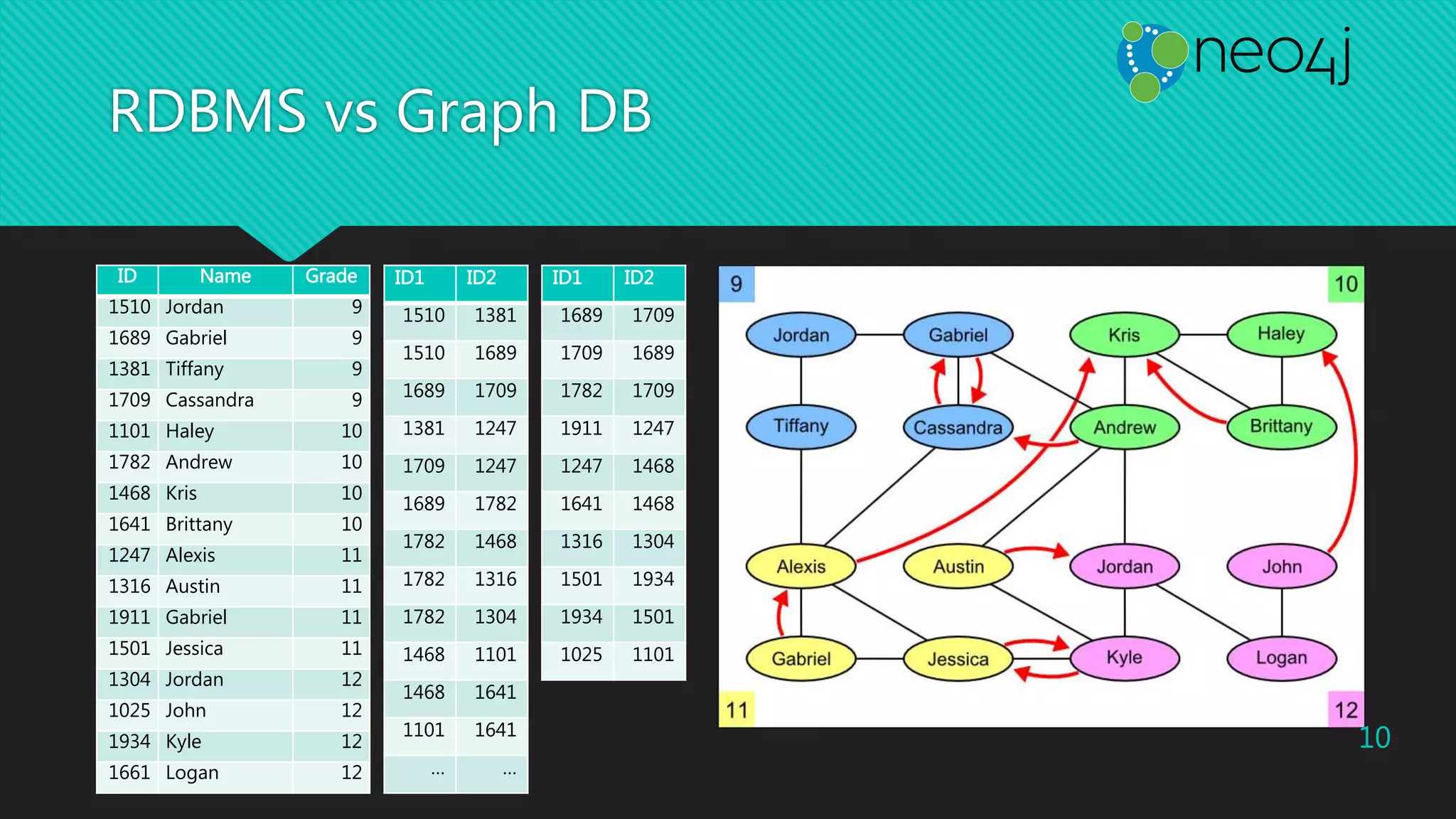
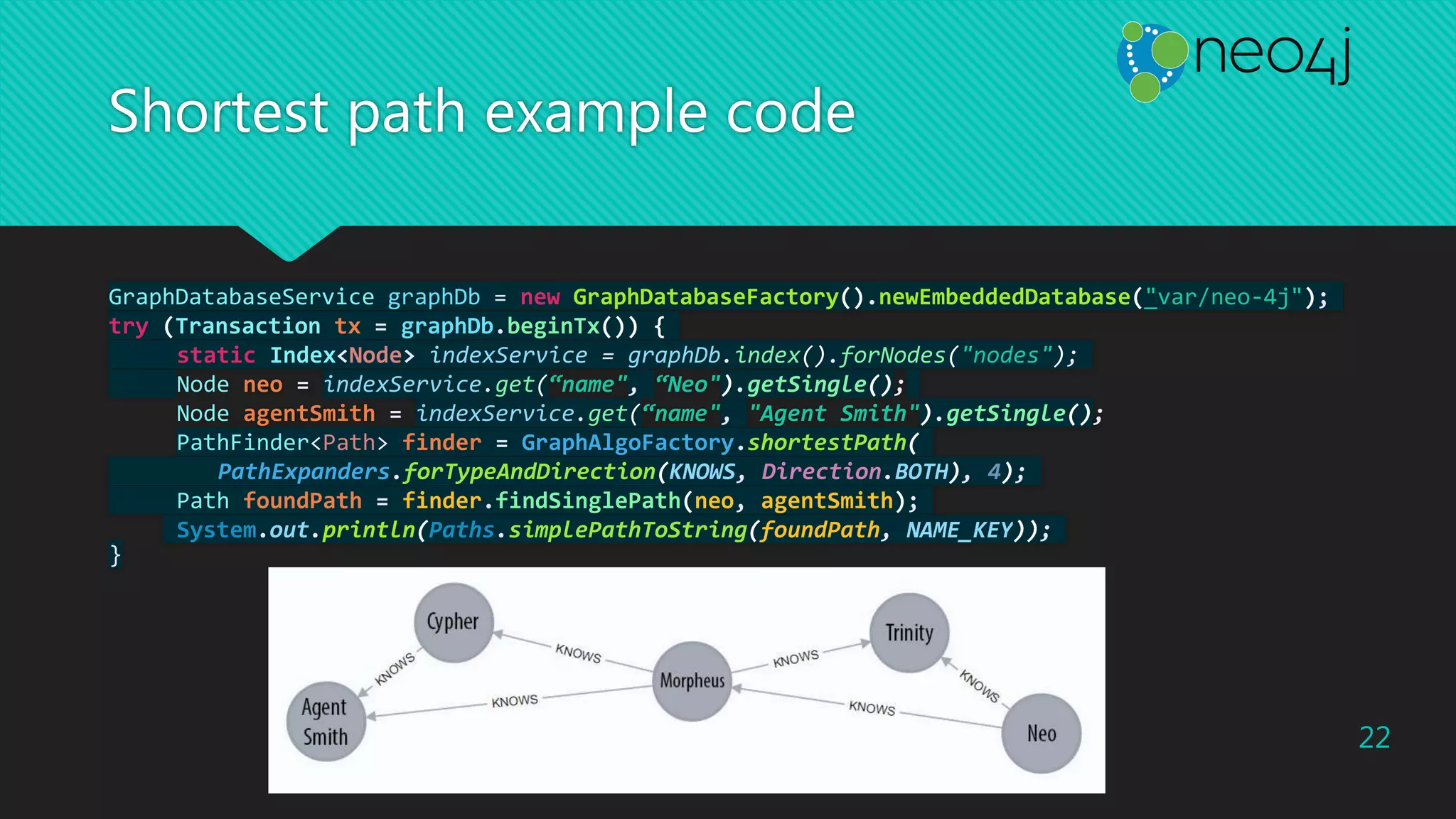
This document provides an overview of Neo4j, a graph database, and the Cypher query language. It discusses how graphs are useful for modeling connected data and provides examples showing Neo4j outperforming a relational database for social network queries. It also summarizes key aspects of the Cypher language, including MATCH, WHERE, CREATE, DELETE clauses and functions. Code examples are given for embedded Neo4j usage and shortest path queries.







