Recommended
PDF
PPTX
PPTX
PPTX
PPTX
PDF
PDF
PPTX
PDF
PDF
実運用して分かったRabbit MQの良いところ・気をつけること #jjug
PPTX
PDF
PDF
PDF
PDF
PDF
DDD x CQRS 更新系と参照系で異なるORMを併用して上手くいった話
PPTX
トランザクションをSerializableにする4つの方法
PPTX
PDF
VPCのアウトバウンド通信を制御するためにおさえておきたい設計ポイント
PDF
組み込み関数(intrinsic)によるSIMD入門
PDF
PDF
PDF
PPTX
BuildKitによる高速でセキュアなイメージビルド
PDF
Javaコードが速く実⾏される秘密 - JITコンパイラ⼊⾨(JJUG CCC 2020 Fall講演資料)
PDF
PDF
PDF
インフラエンジニアの綺麗で優しい手順書の書き方
PDF
ブロックチェーン連続講義 第5回 分散システムのリテラシー
PPTX
More Related Content
PDF
PPTX
PPTX
PPTX
PPTX
PDF
PDF
PPTX
What's hot
PDF
PDF
実運用して分かったRabbit MQの良いところ・気をつけること #jjug
PPTX
PDF
PDF
PDF
PDF
PDF
DDD x CQRS 更新系と参照系で異なるORMを併用して上手くいった話
PPTX
トランザクションをSerializableにする4つの方法
PPTX
PDF
VPCのアウトバウンド通信を制御するためにおさえておきたい設計ポイント
PDF
組み込み関数(intrinsic)によるSIMD入門
PDF
PDF
PDF
PPTX
BuildKitによる高速でセキュアなイメージビルド
PDF
Javaコードが速く実⾏される秘密 - JITコンパイラ⼊⾨(JJUG CCC 2020 Fall講演資料)
PDF
PDF
PDF
インフラエンジニアの綺麗で優しい手順書の書き方
Viewers also liked
PDF
ブロックチェーン連続講義 第5回 分散システムのリテラシー
PPTX
PDF
PPTX
PDF
[serverlessconf2017]FaaSで簡単に実現する数十万RPSスパイク負荷試験
PDF
PDF
Software Productivity and Serverless
PDF
Serverlessconf Tokyo 2017 Biz serverless お客様のビジネスを支える�サーバーレスアーキテクチャーと開発としてのビジ...
PDF
BluetoothメッシュによるIoTシステムを支えるサーバーレス技術 #serverlesstokyo
PPTX
Step functionsとaws batchでオーケストレートするイベントドリブンな機械学習基盤
PDF
PDF
PDF
「サーバレスの薄い本」からの1年 #serverlesstokyo
Similar to Raft
PDF
PDF
PPT
PPTX
PPT
Transactional Information Systems入門
PPTX
TotalViewを使った代表的なバグに対するアプローチ
PDF
Principles of Transaction Processing Second Edition 9章 4~9節
PDF
PPT
ODP
PDF
PDF
Principles of Transaction Processing Second Edition 7章 1, 2節
PDF
PPTX
Checkpointing Algorithms on In-memory DBMS
PDF
PDF
PPTX
PPTX
PDF
Error handling in Erlang and Scala
PDF
Purely functional data structures 8.2 日本語での説明
More from Preferred Networks
PDF
PodSecurityPolicy からGatekeeper に移行しました / Kubernetes Meetup Tokyo #57
PDF
Optunaを使ったHuman-in-the-loop最適化の紹介 - 2023/04/27 W&B 東京ミートアップ #3
PDF
Kubernetes + containerd で cgroup v2 に移行したら "failed to create fsnotify watcher...
PDF
深層学習の新しい応用と、 それを支える計算機の進化 - Preferred Networks CEO 西川徹 (SEMICON Japan 2022 Ke...
