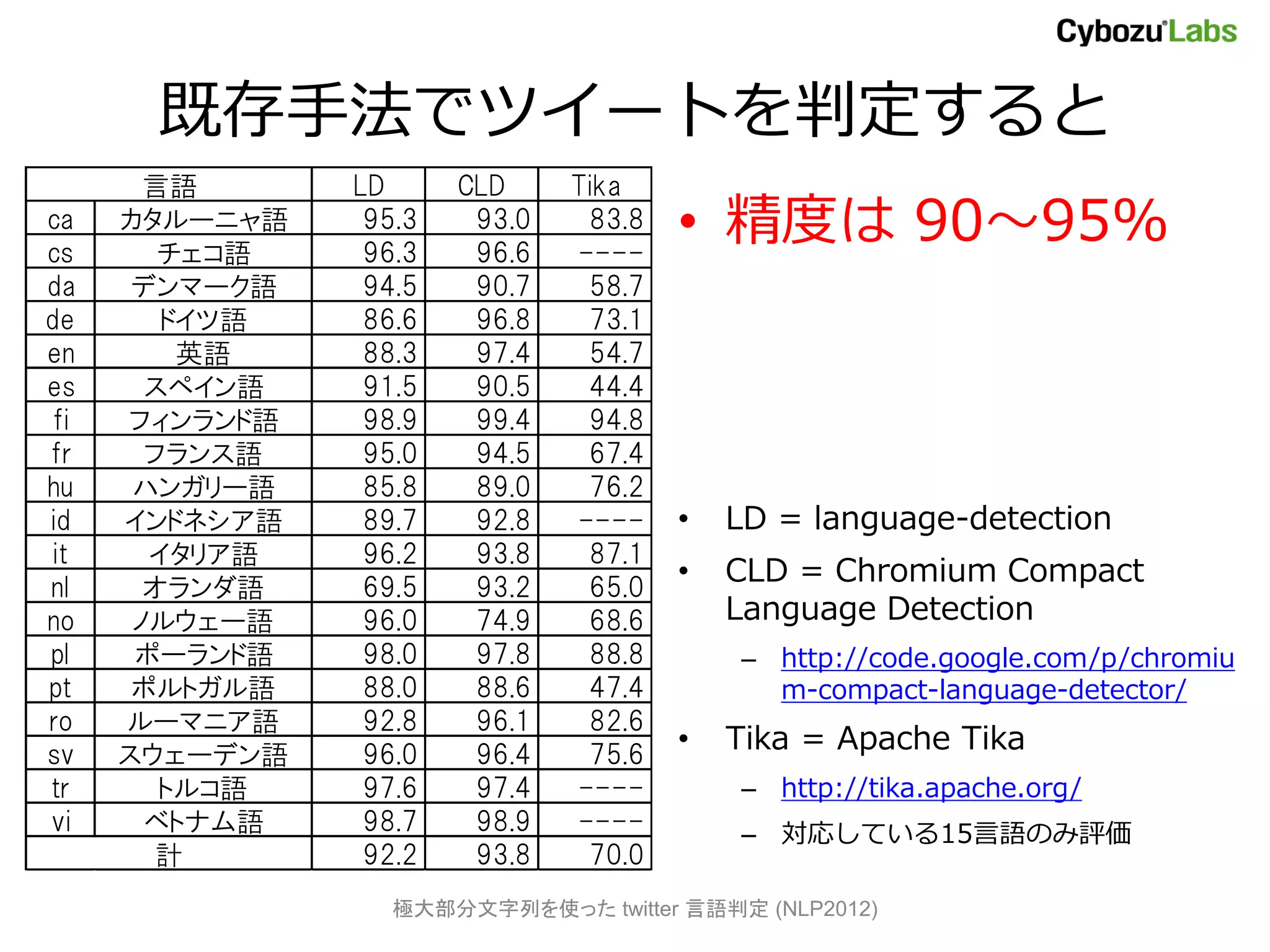
twitter言語判定は難しい? (2)
• ノイズが多い
– 正書法から外れた表現が頻出
– 省略語、短縮語、繰り返し (Cooooolll など)
• 通常の言語モデルでは尤度が小さくなる
OMG Oh My God u you
LOL Laughing Out Loud ur your イタリア語は
k を使わない
LMAO Laughing My Ass Out 4 for
F4F Follow for Follow i0u I love you
MDR Mort de Rire (仏) k che (伊)
TKT Ne t‘Inquiète Pas(仏) anke anche(伊)
極大部分文字列を使った twitter 言語判定 (NLP2012)
作成したコーパス
言語 訓練 テスト
ca カタルーニャ語 9,089 5,082
cs チェコ語 9,082 7,682
da デンマーク語 7,388 5,524
de ドイツ語 44,448 10,065
en 英語 44,520 10,168
es スペイン語 44,118 10,265
fi フィンランド語 8,087 7,050
fr フランス語 44,339 10,098
hu ハンガリー語 10,030 4,904
id インドネシア語 44,722 10,181
it イタリア語 43,366 10,152
nl オランダ語 44,682 10,007 • 訓練データは他言語ノイズの少
no ノルウェー語 10,124 8,496 ないものを選ぶ
pl ポーランド語 16,771 10,152
pt ポルトガル語 44,215 10,208 • テストデータは3語以上のツ
ro ルーマニア語 10,021 5,911 イートから選ぶ(ノイズは許容)
sv スウェーデン語 44,054 10,032 • カタルーニャ語コーパス作成で
tr トルコ語 44,703 10,308
は、Raúl Velaz 氏と真鍋宏史氏
vi ベトナム語 15,030 10,488