![CQL MATCH
MATCH (a)-->(b)
RETURN a, b;
MATCH (a)-->()
RETURN a.name;
MATCH (n)-[r]->(m)
RETURN n, r, m;
MATCH (a)-[r]->()
RETURN id(a), labels(a), keys(a), type(r);
MATCH (a)-[r:ACTED_IN]->(m)
RETURN a.name, r.roles, m.title;
12](https://image.slidesharecdn.com/490d3cfa-7342-4e8c-b4a7-1c4ff02229d0-160726075922/75/Neo4j-12-2048.jpg)
![CQL MATCH
MATCH (a)-[:ACTED_IN]->(m)<-[:DIRECTED]-(d)
RETURN a.name, m.title, d.name;
MATCH (a)-[:ACTED_IN]->(m)<-[:DIRECTED]-(d)
RETURN a.name AS actor, m.title AS movie, d.name AS director;
MATCH (a)-[:ACTED_IN]->(m)
OPTIONAL MATCH (d)-[:DIRECTED]->(m)
RETURN a.name, m.title, d.name;
MATCH (a)-[:ACTED_IN]->(m), (d)-[:DIRECTED]->(m)
RETURN a.name, m.title, d.name;
MATCH p=(a)-[:ACTED_IN]->(m)<-[:DIRECTED]-(d)
RETURN nodes(p);
13](https://image.slidesharecdn.com/490d3cfa-7342-4e8c-b4a7-1c4ff02229d0-160726075922/75/Neo4j-13-2048.jpg)

![CQL WHERE
MATCH (tom{name:"Tom Hanks"})-[:ACTED_IN]->(movie)
WHERE movie.released < 1992
RETURN DISTINCT movie.title;
MATCH (actor{name:"Keanu Reeves"})-[r:ACTED_IN]->(movie)
WHERE "Neo" IN r.roles
RETURN DISTINCT movie.title;
MATCH (tom{name:"Tom Hanks"})-[:ACTED_IN]->(movie)<-[:ACTED_IN]-(a)
WHERE a.born < tom.born
RETURN DISTINCT a.name, (tom.born - a.born) AS diff;
MATCH (kevin {name:"Kevin Bacon"})-[:ACTED_IN]->(movie)
RETURN DISTINCT movie.title;
MATCH (kevin)-[:ACTED_IN]->(movie)
WHERE kevin.name =~ '.*Kevin.*‘ // Regular expressions
RETURN DISTINCT movie.title;
15](https://image.slidesharecdn.com/490d3cfa-7342-4e8c-b4a7-1c4ff02229d0-160726075922/75/Neo4j-15-2048.jpg)
![CQL WHERE
MATCH (gene {name:"Gene Hackman"})-[:ACTED_IN]->(movie)<-[:ACTED_IN]-(n)
WHERE (n)-[:DIRECTED]->()
RETURN DISTINCT n.name;
MATCH (a)-[:ACTED_IN]->()
RETURN a.name, count(*) AS count
ORDER BY count DESC LIMIT 5;
MATCH (keanu {name:"Keanu Reeves"})-[:ACTED_IN]->()<-[:ACTED_IN]-(c),
(c)-[:ACTED_IN]->()<-[:ACTED_IN]-(coc)
WHERE NOT((keanu)-[:ACTED_IN]->()<-[:ACTED_IN]-(coc)) AND coc <> keanu
RETURN coc.name, count(coc)
ORDER BY count(coc) DESC LIMIT 3;
// Recommend 5 actors that Keanu Reeves should work with (but hasn't)
16](https://image.slidesharecdn.com/490d3cfa-7342-4e8c-b4a7-1c4ff02229d0-160726075922/75/Neo4j-16-2048.jpg)
![CQL CREATE
CREATE ({title:"Mystic River", released:1993});
MATCH (movie {title:"Mystic River"})
SET movie.tagline = "We bury our sins here, Dave. We wash them clean."
