Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Kumazaki Hiroki
PPTX, PDF
130,476 views
分散システムについて語らせてくれ
NTT Tech Conference #2 にて話した資料 時間が足りなかったので全部は話せなかった。
Engineering
◦
Related topics:
Distributed System
•
Read more
732
Save
Share
Embed
Embed presentation
Download
Downloaded 553 times
1
/ 45
2
/ 45
3
/ 45
4
/ 45
5
/ 45
6
/ 45
7
/ 45
8
/ 45
9
/ 45
10
/ 45
11
/ 45
12
/ 45
13
/ 45
Most read
14
/ 45
15
/ 45
16
/ 45
17
/ 45
18
/ 45
19
/ 45
20
/ 45
21
/ 45
22
/ 45
23
/ 45
24
/ 45
25
/ 45
26
/ 45
27
/ 45
28
/ 45
29
/ 45
30
/ 45
31
/ 45
32
/ 45
33
/ 45
34
/ 45
35
/ 45
36
/ 45
37
/ 45
38
/ 45
39
/ 45
40
/ 45
Most read
41
/ 45
Most read
42
/ 45
43
/ 45
44
/ 45
45
/ 45
More Related Content
PPTX
本当は恐ろしい分散システムの話
by
Kumazaki Hiroki
PPT
Raft
by
Preferred Networks
PDF
Paxos
by
Preferred Networks
PPTX
トランザクションの設計と進化
by
Kumazaki Hiroki
PPTX
冬のLock free祭り safe
by
Kumazaki Hiroki
PDF
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
PPTX
Redisの特徴と活用方法について
by
Yuji Otani
PDF
Dockerからcontainerdへの移行
by
Kohei Tokunaga
本当は恐ろしい分散システムの話
by
Kumazaki Hiroki
Raft
by
Preferred Networks
Paxos
by
Preferred Networks
トランザクションの設計と進化
by
Kumazaki Hiroki
冬のLock free祭り safe
by
Kumazaki Hiroki
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
Redisの特徴と活用方法について
by
Yuji Otani
Dockerからcontainerdへの移行
by
Kohei Tokunaga
What's hot
PDF
コンテナの作り方「Dockerは裏方で何をしているのか?」
by
Masahito Zembutsu
PDF
ツール比較しながら語る O/RマッパーとDBマイグレーションの実際のところ
by
Y Watanabe
PDF
分散システムの限界について知ろう
by
Shingo Omura
PDF
Google Cloud で実践する SRE
by
Google Cloud Platform - Japan
PPTX
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
PPTX
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
PPTX
DockerコンテナでGitを使う
by
Kazuhiro Suga
PDF
BuildKitの概要と最近の機能
by
Kohei Tokunaga
PDF
Dockerfile を書くためのベストプラクティス解説編
by
Masahito Zembutsu
PDF
PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜
by
Preferred Networks
PPTX
トランザクションをSerializableにする4つの方法
by
Kumazaki Hiroki
PPTX
地理分散DBについて
by
Kumazaki Hiroki
PDF
TLS, HTTP/2演習
by
shigeki_ohtsu
PDF
マイクロにしすぎた結果がこれだよ!
by
mosa siru
PDF
例外設計における大罪
by
Takuto Wada
PDF
コンテナ未経験新人が学ぶコンテナ技術入門
by
Kohei Tokunaga
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
PDF
Grafana LokiではじめるKubernetesロギングハンズオン(NTT Tech Conference #4 ハンズオン資料)
by
NTT DATA Technology & Innovation
PDF
Where狙いのキー、order by狙いのキー
by
yoku0825
PDF
単なるキャッシュじゃないよ!?infinispanの紹介
by
AdvancedTechNight
コンテナの作り方「Dockerは裏方で何をしているのか?」
by
Masahito Zembutsu
ツール比較しながら語る O/RマッパーとDBマイグレーションの実際のところ
by
Y Watanabe
分散システムの限界について知ろう
by
Shingo Omura
Google Cloud で実践する SRE
by
Google Cloud Platform - Japan
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
DockerコンテナでGitを使う
by
Kazuhiro Suga
BuildKitの概要と最近の機能
by
Kohei Tokunaga
Dockerfile を書くためのベストプラクティス解説編
by
Masahito Zembutsu
PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜
by
Preferred Networks
トランザクションをSerializableにする4つの方法
by
Kumazaki Hiroki
地理分散DBについて
by
Kumazaki Hiroki
TLS, HTTP/2演習
by
shigeki_ohtsu
マイクロにしすぎた結果がこれだよ!