PDF
Kubernetes ControllerをScale-Outさせる方法 / Kubernetes Meetup Tokyo #55
PDF
Kaggle Happywhaleコンペ優勝解法でのOptuna使用事例 - 2022/12/10 Optuna Meetup #2
PDF
最新リリース:Optuna V3の全て - 2022/12/10 Optuna Meetup #2
PDF
Optuna Dashboardの紹介と設計解説 - 2022/12/10 Optuna Meetup #2
PDF
スタートアップが提案する2030年の材料開発 - 2022/11/11 QPARC講演
PPTX
Deep Learningのための専用プロセッサ「MN-Core」の開発と活用(2022/10/19東大大学院「 融合情報学特別講義Ⅲ」)
PPTX
PFNにおける研究開発(2022/10/19 東大大学院「融合情報学特別講義Ⅲ」)
PDF
自然言語処理を 役立てるのはなぜ難しいのか(2022/10/25東大大学院「自然言語処理応用」)
PDF
Kubernetes にこれから入るかもしれない注目機能!(2022年11月版) / TechFeed Experts Night #7 〜 コンテナ技術を語る
PDF
Matlantis™のニューラルネットワークポテンシャルPFPの適用範囲拡張
PDF
PFNのオンプレ計算機クラスタの取り組み_第55回情報科学若手の会
PDF
続・PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜 #2
PDF
Kubernetes Service Account As Multi-Cloud Identity / Cloud Native Security Co...
PDF
KubeCon + CloudNativeCon Europe 2022 Recap / Kubernetes Meetup Tokyo #51 / #k...
PDF
KubeCon + CloudNativeCon Europe 2022 Recap - Batch/HPCの潮流とScheduler拡張事例 / Kub...
PDF
独断と偏見で選んだ Kubernetes 1.24 の注目機能と今後! / Kubernetes Meetup Tokyo 50
Raft 1. 2. 自己紹介
久保田展行 (@nobu_k)
Preferred Infrastructure America, Inc. 取締役
本日の NG ワード「いつアメリカ行くの?」
MessagePack for C,C++ メンテナ
分散システム、 DB 、検索エンジン
最近 golang に夢中
2
3. 今日の話: Raft
Raft とは
複製されたログを管理するためのコンセンサス ( 合意 ) アルゴリズ
ム
Raft はわかりやすさを重視して作られた
既存のアルゴリズムは難しすぎて正しく実装するのが困難
もしくは、難しい部分を簡単にしようとして安全ではなくなったり
この先生きのこるには分散システムの理解が必須
コンセンサスは安全な分散システムを構築する上で必須のトピック
ツールとして使うにしても、中身や特性は理解しておくべき
資料として使えるように字が多めになっておりますご了承ください3
4. スライドの流れ
Raft の前に
コンセンサスとは
Paxos とその問題点
Raft
Raft の概要
アルゴリズムの説明
運用のために必要な機能の説明
評価の話は・・・なしの方向で・・・w
4
5. 6. コンセンサス ( 合意 ) とは
コンセンサスとは
プロセスの集合が 1 つの値において合意を取ること
分散システムにおける重要な問題の 1 つ
6
どれか 1 つを選択
BB
AA
CC DD
EE
つけ
麺
つけ
麺
ロンアールロンアール
ロンアールロンアール
ロンアールロンアール
Red BullRed Bull
「お昼どうする?」
7. 8. どうシステムを冗長化するのか
プロセスを State Machine だと考える
プロセスは決まった状態の集合を持っている
外部からの入力 ( 命令 ) と状態遷移関数により状態が変わる
Replicated State Machine
冗長化した全プロセスが同じ State Machine として動く
同じ入力を同じ順序で全プロセスに与え、同じ状態を維持
コマンド列をログとして同じ順序で複製する問題としてとらえる
8
9. なぜレプリケーションにコンセンサスが必要なのか
同じ命令を同じ順序で届けるため
「 n 番目にどの命令を実行するか」という合意を取る
ナイーブに実装すると障害時に次のような問題が起こる
n 番目に同じ命令を実行してない or 命令の実行順序が異なる
プロセス停止、メッセージの喪失、到達タイミングの差などにより
プロセスが停止すると状態が巻き戻る
ネットワークが分断したときに 2 つの独立したグループができる
プロセスの構成 ( メンバ ) を変更できない
実は超絶に難しい問題
ではどうやって実装するのか
Paxos
9
10. 11. Paxos とは
最強のコンセンサスアルゴリズム
安全性
難しさ
Raft と一緒に 50 分で説明できるレベルじゃない
詳しくは 2012/7/5 の PFI セミナーを参照してください!
http://www.slideshare.net/pfi/paxos-13615514
コンセンサスの話ももう少し詳しく紹介しています
11
12. Paxos の問題点
理論的には問題はない ( と思う )
停止保証がないのは?