RETURN movie;
MATCH (kevin {name:"Kevin Bacon"}),(movie {title:"Mystic River"})
CREATE UNIQUE (kevin)-[:ACTED_IN {roles:["Sean"]}]->(movie);
MATCH (kevin {name:"Kevin Bacon"})-[r:ACTED_IN]->(movie {title:"Mystic River"})
SET r.roles = ["Sean Devine"]
RETURN r.roles;
MATCH (clint {name:"Clint Eastwood"})-[r:ACTED_IN]->(movie {title:"Mystic River"})
CREATE UNIQUE (clint)-[:DIRECTED]->(movie);
17](https://image.slidesharecdn.com/490d3cfa-7342-4e8c-b4a7-1c4ff02229d0-160726075922/75/Neo4j-17-2048.jpg)
![CQL DELETE
MATCH (matrix {title:"The Matrix"})<-[r:ACTED_IN]-(a)
WHERE "Emil" IN r.roles
RETURN a;
// Emil Eifrem is CEO of Neo Technology and co-founder of the Neo4j project
MATCH (emil{name:"Emil Eifrem"})
DELETE emil;
MATCH (emil{name:"Emil Eifrem"}) -[r]-()
DELETE r;
MATCH (emil{name:"Emil Eifrem"}) -[r]-()
DELETE r, emil;
MATCH (node) where ID(node)=1
OPTIONAL MATCH (node)-[r]-()
DELETE r, node;
18](https://image.slidesharecdn.com/490d3cfa-7342-4e8c-b4a7-1c4ff02229d0-160726075922/75/Neo4j-18-2048.jpg)
![SQL VS Cypher
MATCH (keanu:Person { name: 'Keanu Reeves' })-[:ACTED_IN]->(movie:Movie),
(director:Person)-[:DIRECTED]->(movie)
RETURN director.name, count(*)
ORDER BY count(*) DESC
19
SELECT director.name, count(*) FROM person Keanu
JOIN acted_in ON keanu.id = acted_in.person_id
JOIN directed ON acted_in.movie_id = directed.movie_id
JOIN person AS director ON directed.person_id = director.id
WHERE keanu.name = 'Keanu Reeves‘
GROUP BY director.name ORDER BY count(*) DESC
Now let’s find out a bit about the directors in movies that Keanu Reeves acted in. We want to know
how many of those movies each of them directed.](https://image.slidesharecdn.com/490d3cfa-7342-4e8c-b4a7-1c4ff02229d0-160726075922/75/Neo4j-19-2048.jpg)


![CQL Do-It-Yourself
Add KNOWS relationships between all actors who were in the same movie
23
MATCH (a)-[:ACTED_IN]->()<-[:ACTED_IN]-(b)
CREATE UNIQUE (a)-[:KNOWS]->(b);
MATCH (a)-[:ACTED_IN|DIRECTED]->()<-[:ACTED_IN|DIRECTED]-(b)
CREATE UNIQUE (a)-[:KNOWS]->(b);](https://image.slidesharecdn.com/490d3cfa-7342-4e8c-b4a7-1c4ff02229d0-160726075922/75/Neo4j-23-2048.jpg)
![CQL Useful Tricks
Find friends of friends
MATCH (keanu{name:"Keanu Reeves"})-[:KNOWS*2]->(fof)
WHERE NOT((keanu)-[:KNOWS]-(fof))
RETURN DISTINCT fof.name;
Find shortest path
MATCH p=shortestPath(
(charlize{name:"Charlize Theron"})-[:KNOWS*]->(bacon{name:"Kevin Bacon"}))
RETURN length(rels(p));
Return the names of the people joining Charlize to Kevin.
