Download as PDF, PPTX






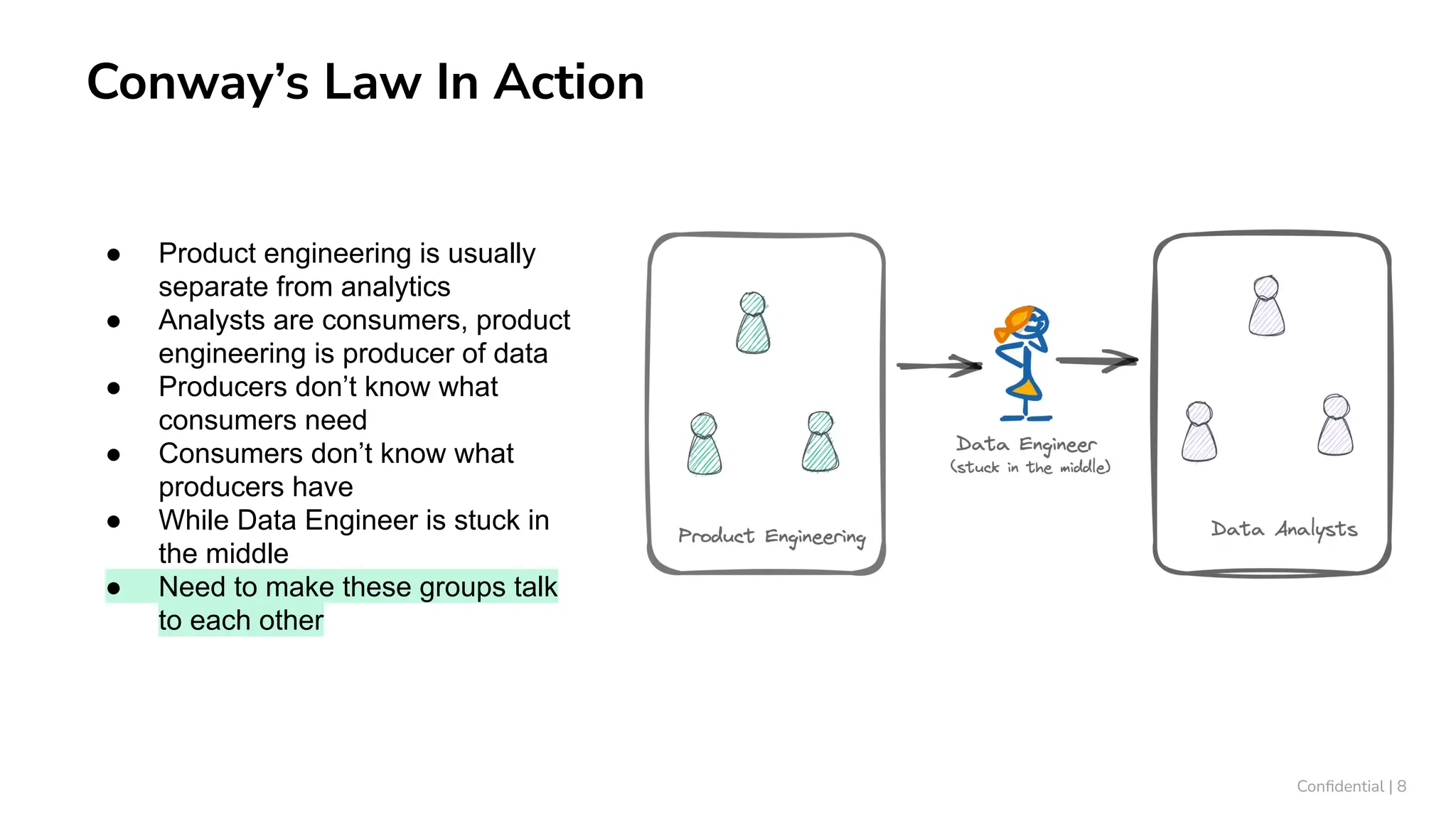



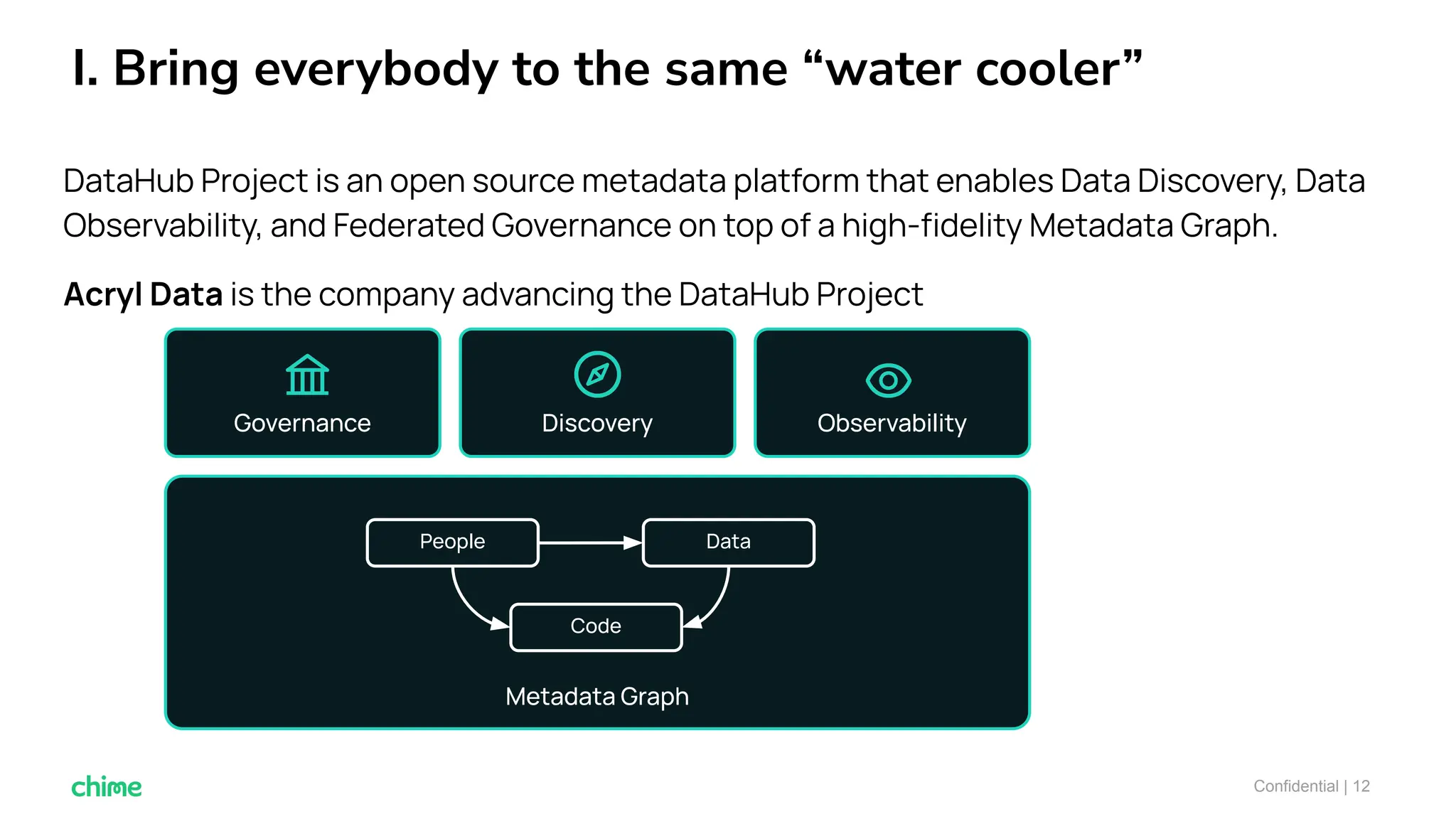
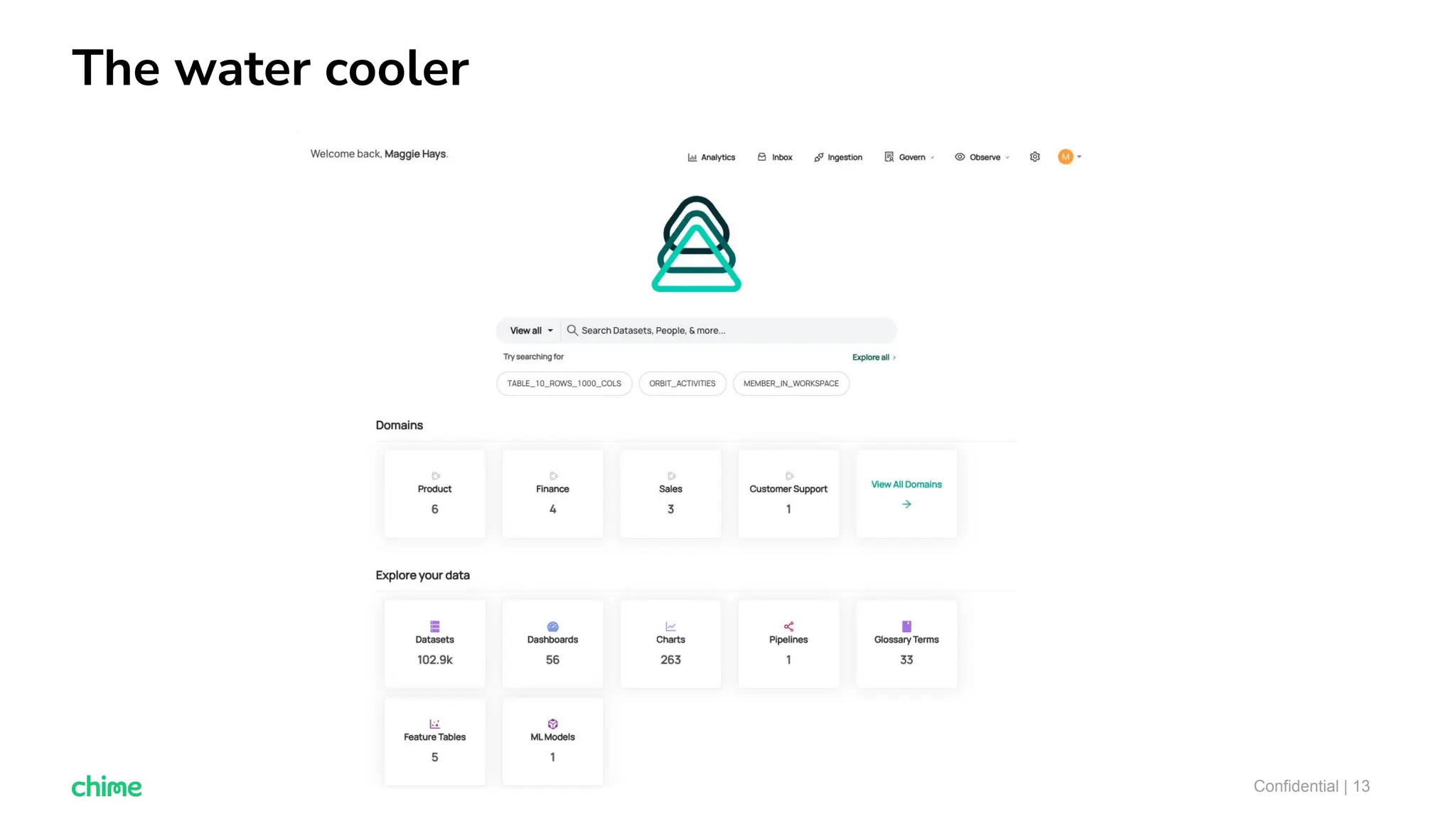