計 538,789 166,773 に協力をいただいています
極大部分文字列を使った twitter 言語判定 (NLP2012)
27.
データ形式
• 訓練データ・テストデータ共通
– [正解ラベル]¥t[メタデータ]¥t[テキスト]
en u should just enjoy ur vacation sadly
en :D i'm online but you arent RT that much
en im gettin attacked for a tweet LOOOOOOOOOOOOOOOOL
ca [ステータスID] [日時] [ユーザID] [UIの言語] @xxx xDDD no
m'extranya... Tal volta haguera segut millor per a la humanitat
que no l'haguera vist... you know.. xDD
極大部分文字列を使った twitter 言語判定 (NLP2012)



![言語判定とは
• 入力テキストの記述言語を推定
– Time fries like arrow → 英語
– Buona sera! → イタリア語
• 多くの言語処理での前提タスク
– 言語モデルは言語ごとに構築
– 検索、分類、抽出、翻訳、……
• 十分長い&低ノイズなテキストに対して99%以上
の精度で判定可能 [Cavnar+ 94]
– 多くの手法が 3-gram モデルを採用
極大部分文字列を使った twitter 言語判定 (NLP2012)](https://image.slidesharecdn.com/nlp2012twitterlanguagedetectionslide-120319064147-phpapp02/75/twitter-4-2048.jpg)


![twitter言語判定は難しい? (1)
• テキスト長が短い
– twitter は最大140字
– 実際は十数~数十字のものも多い
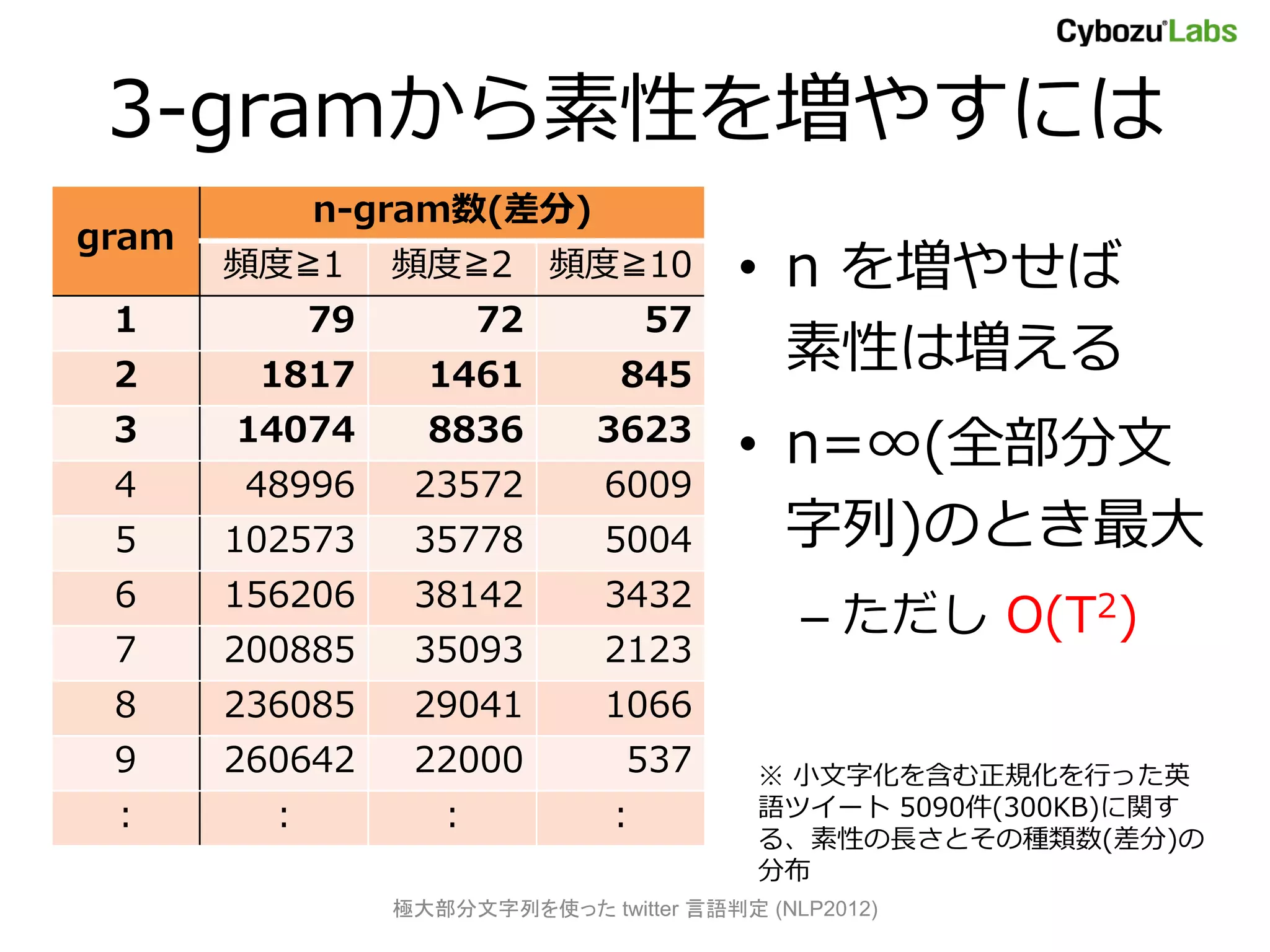
– 3-gram ではわずかな素性しか取り出せない