MATCH p=shortestPath(
(charlize{name:"Charlize Theron"})-[:KNOWS*]->(bacon{name:"Kevin Bacon"}))
RETURN extract(n IN nodes(p)| n.name) AS names
24](https://image.slidesharecdn.com/490d3cfa-7342-4e8c-b4a7-1c4ff02229d0-160726075922/75/Neo4j-24-2048.jpg)
![CQL Useful Tricks
Find movies and actors up to 4 "hops" away from Kevin Bacon
MATCH (bacon:Person {name:"Kevin Bacon"})-[*1..4]-(hollywood)
RETURN DISTINCT Hollywood
Find someone to introduce Tom Hanks to Tom Cruise
MATCH (tom:Person {name:"Tom Hanks"})-[:ACTED_IN]->(m)<-[:ACTED_IN]-(coActors),
(coActors)-[:ACTED_IN]->(m2)<-[:ACTED_IN]-(cruise:Person {name:"Tom Cruise"})
RETURN tom, m, coActors, m2, cruise
25](https://image.slidesharecdn.com/490d3cfa-7342-4e8c-b4a7-1c4ff02229d0-160726075922/75/Neo4j-25-2048.jpg)
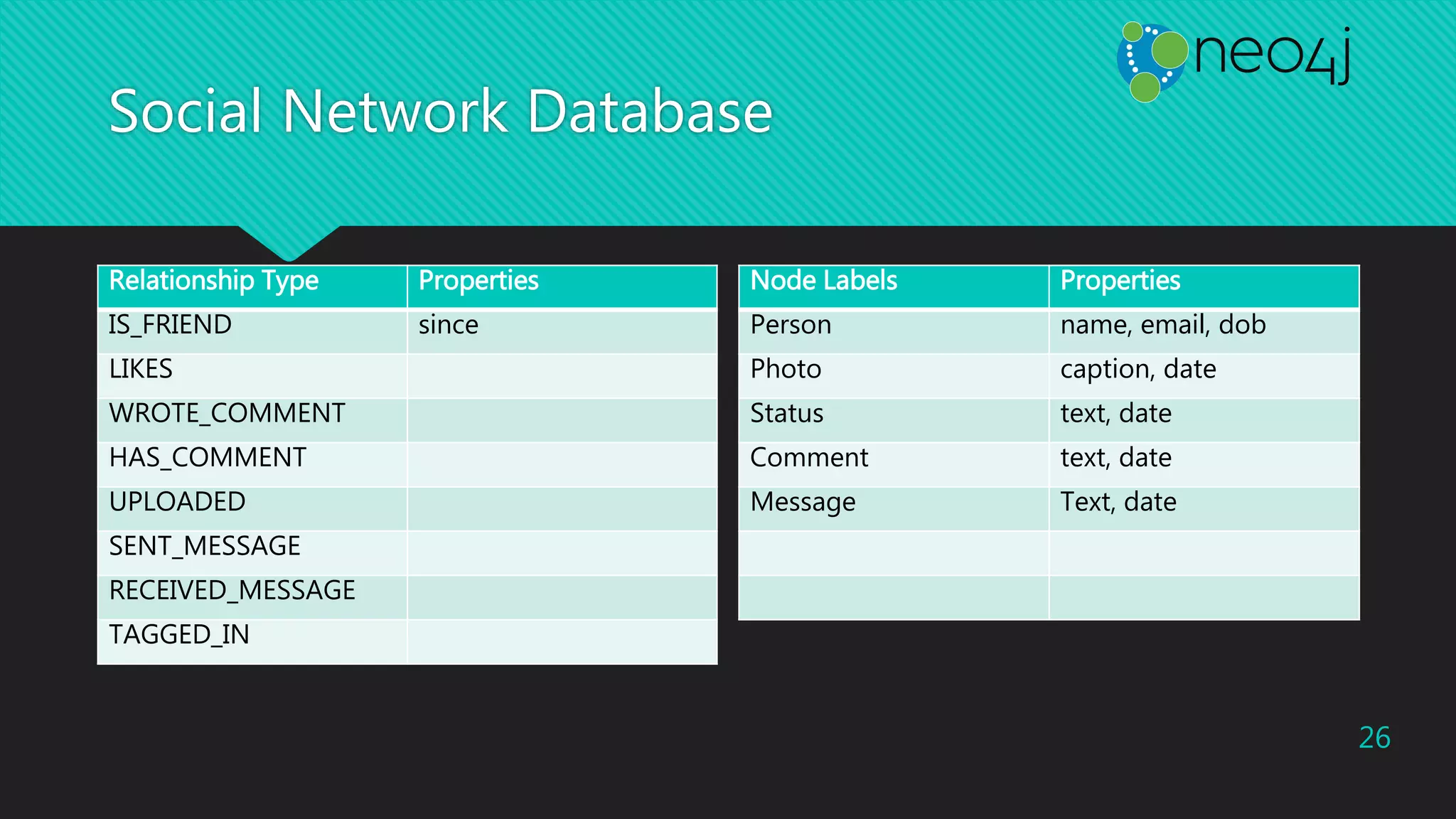
![Social Network Database (2)
CREATE (ann:Person { name: 'Ann', email:'ann@neo.4j', dob:487119060000 })
RETURN ann;
CREATE (john:Person { name: 'John', email:'john@neo.4j', dob:435679060000 })
RETURN john;
MATCH (ann:Person { name: 'Ann' }), (john:Person { name: 'John' })
CREATE UNIQUE (ann)-[:IS_FRIEND{since:'2009'}]-(john);
MATCH (ann:Person { name: 'Ann' })
CREATE (ann)-[:UPLOADED]->(status:Status{text:'Happy Birthday', date:1451610010000});
MATCH (john:Person { name: 'John' }), (status:Status{text:'Happy Birthday'})