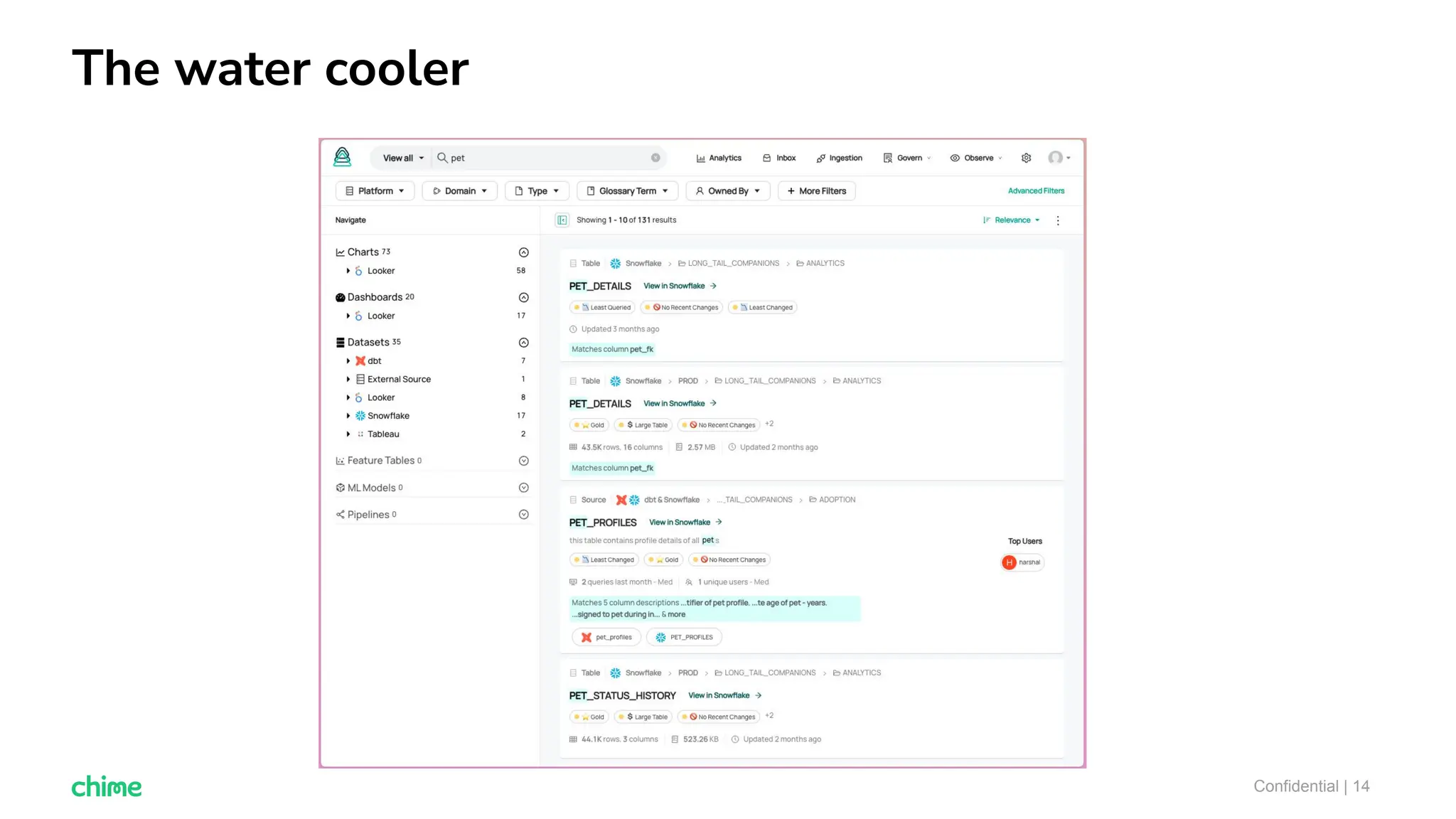
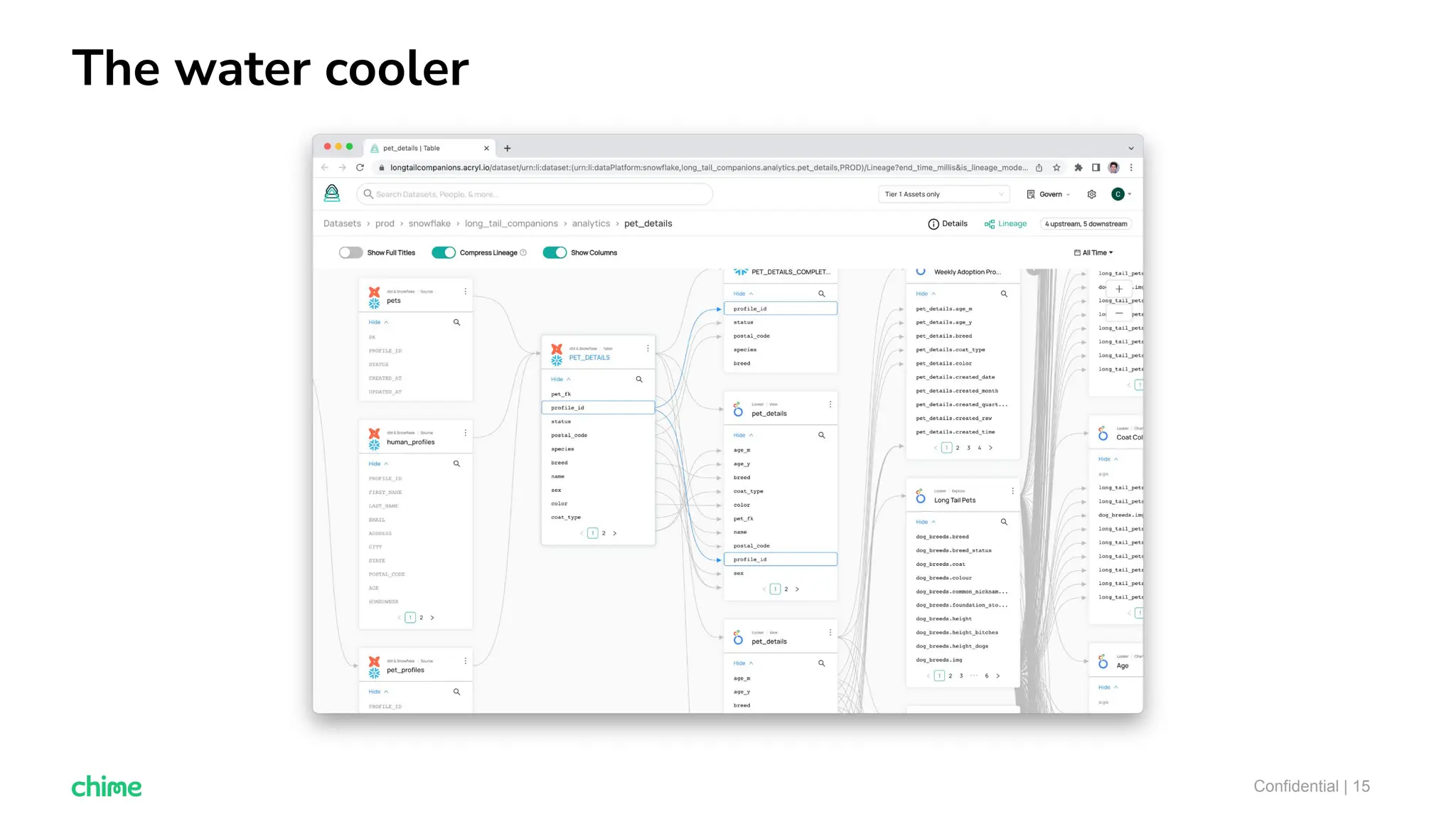



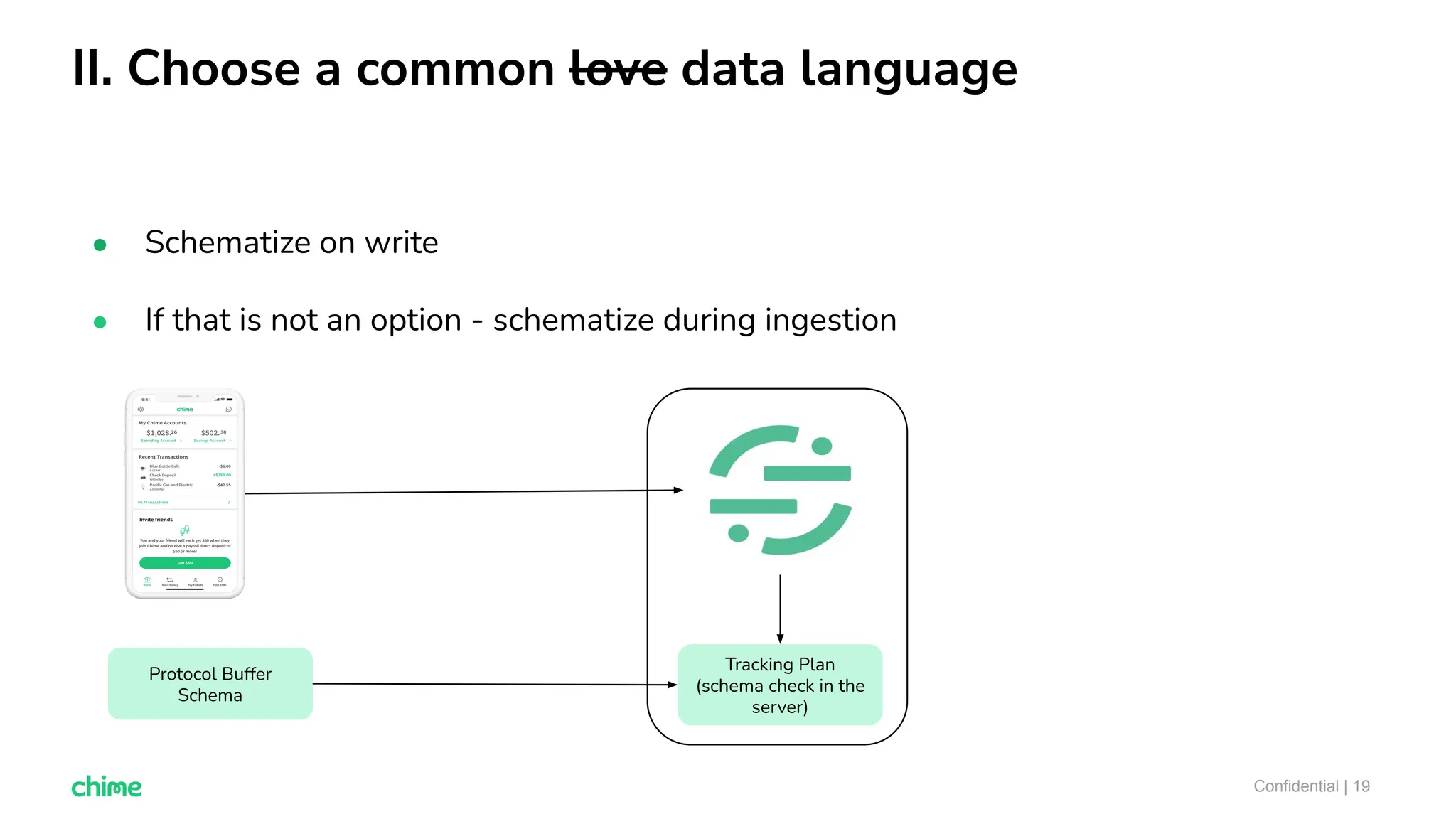




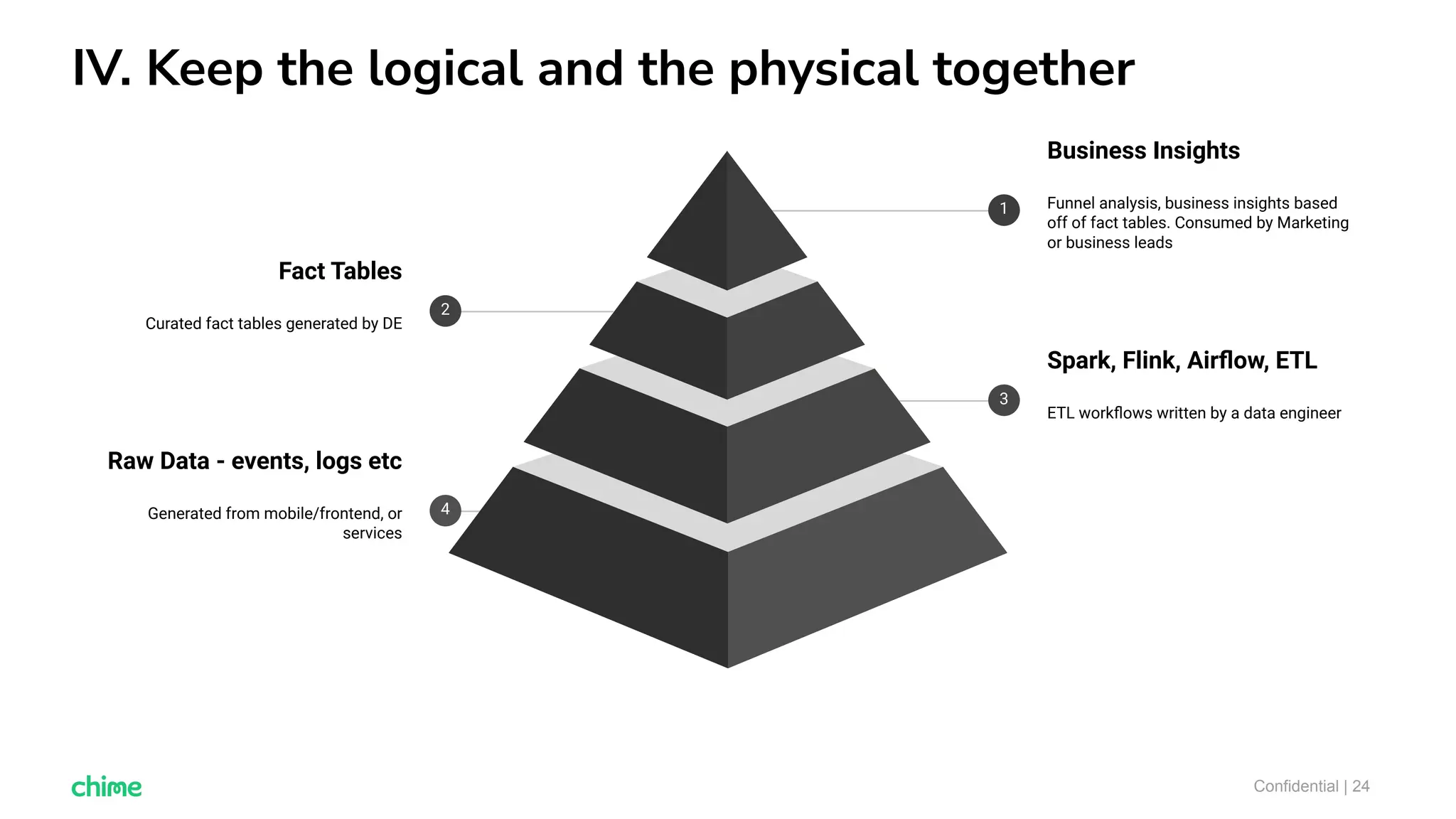