by
mosa siru
例外設計における大罪
by
Takuto Wada
コンテナ未経験新人が学ぶコンテナ技術入門
by
Kohei Tokunaga
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
Grafana LokiではじめるKubernetesロギングハンズオン(NTT Tech Conference #4 ハンズオン資料)
by
NTT DATA Technology & Innovation
Where狙いのキー、order by狙いのキー
by
yoku0825
単なるキャッシュじゃないよ!?infinispanの紹介
by
AdvancedTechNight
Viewers also liked
PDF
エンジニアなら知っておきたい「仮想マシン」のしくみ v1.1 (hbstudy 17)
by
Takeshi HASEGAWA
PDF
普通の人でもわかる Paxos
by
tyonekura
PPTX
Google Dremel
by
maruyama097
PDF
Yahoo!ブラウザーアプリのプロダクトマネージャーが考えていること
by
Yahoo!デベロッパーネットワーク
PDF
行列ができるECサイトの悩み~ショッピングや決済の技術的問題と処方箋
by
Yahoo!デベロッパーネットワーク
PDF
ヤフオク!の快適なカスタマー体験を支えるモバイルアプリのライブアップデート技術
by
Yahoo!デベロッパーネットワーク
PDF
市場で勝ち続けるための品質とテストの技術①
by
Yahoo!デベロッパーネットワーク
PDF
市場で勝ち続けるための品質とテストの技術②
by
Yahoo!デベロッパーネットワーク
PDF
Yahoo! JAPANのサービス開発を10倍早くした社内PaaS構築の今とこれから
by
Yahoo!デベロッパーネットワーク
PDF
Serverlessconf Tokyo 2017 Biz serverless お客様のビジネスを支える サーバーレスアーキテクチャーと開発としてのビジ...
by
Hiroyuki Hiki
PDF
Software Productivity and Serverless
by
Nick Gottlieb
PDF
[serverlessconf2017]FaaSで簡単に実現する数十万RPSスパイク負荷試験
by
Takahiro Moteki
PDF
now
by
Hiroyuki Hara
PDF
Pythonと機械学習によるWebセキュリティの自動化
by
Isao Takaesu
PDF
BluetoothメッシュによるIoTシステムを支えるサーバーレス技術 #serverlesstokyo
by
Masahiro NAKAYAMA
PPTX
Step functionsとaws batchでオーケストレートするイベントドリブンな機械学習基盤
by
Yu Yamada
PDF
Cassandra Explained
by
Eric Evans
PDF
データテクノロジースペシャル:Yahoo! JAPANにおけるメタデータ管理の試み
by
Yahoo!デベロッパーネットワーク
PDF
Lecture univ.tokyo 2017_okanohara
by
Preferred Networks
PDF
Docker最新動向2017秋+セキュリティの落とし穴
by
Masahito Zembutsu
エンジニアなら知っておきたい「仮想マシン」のしくみ v1.1 (hbstudy 17)
by
Takeshi HASEGAWA
普通の人でもわかる Paxos
by
tyonekura
Google Dremel
by
maruyama097
Yahoo!ブラウザーアプリのプロダクトマネージャーが考えていること
by
Yahoo!デベロッパーネットワーク
行列ができるECサイトの悩み~ショッピングや決済の技術的問題と処方箋
by
Yahoo!デベロッパーネットワーク
ヤフオク!の快適なカスタマー体験を支えるモバイルアプリのライブアップデート技術
by
Yahoo!デベロッパーネットワーク
市場で勝ち続けるための品質とテストの技術①
by
Yahoo!デベロッパーネットワーク
市場で勝ち続けるための品質とテストの技術②
by
Yahoo!デベロッパーネットワーク
Yahoo! JAPANのサービス開発を10倍早くした社内PaaS構築の今とこれから
by
Yahoo!デベロッパーネットワーク
Serverlessconf Tokyo 2017 Biz serverless お客様のビジネスを支える サーバーレスアーキテクチャーと開発としてのビジ...