CREATE (john)-[:LIKES]->(status);
27](https://image.slidesharecdn.com/490d3cfa-7342-4e8c-b4a7-1c4ff02229d0-160726075922/75/Neo4j-27-2048.jpg)
![Social Network Database (3)
MATCH (john:Person { name: 'John' })
CREATE (john)-[:UPLOADED]->(photo:Photo{text:'Birthday Party', date:1452410019386});
MATCH (ann:Person { name: 'Ann' }), (photo:Photo{text:'Birthday Party'})
CREATE (ann)-[:LIKES]->(photo);
MATCH (ann:Person { name: 'Ann' }), (photo:Photo{text:'Birthday Party'})
CREATE (ann)-[:WROTE_COMMENT]->(comment:Comment{text:'Happy Birthday. The party was
great!', date:1452410478569})<-[:HAS_COMMENT]-(photo);
MATCH (ann:Person { name: 'Ann' }), (photo:Photo{text:'Birthday Party'})
CREATE (ann)-[:TAGGED_IN]->(photo);
28](https://image.slidesharecdn.com/490d3cfa-7342-4e8c-b4a7-1c4ff02229d0-160726075922/75/Neo4j-28-2048.jpg)
![Social Network Database (4)
MATCH (john:Person { name: 'John' })
RETURN (john)-[:UPLOADED]->(:Photo);
MATCH (ann:Person { name: 'Ann' }) -[:LIKES]->(photo:Photo)
RETURN ann, photo;
MATCH (ann:Person { name: 'Ann' })-[:IS_FRIEND]-(:Person)-[:UPLOADED]-(photo:Photo)
RETURN ann, photo
MATCH (ann:Person { name: 'Ann' })-[:IS_FRIEND]-(friend:Person),
(friend:Person)-[:UPLOADED]-(photo:Photo)
RETURN ann, photo, friend
29](https://image.slidesharecdn.com/490d3cfa-7342-4e8c-b4a7-1c4ff02229d0-160726075922/75/Neo4j-29-2048.jpg)