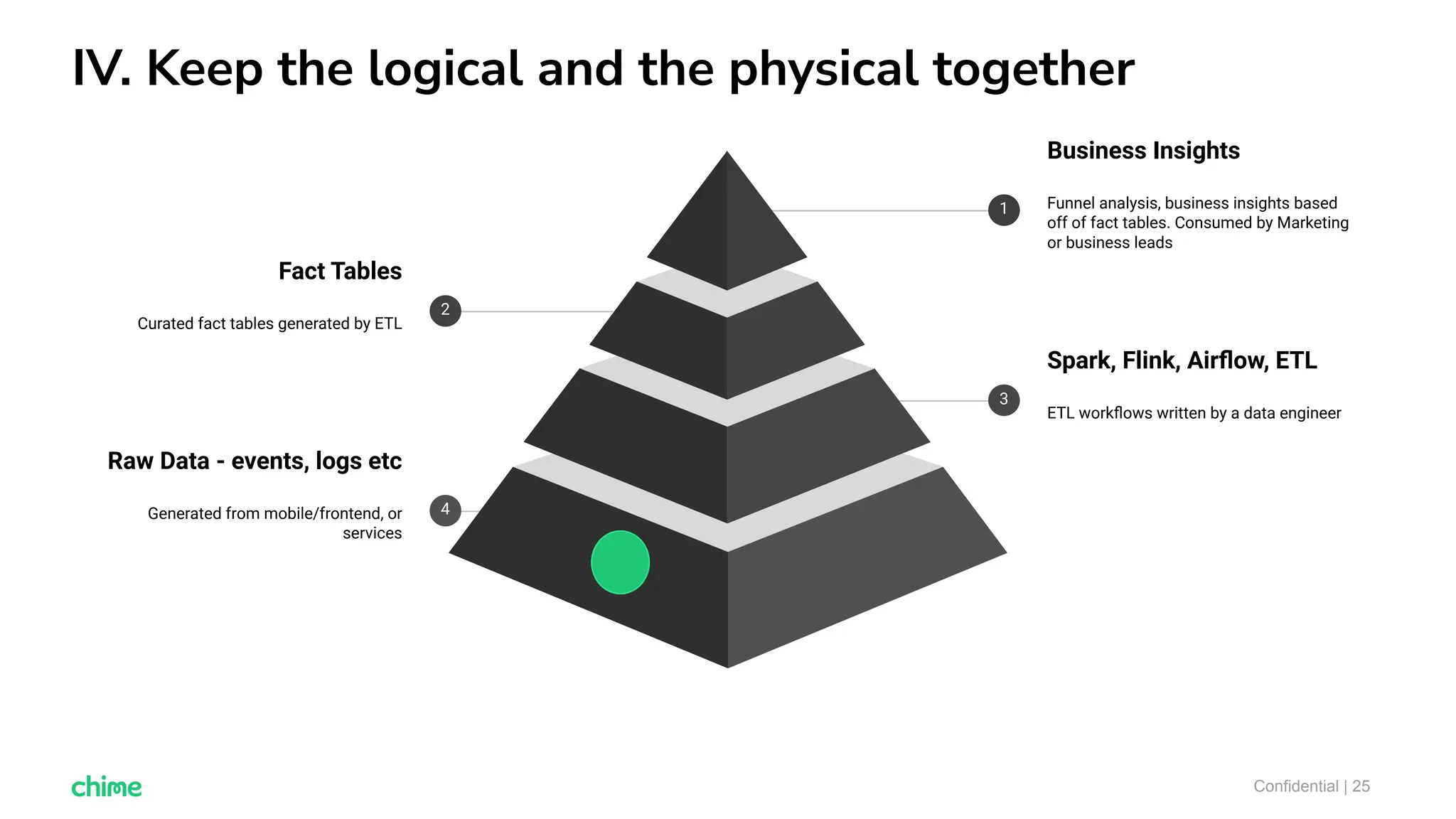
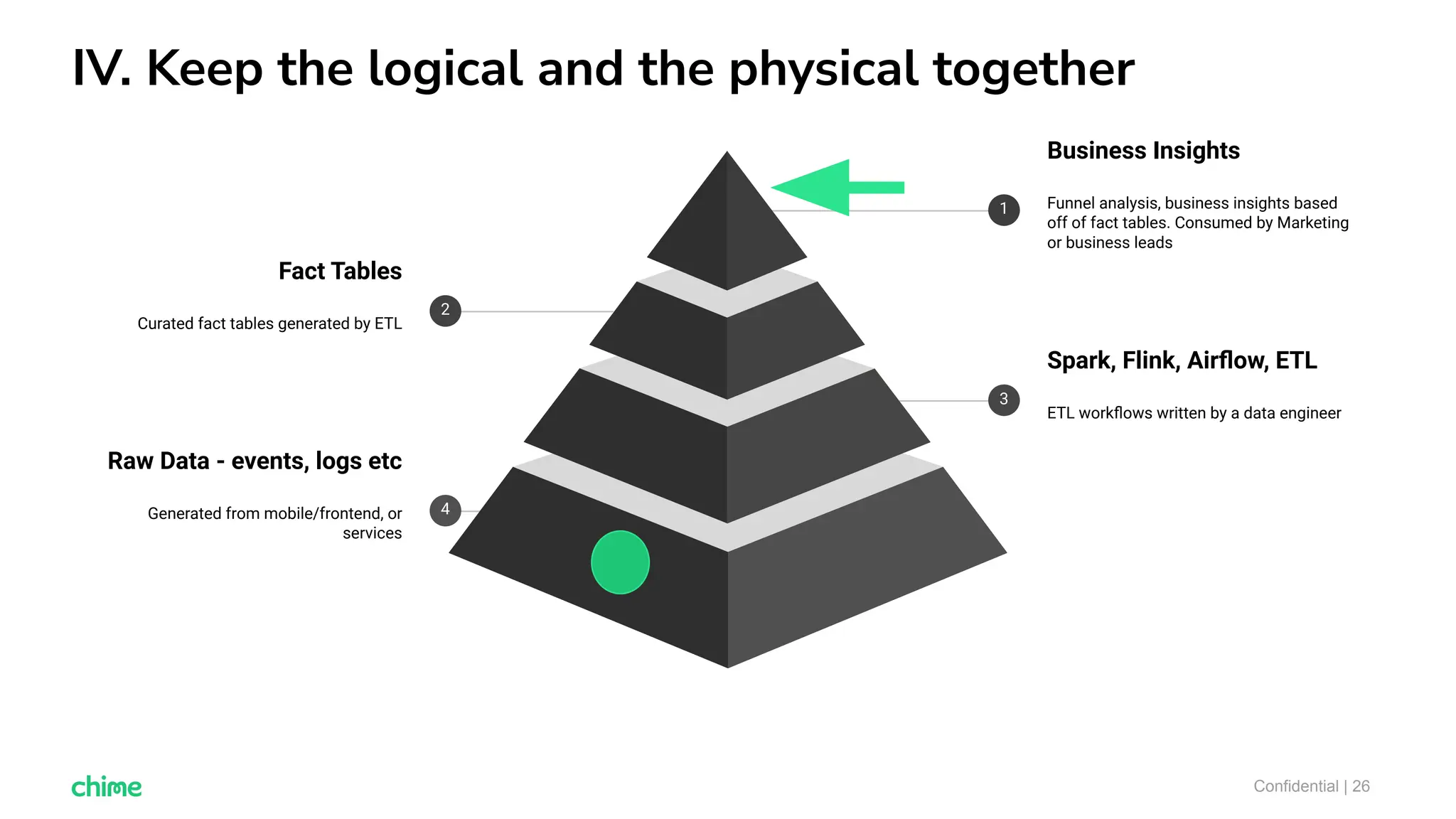

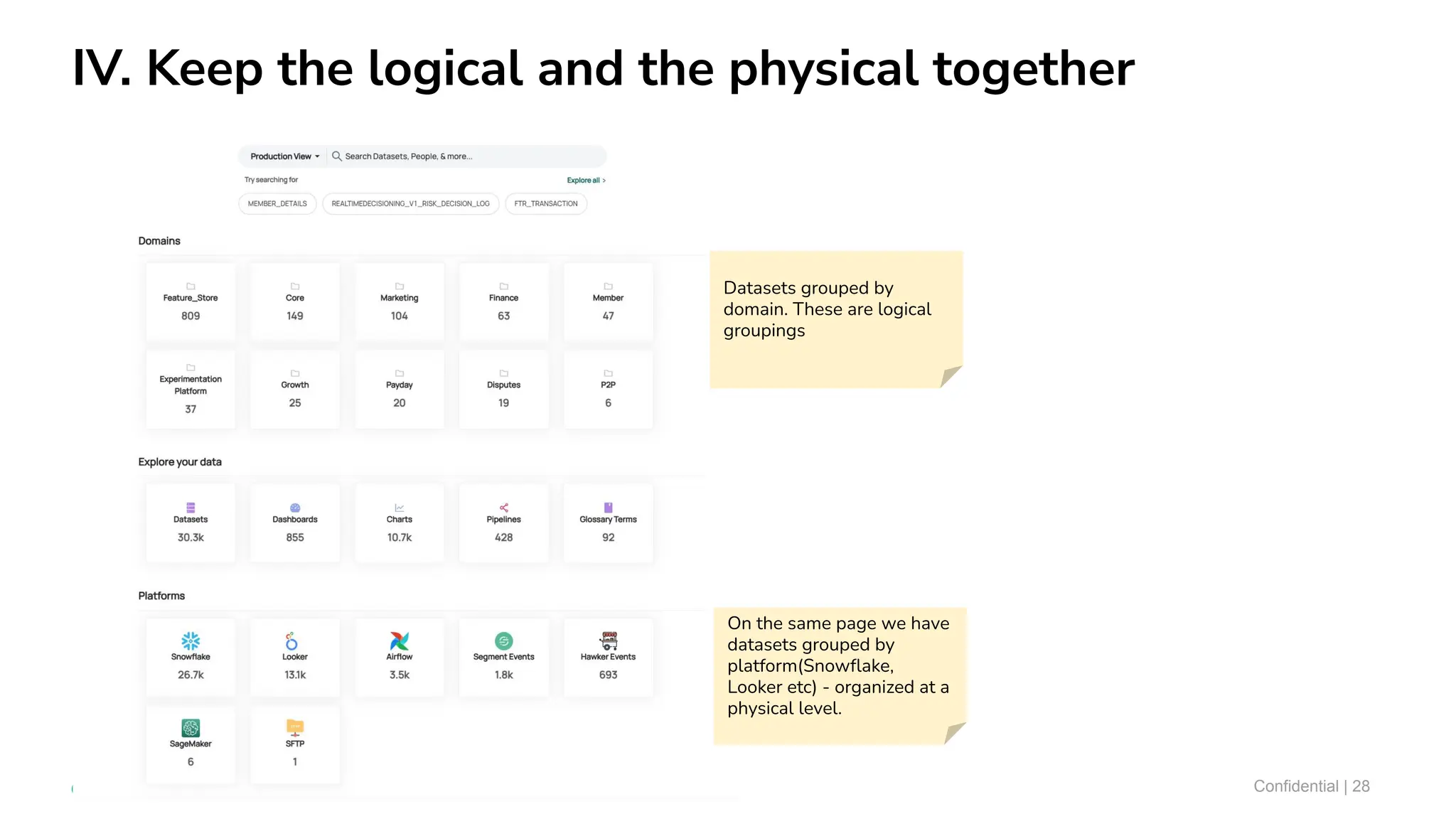




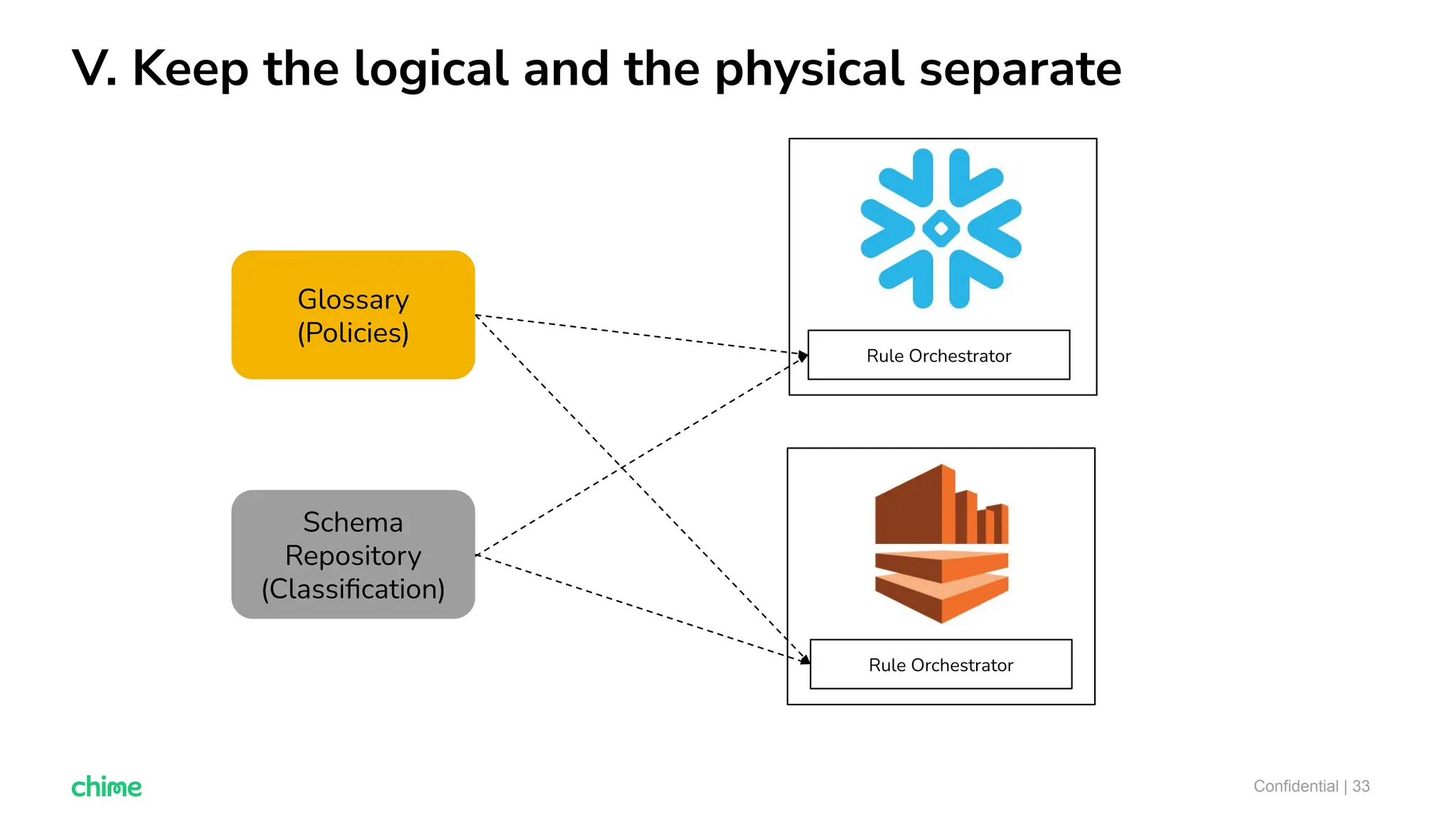

