Download as PDF, PPTX








![Nginx
POST http://host.com/api
BODY:
{
"id": 0,
"method": "squire"
"params": [5]
}
RESPONSE:
{
"result": 25
}](https://image.slidesharecdn.com/andreydrozdov-161128090125/85/rest-api-tarantool-12-320.jpg)
![Схемы Avro
{
"First": "John",
"Last": "Doe"
}
{
"name": "Person",
"type": "record",
"fields": [
{ "name": "First",
"type": "string" },
{ "name": "Last",
"type": "string" }
]
}
Хранится как: ["John", "Doe"]](https://image.slidesharecdn.com/andreydrozdov-161128090125/85/rest-api-tarantool-14-320.jpg)
![[
"John",
"Doe",
"Was here!"
]
{
"First": "John",
"Last": "Doe"
"Notes": "Was here!"
}
V2 V2
Versions](https://image.slidesharecdn.com/andreydrozdov-161128090125/85/rest-api-tarantool-15-320.jpg)
![[
"John",
"Doe",
"Was here!"
]
{
"First": "Jane",
"Last": "Doe"
}
V2 V1
Versions](https://image.slidesharecdn.com/andreydrozdov-161128090125/85/rest-api-tarantool-16-320.jpg)
![[
"Jane",
"Doe"
]
{
"First": "Jane",
"Last": "Doe"
"Notes": ""
}
V1 V2
Versions](https://image.slidesharecdn.com/andreydrozdov-161128090125/85/rest-api-tarantool-17-320.jpg)







![Пример конфигурации
{
"memory": 30,
"port": 3301,
"index": [
"user":["uid"],
"device":["uid", "sno"]
],
"relations": {
"user": ["device"]
}
"api": {
"v1": {
"user":{},
"device":{}
]
}
}](https://image.slidesharecdn.com/andreydrozdov-161128090125/85/rest-api-tarantool-31-320.jpg)


![Join
{
"uid": 1,
"First": «John",
"Last": «Doe"
"device": [
{
"uid": 1,
"sno": 1,
"name":"myD",
}
]
}](https://image.slidesharecdn.com/andreydrozdov-161128090125/85/rest-api-tarantool-34-320.jpg)
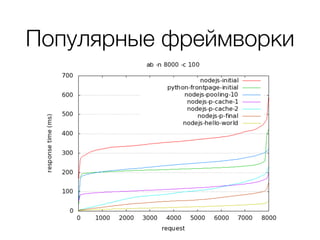

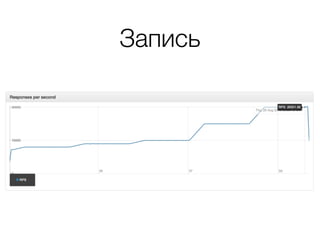
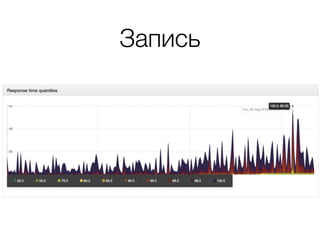
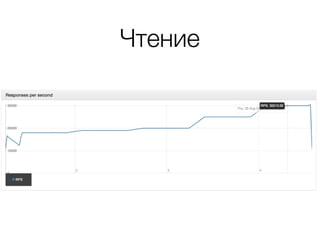
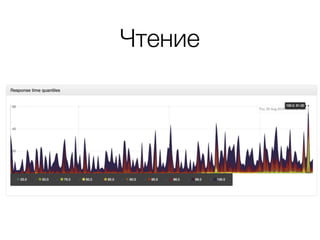




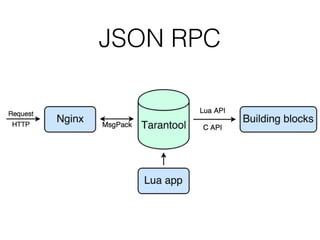
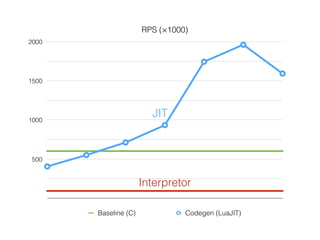
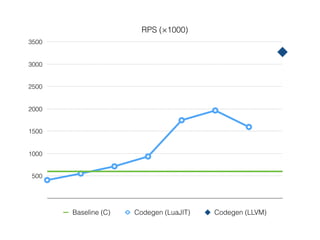
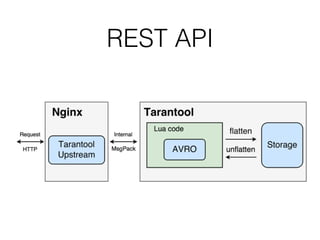
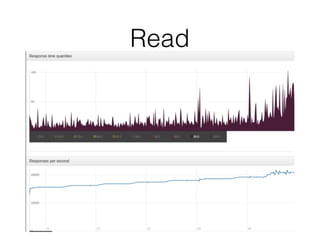
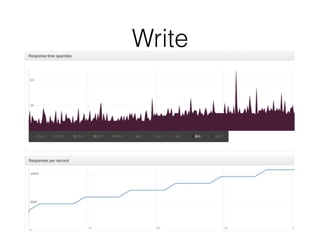
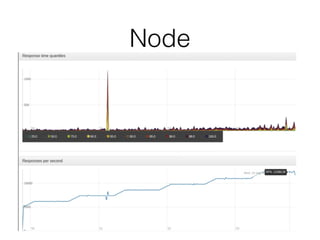
Документ описывает возможности и применение Tarantool в 2016 году, включая интеграцию с Nginx, создание REST API на чистой СУБД, а также производительность и опыт использования в продакшене. Приведены примеры конфигураций, использования Avro схем, распределенного хранения и управления версиями запросов. Упоминаются различные архитектурные решения, производительность и потенциальные подводные камни при разработке.














































