• LIGA [Tromp+ 11]
– 3-gram をベースにグラフ化した素性
• 長距離の素性を追加して増やす
– twitter 言語判定で95~98%(6言語)
極大部分文字列を使った twitter 言語判定 (NLP2012)](https://image.slidesharecdn.com/nlp2012twitterlanguagedetectionslide-120319064147-phpapp02/75/twitter-8-2048.jpg)


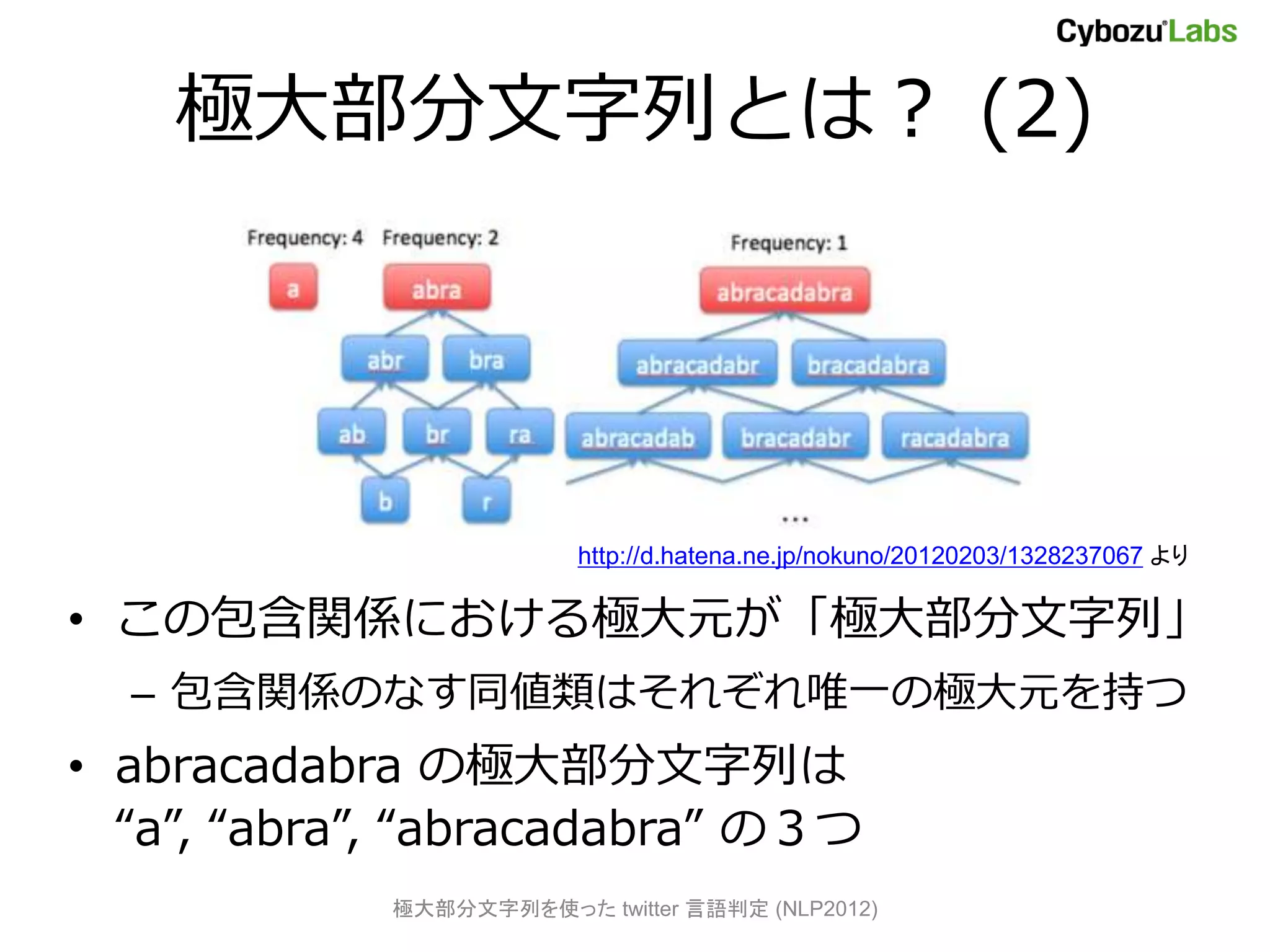
![全ての部分文字列を考慮した文書分類
[岡野原+ 08]
• 全部分文字列を素性とする多クラスロジ
スティック回帰を線形時間で構築
– 「極大部分文字列」を用いて同値なモデル
• 拡張 Suffix Array を使って線形時間で抽出
• 素性を TRIE に格納、予測(判定)も高速に
極大部分文字列を使った twitter 言語判定 (NLP2012)](https://image.slidesharecdn.com/nlp2012twitterlanguagedetectionslide-120319064147-phpapp02/75/twitter-13-2048.jpg)




![文字の連続表現を正規化
• coooooooollllll, OMGGG! のような表現
• 対応案1: [Brody+ 2011] で正規化辞書を作る
– cooooooooollllllll => cool
– 辞書にない単語に対応できない
• 対応案2: 3文字以上の連続を2文字に縮める
– 正書法の範囲で、同じラテン文字が3個以上続く言語
はない
知ってる範囲で
• 現在は案2のみ対応
– 案1 も組み合わせるのがおそらくベスト
極大部分文字列を使った twitter 言語判定 (NLP2012)](https://image.slidesharecdn.com/nlp2012twitterlanguagedetectionslide-120319064147-phpapp02/75/twitter-19-2048.jpg)







