Downloaded 17 times









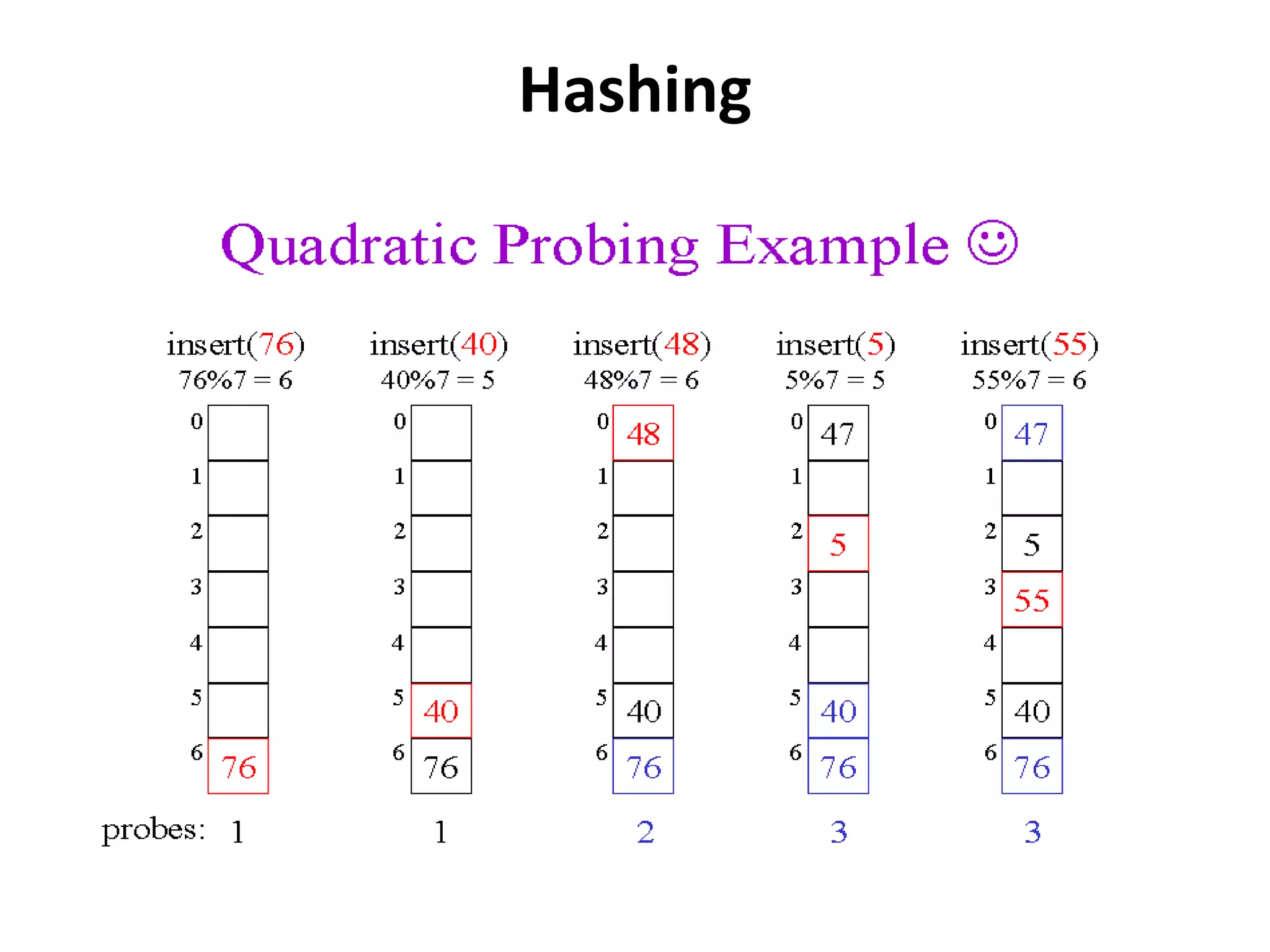






The document discusses hashing as a search technique that allows for efficient record retrieval using hash functions, which transform keys into table indices. It explores different methods for creating hash functions, various collision resolution strategies (such as linear probing, quadratic probing, and chaining), and highlights the advantages and disadvantages of each approach. Overall, hashing provides direct access to records with potential trade-offs between speed and space utilization, making it preferred for large datasets despite challenges with collisions.













































