→ そもそも非同期システムにおいて 1 個以上のプロセスが障害を起
こす可能性がある状況で停止保証があるコンセンサスアルゴリズム
は存在しない
ではなにが問題なのか
理論も実装も理解しづらいのが問題
どう言うレベルで理解しづらい?
熟練リサーチャーが解説を求められると固まるレベル
理解しづらいのは問題なのか?
大問題
12
13. 理解しづらいことによる問題点
正しい Paxos が実装されない
そもそもどう実装すると正しくなるのか分からない
論文で語られていない詳細も多い
結果として、勘で実装した部分が正しいか保証できない
Multi-Paxos の実装すら同じものが存在しないレベル
Chubby も・・・
“There are significant gaps between the description of the Paxos
algorithm and the needs of a real-world system.... the final system will
be based on an un- proven protocol” (Paxos made live)
コンセンサスが正しく取れていることを仮定して構築されているシ
ステムの信頼性が崩壊!
13
14. なぜ Paxos は難しくなってしまったのか
手法が直感的でない
Single-decree Paxos をベースにしているのがよろしくない?
Multi-decree への拡張方法も説明不足
若干主観的な主張ではあるが、元論文を読むと共感できる
実装する上で必要な情報を十分に提示できていない
例: multi-decree Paxos でインスタンス ID はどうやって決める?
リーダー (distinguished proposer) はどうやって決める?
別の合意の仕組みが必要
ログ複製の文脈に限って言えば proposer が複数存在できるのは無駄
Paxos も結局 multi-Paxos で最適化としてリーダーの存在を許す
14
15. 16. 17. Raft の特徴
わかりやすさを重視したコンセンサスアルゴリズム
“ ”複製されたログを管理するためのコンセンサスアルゴリズム
Paxos と違いシステムを構築するための情報がすべて書かれている
少し制約はあるが、汎用的にも使える
Leader が強い権限を持つ
すべてのリクエストは Leader を通る
ログの管理は Leader が行う
情報は Leader からのみ流れる
RPC の呼び出しも Leader のみが行う
とりあえずさっきの図は説明していないことが多すぎる
Leader はどう選ぶ? Leader が死んだらどうする?他の障害は?
17
18. 19. 20. Raft におけるプロセスの状態
プロセスは次の 3 つの状態を持つ: Follower, Candidate, Leader
この状態は Replicated State Machine 内部の状態とは別
Follower: 完全受け身の状態。通信を受け取って応答するだけ。
Candidate: Leader になりたい人。
Leader: ボス。すべてのリクエストは Leader 経由で行われる。
必ず最大 1 プロセスになるように!
起動直後はみんな Follower
20
Follower Candidate Leader
Start up
21. Leader と Term
Raft 内では Term という論理時間が使われる
Term とは特定の Leader が連続して活動していた期間
Term には単調増加する ID が割り振られる
各 Term は Leader の選出から始まる
各 Term には 0 人か 1 人の Leader がいる
Leader がいなくなったら新しい Candidate が次の Term を開始
は Leader 選出期間
は通常稼働中の期間
21
Term 1 Term 2 T 3 Term 4
22. Leader 選出開始のタイミング
Raft ではハートビートを利用して Leader 選出の開始判断をする
ハートビート = 空の AppendEntries RPC( 後述 )
一定期間 Leader からハートビートが来なかったら選出開始
Election timeout: 実験では 150ms 前後に設定
タイムアウトした Follower が Candidate となる
22
Follower Candidate Leader
Start up
Times out,
Starts election
23. 投票開始
Current term number
各プロセスは current term number を持つ
Leader 、 Candidate のリクエストは current term number を含む
Current term number は新しい値を受け取る度に更新される
Follower は Candidate になったタイミングで、
1. 自身の Current term number を増やす
2. RequestVote RPC を全メンバに送信する
23
24. RequestVote API
引数
term: Candidate が観測している現在の term
candidateId: Candidate のクラスタ内での ID
lastLogIndex, lastLogTerm: ログレプリケーションのときに説明
Candidate が持つ情報の新しさを判定するために利用
Follower からの返値
term: Follower が観測している term
voteGranted: bool 値。 true なら Follower が投票したことを表す。
24
25. 投票と集計
Follower は一番最初に受け取った有効リクエストに対して投票する
ただし、後ほど安全性を保証するために条件を追加
Follower は 1 term で 1 回までしか投票しない
これにより 1 term で 1 Leader しか選出されない
Candidate はクラスタの半数以上から投票されたら Leader になる
自分は自分に投票する ( これも 1 term 1 回に含まれる )
25
Follower Candidate Leader
Start up
Times out,
starts election
Receives votes from
majority of servers
26. 投票終了
Leader になった Candidate はハートビートを全員に送信
Follower はハートビートを受け取ったら Leader の情報を更新
Candidate はハートビートを受け取ったら Follower に戻る
ただし、ハートビートの current term number が古かったら拒否!
