Downloaded 16 times







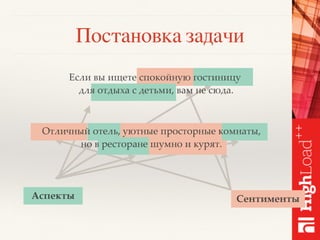
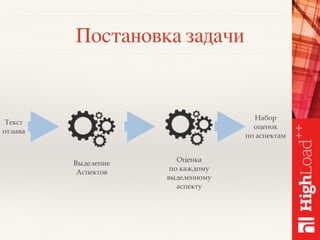




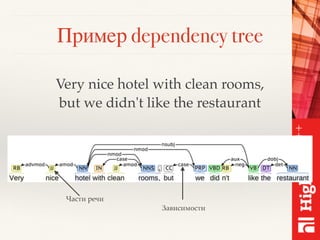


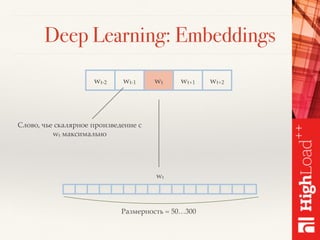
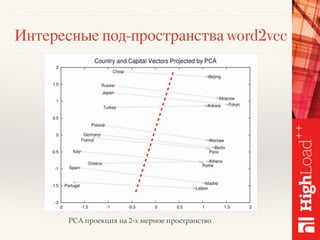




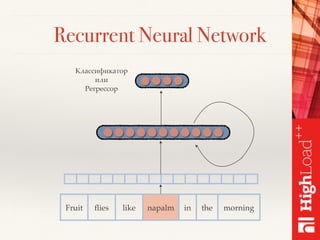

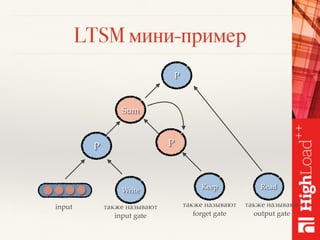
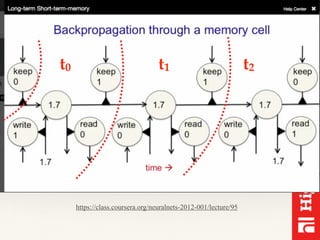
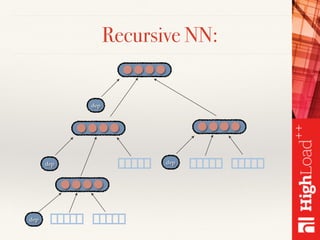








Документ описывает методы обработки и анализа отзывов в контексте платформы Toprater.com, использующей продвинутые технологии NLP для обработки больших объемов данных. Обсуждаются сложные аспекты сентимент-анализа, включая выделение критериев и оценку отзывов, а также использование глубокого обучения и различных моделей для улучшения точности анализа. Также рассматривается организация хранения и обработки данных с применением технологий big data, таких как Cassandra и Apache Spark.









