![データ形式
• 訓練データ・テストデータ共通
– [正解ラベル]¥t[メタデータ]¥t[テキスト]
en u should just enjoy ur vacation sadly
en :D i'm online but you arent RT that much
en im gettin attacked for a tweet LOOOOOOOOOOOOOOOOL
ca [ステータスID] [日時] [ユーザID] [UIの言語] @xxx xDDD no
m'extranya... Tal volta haguera segut millor per a la humanitat
que no l'haguera vist... you know.. xDD
極大部分文字列を使った twitter 言語判定 (NLP2012)](https://image.slidesharecdn.com/nlp2012twitterlanguagedetectionslide-120319064147-phpapp02/75/twitter-27-2048.jpg)

![Language Detection with Infinity-Gram
(ldig)
• ラテン文字ツイートの言語判定器
– https://github.com/shuyo/ldig
• MIT license
• 学習済みモデルも同 URL にて配布
– ∞-gram 多クラスLR(極大部分文字列) [岡野原+ 08]
– L1 SGD (Cumulative Penalty) [Tsuruoka+ 09]
– Double Array
極大部分文字列を使った twitter 言語判定 (NLP2012)](https://image.slidesharecdn.com/nlp2012twitterlanguagedetectionslide-120319064147-phpapp02/75/twitter-29-2048.jpg)