そのまま Candidate の状態を維持
26
Follower Candidate Leader
Start up
Times out,
starts election
Receives votes from
majority of servers
Discovers the current
leader
27. 古い Leader 、 Candidate の扱い
Current term number を使って古い Leader 、 Candidate を検出
新しい current term number のリクエストを受け取ることで検知
Follower が Leader より新しい current term number を持つことも
通信障害などで、旧 Leader が知らない場所で新しい Leader が誕生
古い Leader や Candidate は、検出次第すぐに Follower に戻る
Follower は古い Leader や Candidate からのリクエストを拒否する
27
Follower Candidate Leader
Start up
Times out,
starts election
Receives votes from
majority of servers
Discovers a process
with higher term
Discovers the current
leader or new term
28. 投票が完了しないとき
投票が完了しない Term もある
複数の Candidate がほぼ同時に登場し、全員が過半数に至らない
メッセージロスト
そう言うときは election timeout が発生して投票をやり直し
Live lock
やり直し時に複数 Follower がほぼ同時に Candidate になると厄介
無限に投票がやり直される可能性もある
解決策: Election timeout の時間をランダムにする
大体 Candidate は 1 プロセスだけになるのでうまくいく
実装では 150-300ms とした
あくまで大体うまくいくのであって、たまに衝突は起こる
ただし、実用上問題の無いレベル!ということ
28
29. まとめ: Leader 選出
Follower のルール:
自分より term が新しい Candidate からの RequestVote に投票する
Election timeout が発生したら Candidate になる
Candidate のルール:
自分に投票する
全プロセスに対して RequestVote RPC を実行
自分を含め過半数のプロセスから投票されたら Leader になる
新しい Leader からの AppendEntries RPC が来たら Follower に戻る
Election timeout が発生したら新しい term で再投票
後で safety 実現のために新ルールが追加される
29
30. 31. ログの持ち方
ログはすべて Leader からの AppendEntries RPC により複製される
31
1
x 3←
1
x 3←
1
x 3←
1
x 3←
1
x 3←
1
y 1←
1
y 1←
1
y 1←
1
y 1←
1
y 1←
1
y 9←
1
y 9←
1
y 9←
1
y 9←
2
x 2←
2
x 2←
2
x 2←
2
x 2←
3
x 0←
3
x 0←
3
x 0←
3
x 0←
3
y 7←
3
y 7←
3
y 7←
3
x 5←
3
x 5←
3
x 5←
3
x 4←
3
x 4←
1 2 3 4 5 6 7 8 log index
leader
followers
term number
(a)
(b)
(c)
(e)
(f)
32. AppendEntries RPC
引数
term: Leader の term number
leaderId: Leader のクラスタ内での ID
prevLogIndex, prevLogTerm: 1 個古いエントリのバージョン情報
entries[]: ログエントリ ( 配列 ) 、空だと heartbeat
leaderCommit: Leader がコミット済みの index number
返値
term: Follower が観測している term number
success: prevLogIndex/Term が一致したかどうか
false だったら古いログの再送が必要
もしくは Leader が古くなってる
32
33. 34. 35. コミット
Leader は自分のステートマシンにコマンドを反映する
ここからはやり直しが効かないし、ログの上書きも起こらない
コミットしたタイミングで commitIndex を増やす
Follower のコミットタイミング判断
AppendEntries の leaderCommit を参照して判断
Leader がコミットしたところまでは自分もコミットする
つまり、コミットのタイミングは Leader と Follower で異なる
後ほど問題が無いことを説明
35
36. 異常系: Leader 障害が積み重なると・・・
1
Leader
for term 8
ログの再送・上書きによるコミット前エントリの同期・修正が必要。
一貫性チェックの仕組みと一緒に考える。
36
1 1 1 4 4 5 5 6 6 6
1 1 1 4 4 5 5 6 6
1 1 1 4
1 1 1 4 4 5 5 6 6 6
1 1 1 4 4 5 5 6 6 6
1 1 1 4 4
1 1 1 2
6
7 7
4 4
2 2 3 3 3 3 3
(a)
(b)
(c)
(d)
(e)
(f)
2 3 4 5 6 7 8 9 10 11 12
同期遅れ
未コミットのエントリを持つ
同期遅れ&未コミットエントリ持ち
37. ログの一貫性維持
守りたい制約
異なる 2 つのログにて、ある index のエントリが同じ term だったら
ログの中身は同じ
それ以前のログの内容は同じ
AppendEntries 時にチェックを加える
Leader: 直前のエントリの index と term number を渡す
Follower: 自分の最新エントリが同じ index/term を持つかチェック
持ってた:自分のログにエントリを追加し AppendEntries に応答
持ってなかった: false を返しつつ・・・
– 自分の term が新しかったらそれを leader に伝える
– 自分が遅れていたら古いエントリの再送を待つ
ヤバいケースに関しては safety のところで
37
38. ログの再送と上書き
AppendEntries では Follower のログの上書きも行う
ただし未コミットのログのみ!!