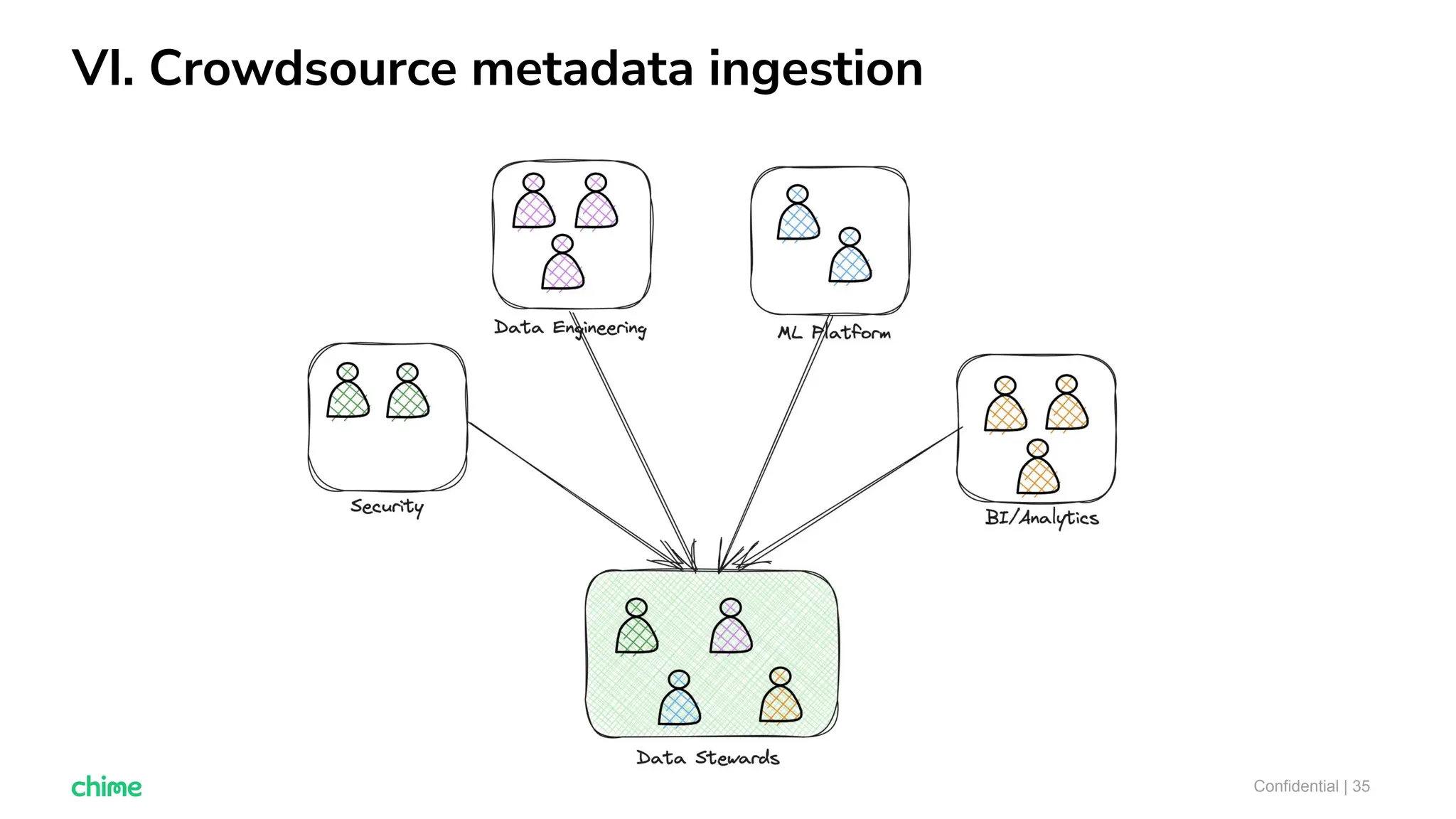

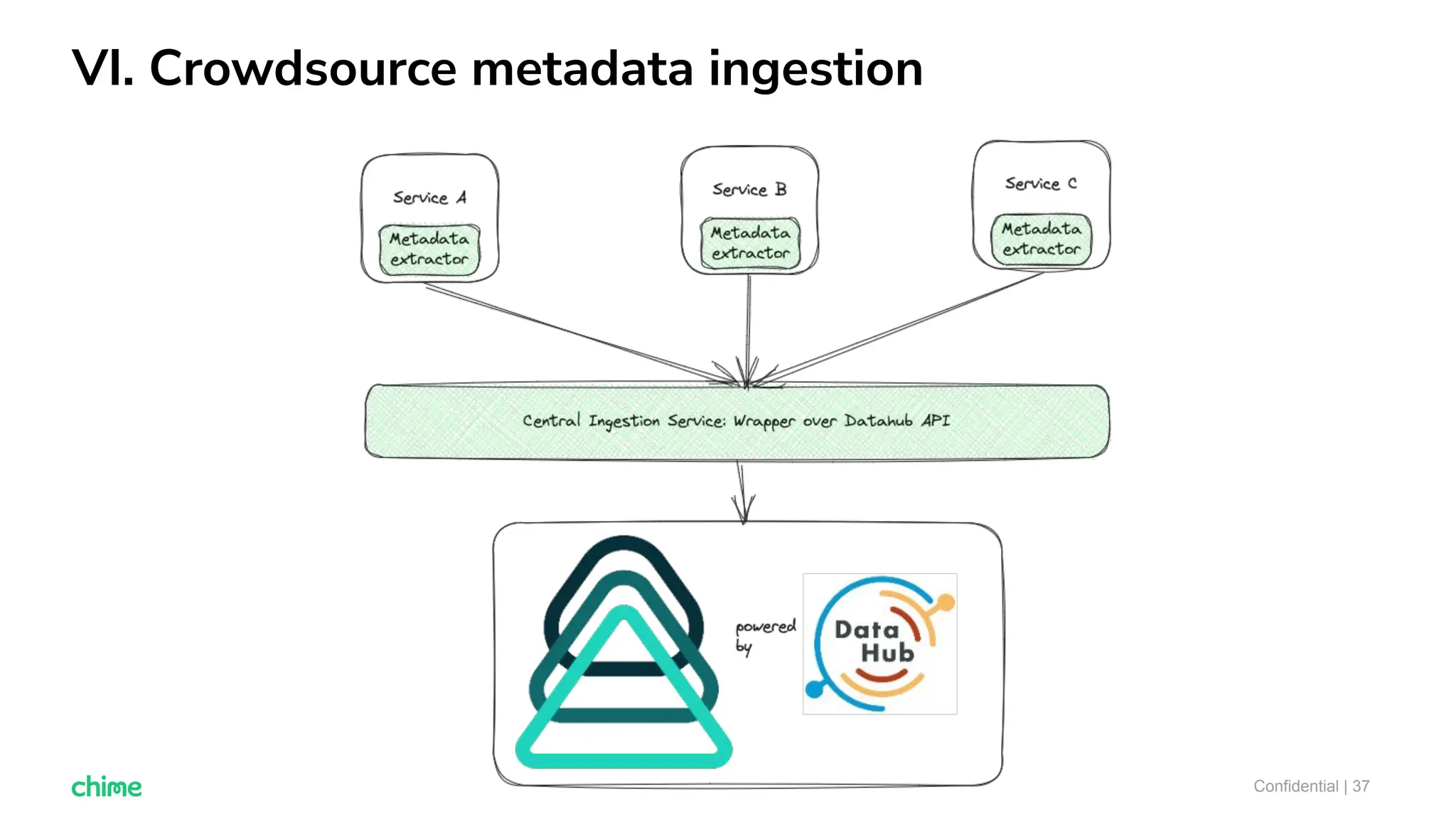



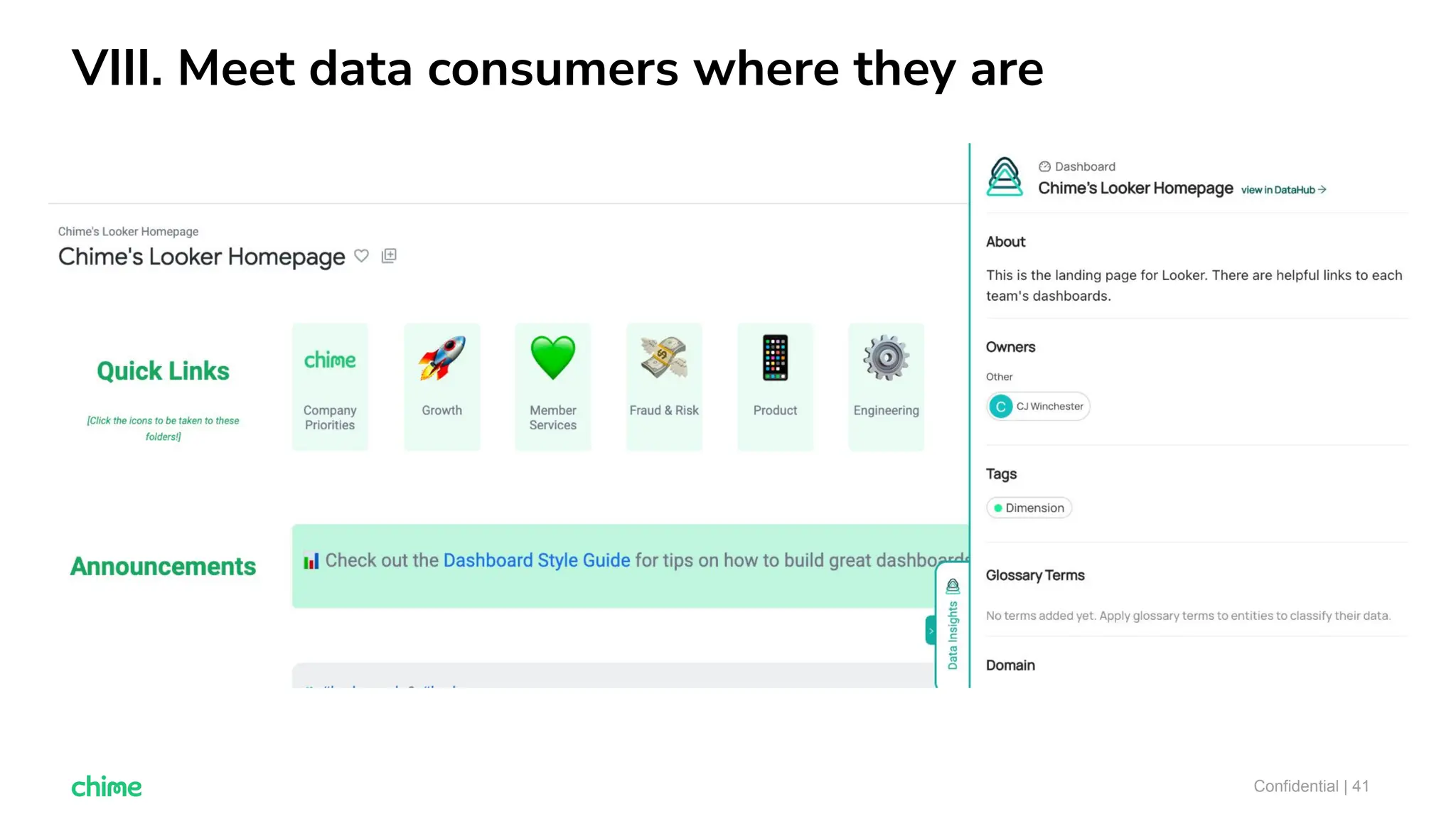

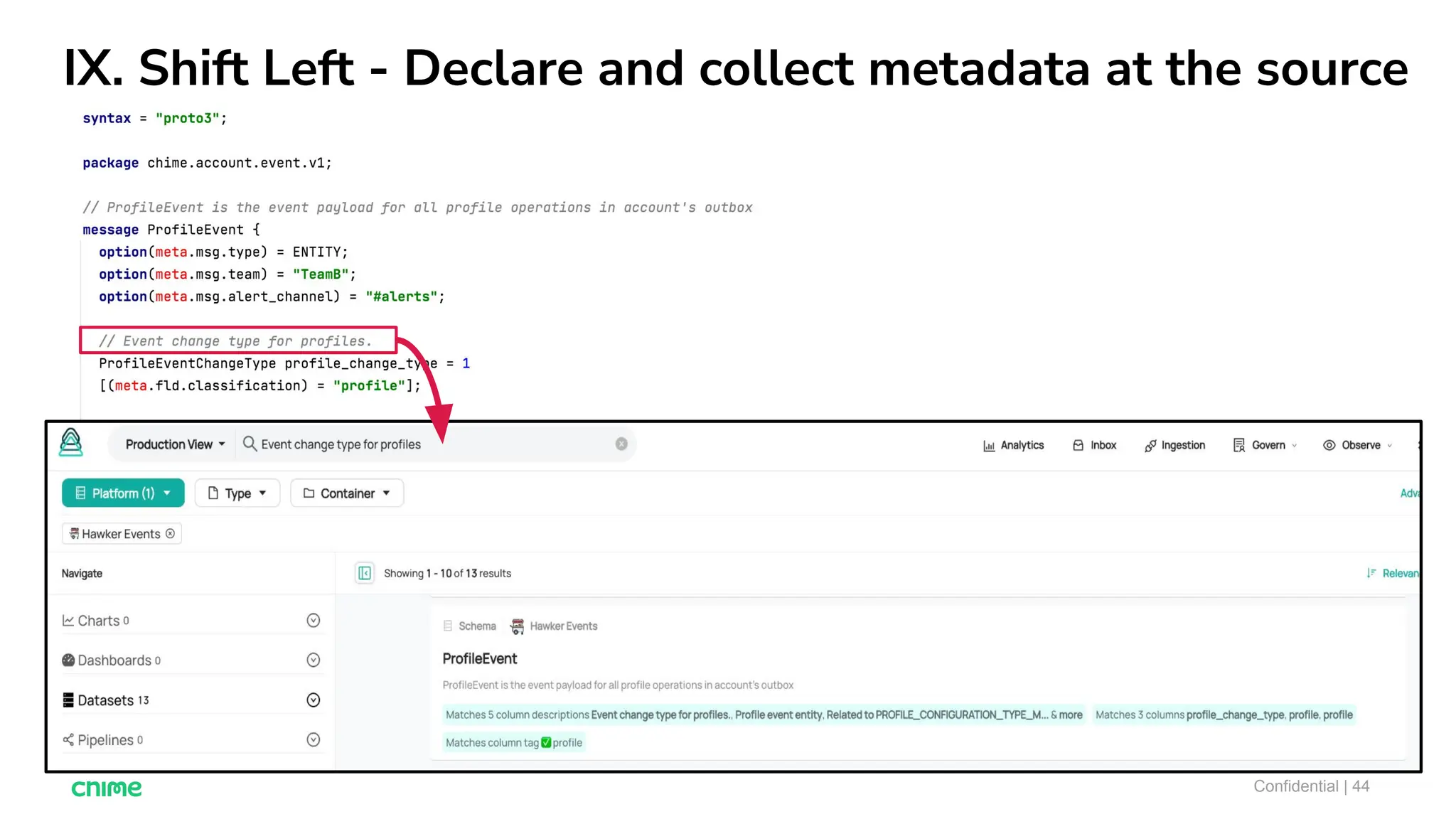

