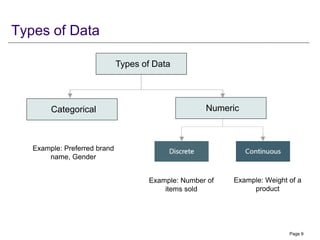
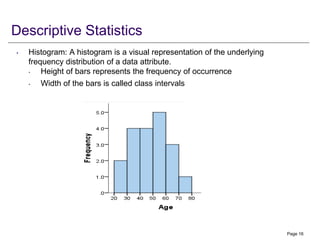
The document outlines statistical methods for decision-making, covering topics such as sampling, descriptive statistics, probability basics, and hypothesis testing. Key elements discussed include types of data, measures of central tendency and dispersion, as well as advanced concepts like covariance and coefficient of correlation. Overall, it serves as a comprehensive guide for understanding and applying statistical techniques in various contexts.