制約を守っていればコミット済みのログの書き換えは行われない
また、 Leader は自分のログに対しては Append しか行わない
同期遅れが原因で AppendEntries が失敗したら昔のエントリを再送
Leader は 1 つ古いエントリについて AppendEntries を再実行
2 個前のエントリの index/term を使って 1 個前のエントリを再送
成功したら次のエントリも再送
失敗したら 2 個前のエントリに関して同様に再送を試みる
成功するまで続ける・・・
– 効率悪くない?→現実のケースでは大丈夫だったらしい
– 必要であれば最適化も可能だが、 keep it simple (stupid)!
38
39. 異常系の対応
Leader
Follower への通信がタイムアウト:あとで再送する
クラッシュ:未配布のエントリは消失、 Client が再送
Follower
クラッシュ: Leader が後で再送してくれる
Client
Leader への通信がタイムアウト:再送
アプリケーション側で冪等性を保証する仕組みが必要・・・
39
40. まとめ:ログレプリケーション
Leader がすべてのリクエストを処理する
異常系は基本的に再送でカバー
Client は冪等性に注意しなければならない・・・
後ほど少し補足
過半数のプロセスが書いたエントリをコミット
コミット =Replicated State Machine に命令を反映すること
Follower は leaderCommit からコミットすべきエントリを知る
Leader とコミットタイミングがずれるが大丈夫
40
41. 42. 43. ( 今更ながら )Raft が保証するもの : 論文の Figure 3
Election Safety
1 term で 1 Leader しか選択されない
Leader Append-Only
Leader は自分のログに対しては Append しかしない
Follower のログ ( 未コミット分 ) を書き換えることはある
Log Matching
ログの一貫性を維持するための性質
Leader Completeness
( 若干省略 )Leader はそれまでにコミットされた全ログを持つ
State Machine Safety
( 若干省略 ) 全プロセスが同じコマンドを state machine に適用する
最終的に保証したいもの
43
44. Leader Completeness
守りたい制約
Leader はそれまでにコミットされた全ログエントリを持つ
実現方法:選出のタイミングまでにコミットされたすべてのエント
リを持つプロセスしか Leader として選出されなければ良い
前 Leader がコミットしたエントリは未コミット状態でも良い
あくまでコミット済みエントリを持っているだけで十分
他のプロセスから不足分を調達するような複雑さは不要
Leader 選出とコミットのタイミングに関してルールを追加
2 つ合わせて初めて機能するルール
44
45. Leader 選出の追加ルール
過半数の Follower からログがより新しいと認められたら OK
Candidate の term と index number を元に判断
RequestVote RPC で渡される
2 つのログのどちらが新しいかは次のように判定する
1. 最新のエントリの Term が異なる場合は Term が大きい方が新しい
2. Term が同じなら index number が大きい ( ログが長い ) 方が新しい
これと次の新コミットルールを同時に守る
その前にコミット時に起こる問題を見てみる
45
1
1 2
41 2
1 2
3
3
1 2
1 2
3
3
1 2
1 2
3
3
3
4
<<1. 2.
46. コミットタイミングの問題 (1/2)
Leader S1 が死亡
S2 にだけエントリを複製
S5 が Term 3 の Leader に
エントリを 1 個作る
その後複製せずに死亡
S1 が再度 Leader に
S3 にエントリを複製
2 は過半数に複製された
この時点で 2 をコミットで
きるか?