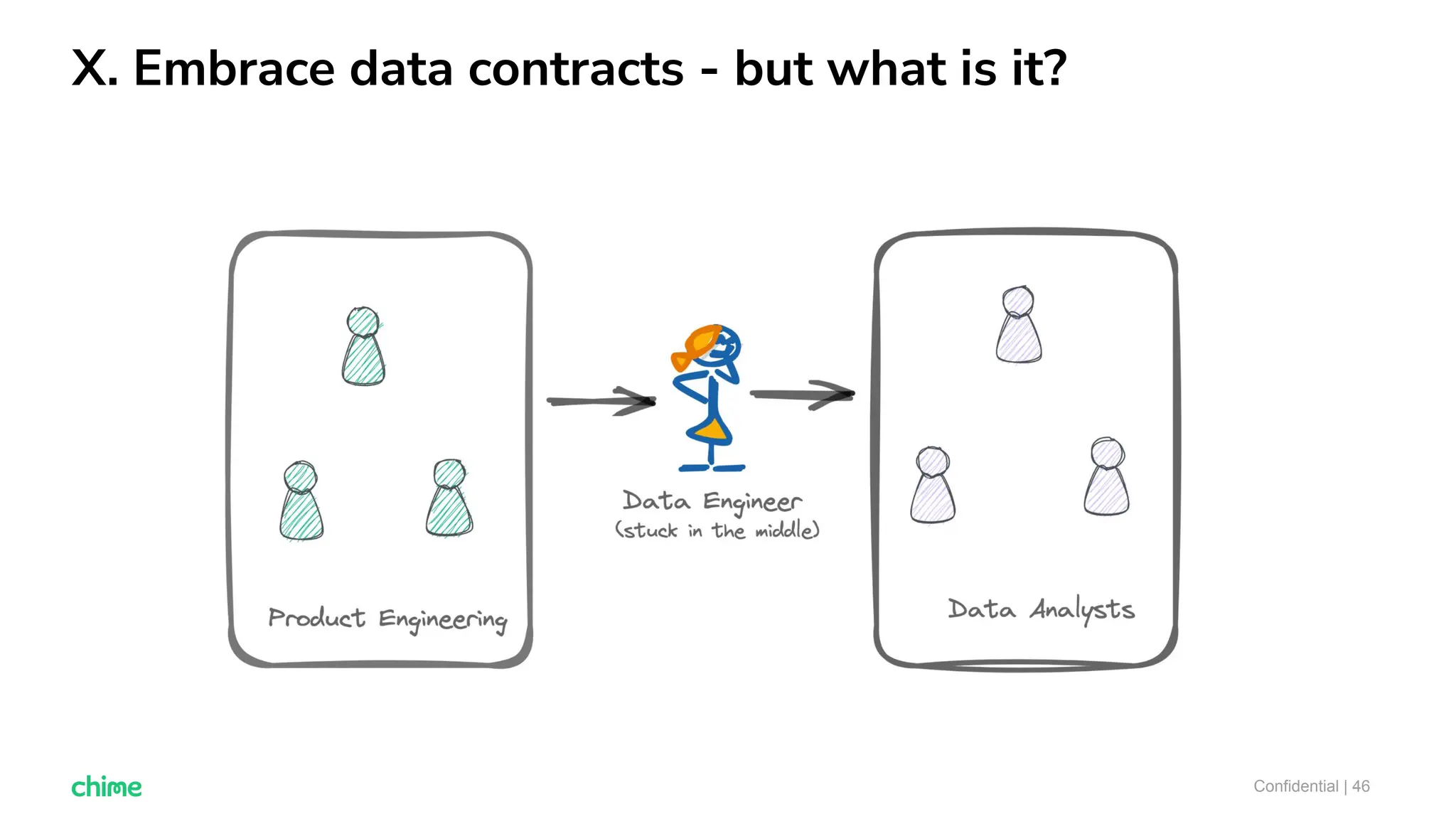







The document outlines ten tips for enhancing data discovery and governance, emphasizing collaboration among data producers and consumers, the use of a unified data catalog, and the importance of schema management. It advocates for assigning ownership, crowdsourcing metadata ingestion, and embracing data contracts to improve accountability and efficiency. Key strategies include maintaining a common data language and ensuring all stakeholders communicate effectively at a centralized point.





























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)




