$tnt->call(SNO, “box.auto_increment”, $data);](https://image.slidesharecdn.com/12redistarantool-111004013600-phpapp02/75/12-Redis-Tarantool-12-2048.jpg)


![Pattern FIFO: Lua
function fifo_push(name, val)
fifo = find_or_create_fifo(name)
top = box.unpack('i', fifo[1])
bottom = box.unpack('i', fifo[2])
if top == fifomax+2 then -- % size
top = 3
…
end
return box.update(0, name, '=p=p=p', 1, top,
2, bottom, top, val)
end](https://image.slidesharecdn.com/12redistarantool-111004013600-phpapp02/75/12-Redis-Tarantool-15-2048.jpg)


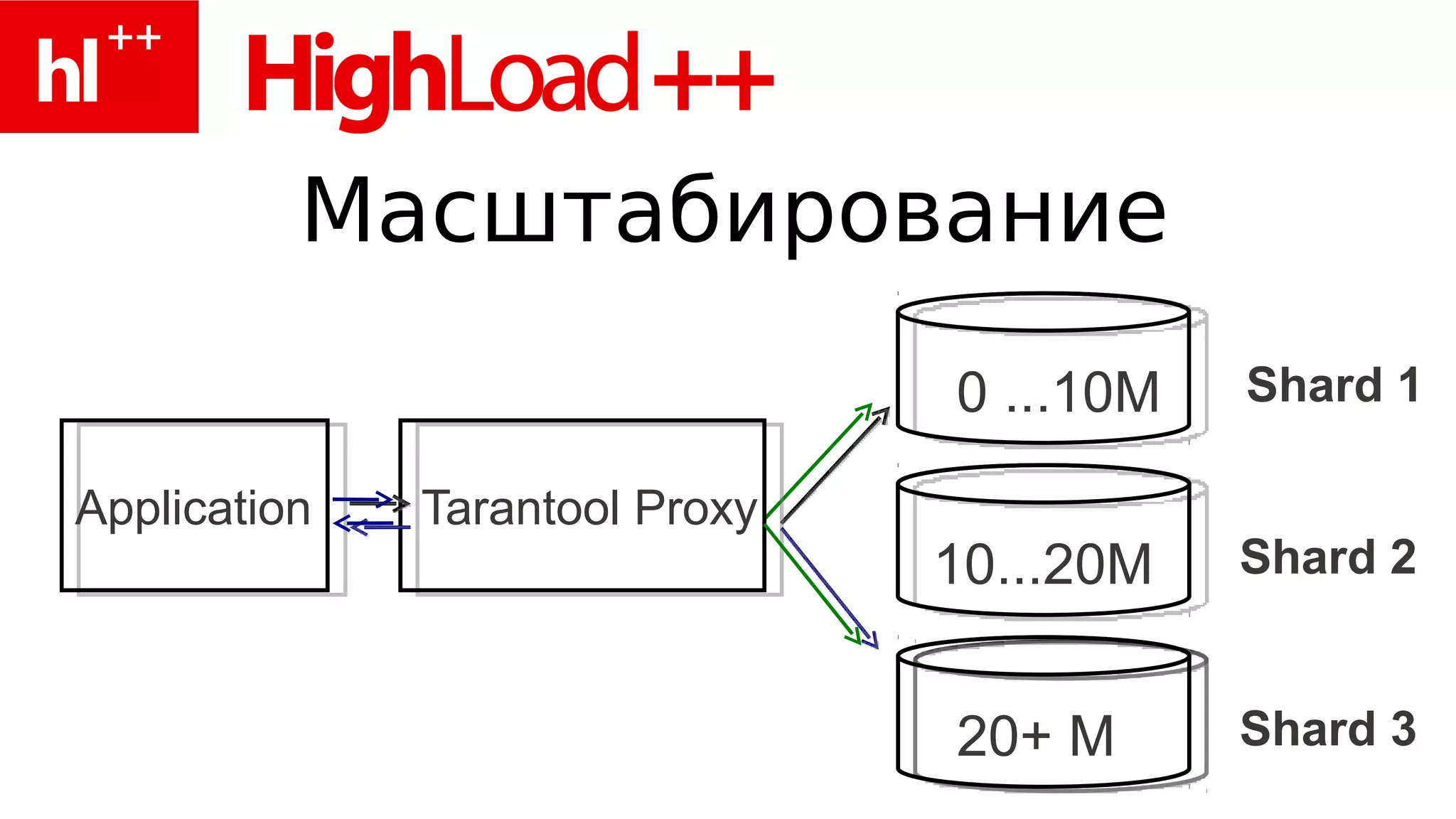

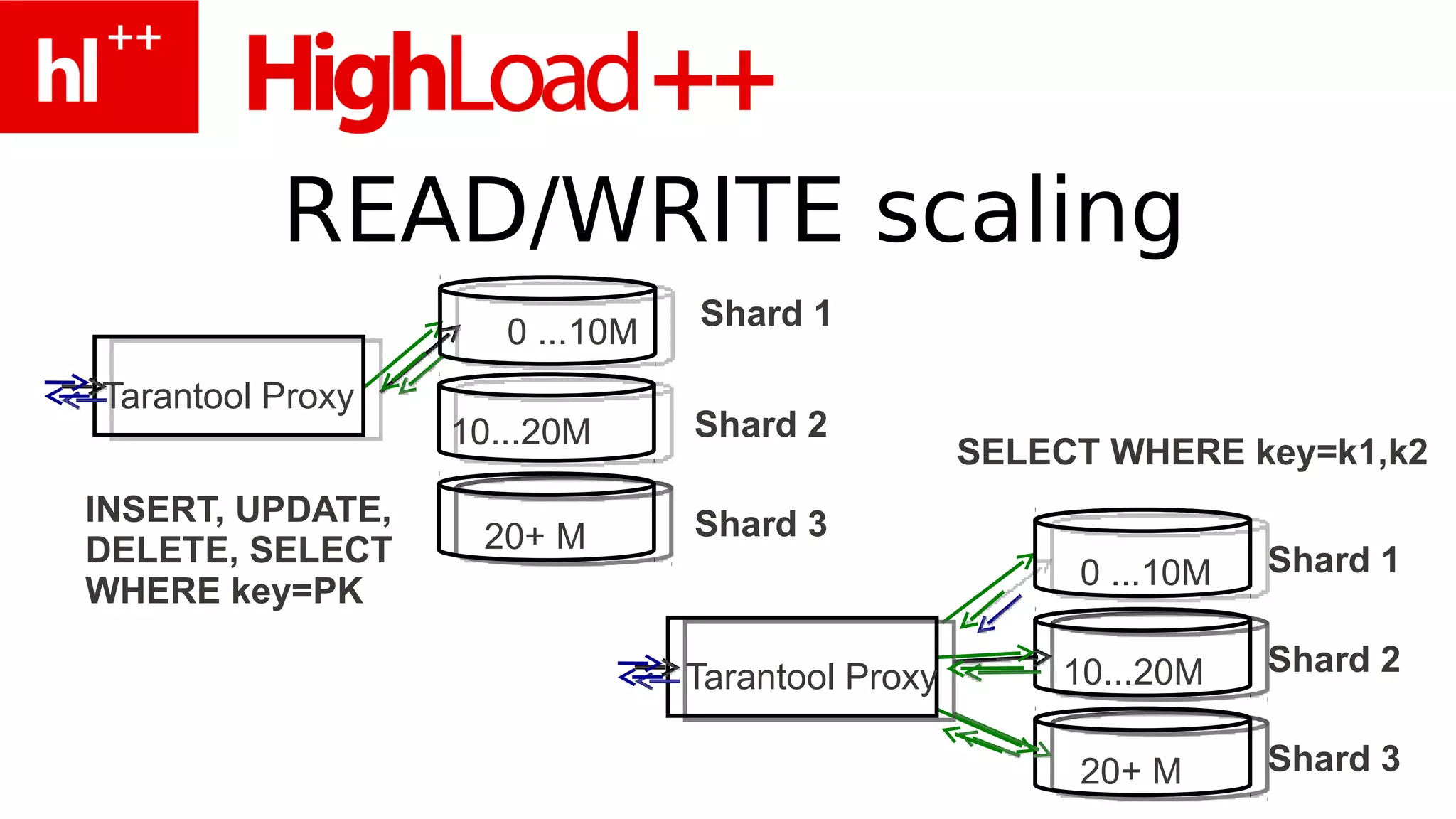




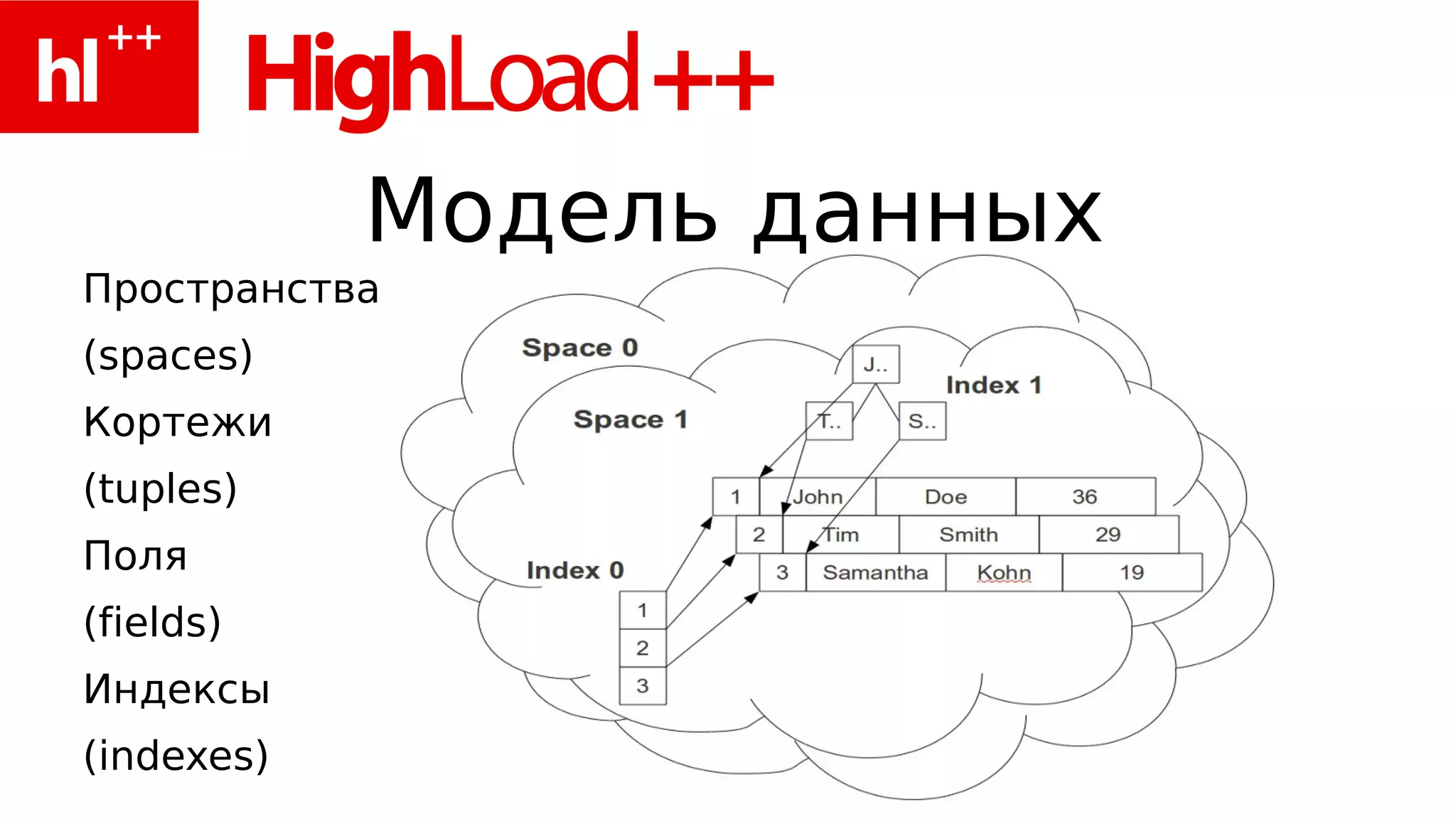
Документ представляет собой обзор работы с базой данных Tarantool, включая примеры использования Redis и функциональность Tarantool, такую как управление кортежами, индексы и операции обработки данных на PHP и Lua. Также рассматриваются паттерны проектирования, производительность, и возможность интеграции с другими языками. Упоминается архитектура многопоточного взаимодействия и планы по поддержке транзакций и репликации.










![Python AST / Николай Карелин / VPI Development Center [Python Meetup 27.03.15]](https://cdn.slidesharecdn.com/ss_thumbnails/2karelin-pythonast-150423014957-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
























