46
1 2
1 2
1
1
1
S1
S2
S3
S4
S5
1 2
1 2
1 2
1
1
1
S1
S2
S3
S4
S5
1 2
3
1 2
1 2
1
1
1
S1
S2
S3
S4
S5
1 2
3
4
2
3
47. コミットタイミングの問題 (2/2)
安全にコミットできない
S1 が 2 をコミット
直後に S1 が死亡する
S2,S3 は未コミット
S5 が Term 5 の Leader に
全員 index=2
Term は 3 が最新
S2,S3,S4 が投票可能
S1 がコミット後に死んだら
S5 が 3 を全員に複製
S1 が復活
エントリの不整合
47
1 2
1 2
1
1
1
S1
S2
S3
S4
S5
1 2
3
4
2
3
1 2
1 2
1
1
1
S1
S2
S3
S4
S5
1 2
3
4
2
3
S5 は Term 3 のエントリ 2 を
全員に上書きする権限を持つ
48. コミットタイミングの追加ルール
まず自分の term でコミット可能なエントリを作り出す
過半数のプロセスが自分の index/term で同じログエントリを持つ
Log Matching property より、それらのプロセスのログは同一
さらに、 Leader はそれらのプロセスからしか選出されない
コミット可能なエントリができたら古いエントリから順次コミット
48
1 2
1 2
1
1
1
S1
S2
S3
S4
S5
1 2
3
4
2
3
4
4
2 をコミットする前に 3 を過半数に複製。
そうすることで、次の Leader は 3 を持つ。
この時点で 2 をコミット直後に死んでも
次の Leader も同じエントリをコミットする。
3 はもちろん 2 の後にコミット。
49. 追加コミットルールの実現方法
論文的には 2 つ方法があるように見える
1. 次の Client からのリクエストを待つ
その段階で新しいエントリが作成される
それがコミット可能になった段階で古いエントリもコミット
1. Candidate が Leader になったら no-op エントリをコミットを試みる
no-op がコミット可能になったら古いエントリから順次コミット
後ほど説明する read を最適化するときにも役立つ
実は論文だとそこで初めて出てくる情報
個人的には後者の方が無難な気がした
49
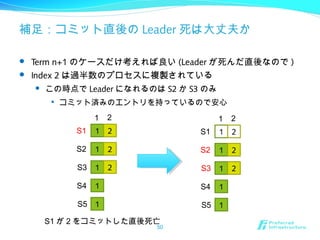
50. 補足:コミット直後の Leader 死は大丈夫か
Term n+1 のケースだけ考えれば良い (Leader が死んだ直後なので )
Index 2 は過半数のプロセスに複製されている
この時点で Leader になれるのは S2 か S3 のみ
コミット済みのエントリを持っているので安心
50
1 2
1 2
1
1
1
S1
S2
S3
S4
S5
1 2
2
1 2
1 2
1
1
1
S1
S2
S3
S4
S5
1 2
2
S1 が 2 をコミットした直後死亡
51. まとめ: Safety
2 つの追加ルールで Leader の障害に対応
ログが新しい Leader を選出する
term が変わった直後には古いエントリをコミットしない
Safety の証明は論文を参照!
時間が足りなかった
基本的には新しい Leader の 1 個前の Leader がコミットしたエント
リを持ってないと仮定して矛盾を示す流れ
その後、 State Machine Safety が満たされるのは自明
別文献で形式手法での証明もある
Safety proof and formal specification for Raft.