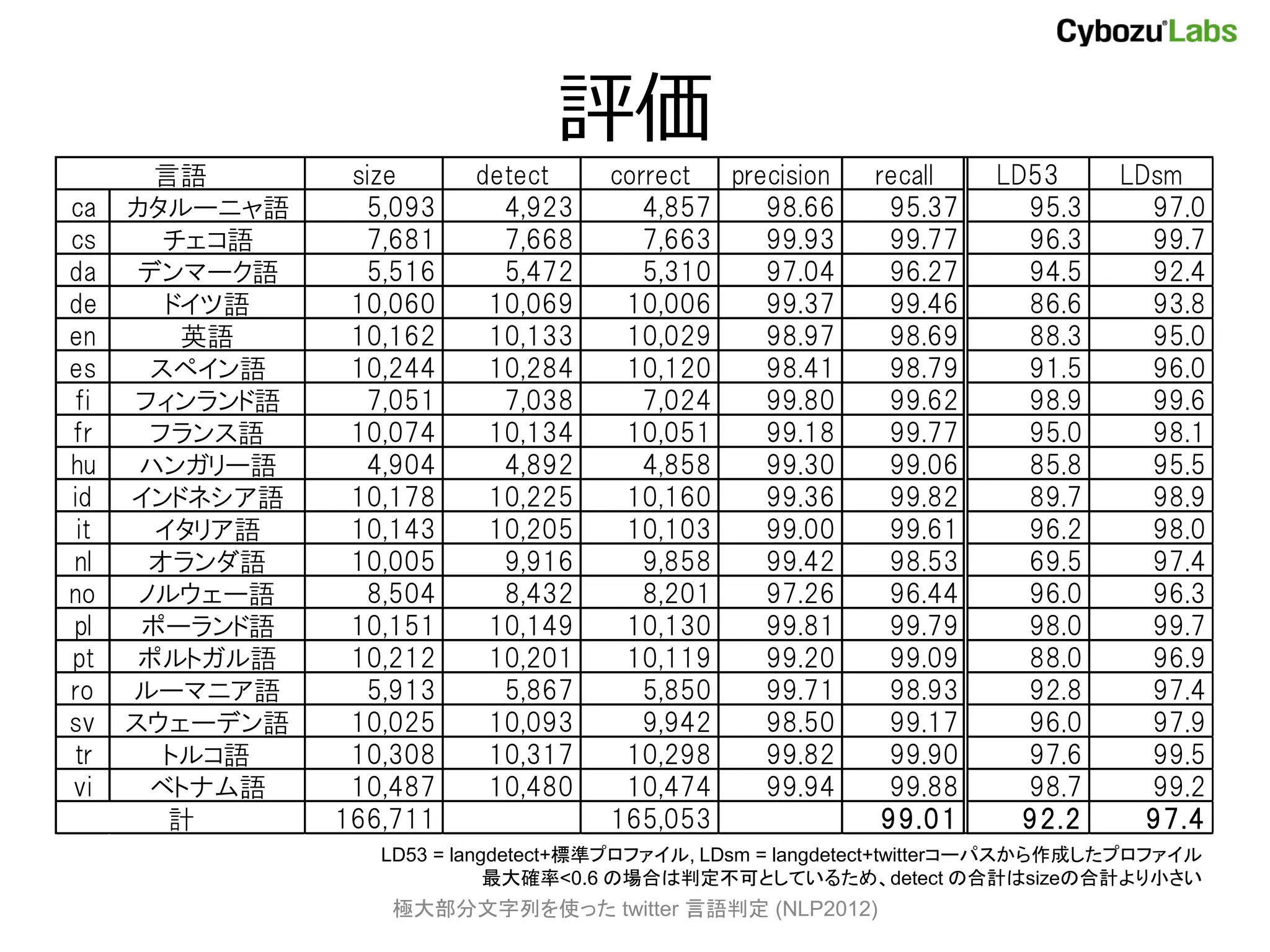
![LIGA dataset で評価
• LIGA[Tromp+ 11] が公開している
6言語 9066件のデータセットで評価
– http://www.win.tue.nl/~mpechen/projects/smm/
言語 size detect correct precision recall
de ドイツ語 1479 1476 1469 99.5 99.3
en 英語 1505 1502 1490 99.2 99.0
es スペイン語 1562 1548 1541 99.6 98.7
fr フランス語 1551 1549 1540 99.4 99.3
it イタリア語 1539 1531 1528 99.8 99.3
nl オランダ語 1430 1429 1424 99.7 99.6
計 9066 8992 99.2
19言語モデルで評価
極大部分文字列を使った twitter 言語判定 (NLP2012)](https://image.slidesharecdn.com/nlp2012twitterlanguagedetectionslide-120319064147-phpapp02/75/twitter-31-2048.jpg)

![References
• [岡野原+ 08] 全ての部分文字列を考慮した文書分類
• ニューエクスプレスシリーズ(白水社)
– スウェーデン語、ノルウェー語、デンマーク語、ポーランド語、ハン
ガリー語、ルーマニア語、チェコ語、リトアニア語、スペイン語、カ
タルーニャ語、ベトナム語、トルコ語、ドイツ語、オランダ語、スワ
ヒリ語
• [Brody+ 11] Cooooooooooooooollllllllllllll!!!!!!!!!!!!!! Using
Word Lengthening to Detect Sentiment in Microblogs
• [Cavnar+ 94] N-Gram-Based Text Categorization
• [Tsuruoka+ 09] Stochastic Gradient Descent Training for L1-
regularized Log-linear Models with Cumulative Penalty
極大部分文字列を使った twitter 言語判定 (NLP2012)](https://image.slidesharecdn.com/nlp2012twitterlanguagedetectionslide-120319064147-phpapp02/75/twitter-33-2048.jpg)







































![ACL2014 Reading: [Zhang+] "Kneser-Ney Smoothing on Expected Count" and [Pickh...](https://cdn.slidesharecdn.com/ss_thumbnails/kneser-neyacl2014-140711113350-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Yang, Downey and Boyd-Graber 2015] Efficient Methods for Incorporating Knowl...](https://cdn.slidesharecdn.com/ss_thumbnails/sparse-constrained-lda-151024072334-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Kim+ ICML2012] Dirichlet Process with Mixed Random Measures : A Nonparametri...](https://cdn.slidesharecdn.com/ss_thumbnails/dp-mrmkimicml2012-120727233419-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