http://ramcloud.stanford.edu/~ongaro/raftproof.pdf
51
52. 53. クラスタの構成変更
運用中にたまに発生する
故障したマシンの取り替え
マシンの増大
etc
難しい点
新構成と旧構成でそれぞれ独立して Leader が選ばれる可能性がある
Raft の safety は単一 Leader が前提となっている
対処方法
一般的には 2 フェーズ以上での移行が必要
一番実現が簡単なのは全台停止→設定変更→再起動
しかし、普通は無停止で移行したい
53
54. Joint consensus
新構成と旧構成が混ざった状態を間に挟む
旧構成: C_old={A, B, C}
新構成: C_new={B, C, D, E, F}
混在構成: C_old,new={A, B, C, D, E, F}
54
AA
BB
CC
DD
EE
FF
C_old
C_new
55. Joint consensus でのルール
1. ログは C_old,new の全プロセスに複製される
2. C_old, C_new のどちらのプロセスも Leader になれる
3. 合意 (Leader 選出、ログのコミット ) は両構成からの過半数が必要
C_old と C_new で独立して過半数チェックを行う
55
AA
BB
CC
DD
EE
FF
C_old
C_new
紫は 3 プロセスだが
C_old,C_new ともに
過半数を占める。
56. 構成変更フロー
1. C_old の Leader はまず C_old,new への構成へ移るように指示
特殊なログエントリとして全 Follower に複製する
このエントリの情報は未コミットでも反映される
この時点ではまだ C_old 内で合意が取れれば OK
1. C_old,new がコミットされたら joint consensus へ移行
同時に C_new に移る指示を同様の仕組みで全 Follower に通達
1. C_new がコミットされたら C_old のプロセスは消滅する
C_old,new コミット前は、 C_old が独断でコミットしても安全
C_new が複製され始めたら C_new が独断でコミットしても安全
56
57. 残りの問題
C_new コミット時に C_old のプロセスが Leader だったとき
Leader はその時点で退く
C_new がコミットされるまで Leader が投票権を持たない状態が続
く
新規プロセスが登録されるとき
新しいプロセスはログを持ってないので同期が必要になる
同期が終わるまでクラスタ全体でコミットできなくなることも
C_old,new の前にログ同期専用のフェーズを追加する
C++ 実装ではステージングフェーズと呼ばれている
ログの同期が終わってから C_old,new を複製
ダウンタイムが最小に
57
58. 補足:ステージングの課題
著者の C++ 実装を見てみた
ステージングの情報は Leader しか持ってなさそう
Leader がステージング中に死ぬと構成変更が実行されない
クライアント側でタイムアウトで再送すればいい気もするが・・・
– しかし、同期には時間がかかるためタイムアウトの設定は難しい
ステージング開始前にステージング構成のログを複製すれば解決?
って適当にやるとそれこそ Paxos の unproven 実装問題が再発
58
59. 未解決問題
構成変更中音信不通だった C_old のプロセスが生き返るケース
C_old のプロセスには当然 C_new 専用のハートビートは届かない
Election timeout が何度も発生し、ひたすら Leader 選出が続く
Leader election 中はリクエストを受け付けられず可用性が下がる
59
AA
BB
CC
DD
EE
FF
C_new
60. 61. 62. ログの肥大化問題
ログは無限に貯められない
どこかで不要なログを消す必要がある
消し方
1. Log cleaning
不要になったエントリを取り除く
– 不要 = 取り除いても現在の状態に影響がない
意味づけや実装が難しい
1. Snapshotting
Replicated State Machine のスナップショットをとる
– 分散ではなくプロセス毎に独立したスナップショット
Chubby や ZooKeeper でも取られている一般的なアプローチ
62
63. Replicated State Machine のスナップショット
ハッシュテーブルを利用した簡単なインメモリ KVS を考える
オペレーション : キーに値を設定
内部表現 : JSON のオブジェクトみたいなもの
63
x 3 y 1 y 9 x 2 x 0 y 7 x 5
last included index: 5
last included term: 3
{
x: 0
y: 9
}
1 2 3 4 5 6 7
y 7 x 5
6 7
Index 5 の段階で取ったスナップショット
+ 残りのログ
元ログ
64. 65. スナップショットの取り方
スナップショットを取っている間もシステムを停止させたくない
Copy on Write を活用する
1. 永続データ構造みたいなのを使う
Purely functional な感じのデータ構造
1. Linux で fork を活用する (Redis のアプローチ )
スナップショットを取るプロセスを fork
元プロセスでは書き込み処理を継続可能
頻度
スナップショットはそれなりに重い処理
高頻度すぎるとシステムが遅く、低すぎると復旧時間が長くなる
ログが一定サイズになったら実行するのがシンプル
65
66. 補足: Raft とスナップショット
スナップショットは Raft 的には例外的なオペレーション
唯一 Follower が能動的にスナップショットを取る
なぜ Leader がスナップショットを取って配れないのか?
スナップショットの配布がネットワークを使い切っちゃう可能性が
Leader がスナップショットを取るタイミングを指示できないか?
最適なタイミングを知るためにはシステムが若干複雑に
結局 Follower が自分でやるのが楽
必要な情報は全部 Follower が持ってる
66
67. 68. 69. Client と Leader
Raft とのやりとりはすべて Leader を介して行う
Follower へのリクエストはすべて失敗
代わりに自分が知っている最新の Leader の位置を返す
Follower はハートビートなどの情報から Leader について知ってい
る
Client はまず適当なノードにリクエストを送信
失敗したら Leader に問い合わせ直す
Leader へのリクエストがタイムアウトしたときも同様
69
70. Linearizability の実現
Linearizability とは ( 引用 )
“each operation appears to execute instantaneously, exactly once, at
some point between its invocation and its response”
Write と Read で分けて考える
Write
Leader が 1 個 1 個実行しているためタイミングの問題は無い
Raft の RPC は冪等なので再送による問題も起こらない
Client のリトライによる重複実行が課題
アプリケーション側でコマンドに ID を持たせて重複実行を回避
– あっさり書いてるけど地味に大変・・・
Read
古い情報を返さないようにする
70
71. Linearizability: Read
Write と同様にログエントリにすれば解決
しかし、状態を変更する必要が無いため高速化できる部分が多い
本来であればログに書き込む必要がない
命令のコミット処理もいらない
最適化するといくつか問題が起こる可能性がある
前 Leader がコミット済みだが自分がコミットしてない情報を返す
まずは Leader になった直後に自分の term で no-op をコミット
前 term までの情報はすべてコミットされるので最新情報を返せる
自分が値を読んでる間に別の Leader が誕生
返す前に全台にハートビートを送り過半数からのレスポンスを待つ
ログに書き込むよりは低いコストで読み込める
71
72. まとめ: Client とのやりとり
Client はまず適当なプロセスにリクエストを送信
Leader じゃなかったら、教えて貰った Leader に問い合わせし直し
Linearizability
Write
Raft のレイヤーでは問題無い
Client は再送検知の仕組みを自分で実装する
– もしくは全命令を冪等にする
Read
最適化しつつ古い値を返さないように工夫する
72
73. 74. 75. Paxos は無くなるのか?
無くならないと思う
問題になるのは Raft の時間的な制約
ブロードキャスト時間 << election timeout << MTBF
広域で使おうとすると難しい ( 使えなくもないとは思う )
RTT が 150ms かかる場合の election timeout はどれくらいが適切?
Single-decree や基本的な Paxos で十分なことも多い
例: KVS にてキー毎に独立して合意を取る
グローバルな順序付けがいらない
Paxos は Leader が複数いても安全に動く
Leader を維持するコストがいらない ( 合意コストが上がるけど )
時間的な制約もほとんどないに等しい
結局は適材適所
75
76. ZooKeeper は無くなるのか?
Raft は ZooKeeper じゃなくて ZAB 相当
Raft の上に ZooKeeper 相当のアプリケーションを作ることも可能
完全に ZooKeeper 相当では無いが、 etcd というのがある
https://github.com/coreos/etcd
ZooKeeper( や Chubby) のコンセプト自体は不滅
実装がどうなるかは謎!
76
77.
































![AppendEntries RPC
引数
term: Leader の term number
leaderId: Leader のクラスタ内での ID
prevLogIndex, prevLogTerm: 1 個古いエントリのバージョン情報
entries[]: ログエントリ ( 配列 ) 、空だと heartbeat
leaderCommit: Leader がコミット済みの index number
返値
term: Follower が観測している term number
success: prevLogIndex/Term が一致したかどうか
false だったら古いログの再送が必要
もしくは Leader が古くなってる
32](https://image.slidesharecdn.com/pfiseminar20140313-raft-140622013544-phpapp02/85/Raft-32-320.jpg)












































































![[serverlessconf2017]FaaSで簡単に実現する数十万RPSスパイク負荷試験](https://cdn.slidesharecdn.com/ss_thumbnails/faasrps-171104115940-thumbnail.jpg?width=640&height=640&fit=bounds)























![[Basic 9] 並列処理 / 排他制御](https://cdn.slidesharecdn.com/ss_thumbnails/basic-091-180306131603-thumbnail.jpg?width=640&height=640&fit=bounds)