by
Hiroyuki Hiki
Software Productivity and Serverless
by
Nick Gottlieb
[serverlessconf2017]FaaSで簡単に実現する数十万RPSスパイク負荷試験
by
Takahiro Moteki
now
by
Hiroyuki Hara
Pythonと機械学習によるWebセキュリティの自動化
by
Isao Takaesu
BluetoothメッシュによるIoTシステムを支えるサーバーレス技術 #serverlesstokyo
by
Masahiro NAKAYAMA
Step functionsとaws batchでオーケストレートするイベントドリブンな機械学習基盤
by
Yu Yamada
Cassandra Explained
by
Eric Evans
データテクノロジースペシャル:Yahoo! JAPANにおけるメタデータ管理の試み
by
Yahoo!デベロッパーネットワーク
Lecture univ.tokyo 2017_okanohara
by
Preferred Networks
Docker最新動向2017秋+セキュリティの落とし穴
by
Masahito Zembutsu
Similar to 分散システムについて語らせてくれ
PPTX
Distributed Systems 第1章 Introduction
by
aomori ringo
PDF
[DI06] 並列分散処理の考え方とオープンソース分散処理系の動向
by
de:code 2017
PDF
[de:code 2017] 並列分散処理の考え方とオープンソース分散処理系の動向
by
Naoki (Neo) SATO
PPTX
Paxos
by
nobu_k
PDF
NTTデータ流 Hadoop活用のすすめ ~インフラ構築・運用の勘所~
by
NTT DATA OSS Professional Services
PDF
分散システム処理モデルの課題および展望#yjdsw3
by
Yahoo!デベロッパーネットワーク
PDF
[db tech showcase Tokyo 2014] D17:こだわろう、一貫性! はじめよう、分散KVS!! ~分散KVSの弱点と、それを克服する...
by
Insight Technology, Inc.
PDF
マイニング探検会#10
by
Yoji Kiyota
PDF
クラウドを支える基盤技術の最新動向と今後の方向性
by
Masayoshi Hagiwara
PDF
20191010 Blockchain GIG #5 石原様資料
by
オラクルエンジニア通信
PDF
ブロックチェーンPoCにおける開発リードタイム短縮のポイント
by
LFDT Tokyo Meetup
PPTX
大規模分散システムの現在 -- Twitter
by
maruyama097
PPTX
モデル検査入門 #wacate
by
Kinji Akemine
PPTX
Cloudera大阪セミナー 20130219
by
Cloudera Japan
PDF
Principles of Transaction Processing Second Edition 7章 1, 2節
by
Yuichiro Saito
PDF
Enterprise Cloud Design Pattern 前編:クラウドアーキテクチャ-の3要素
by
Arichika TANIGUCHI
PPTX
第2章アーキテクチャ
by
Kenta Hattori
PDF
分散処理基盤ApacheHadoop入門とHadoopエコシステムの最新技術動向(OSC2015 Kansai発表資料)
by
NTT DATA OSS Professional Services
PDF
Storm×couchbase serverで作るリアルタイム解析基盤
by
NTT Communications Technology Development
PDF
2009 splc-relating requirements and feature configurations a systematic approach
by
n-yuki
Distributed Systems 第1章 Introduction
by
aomori ringo
[DI06] 並列分散処理の考え方とオープンソース分散処理系の動向
by
de:code 2017
[de:code 2017] 並列分散処理の考え方とオープンソース分散処理系の動向
by
Naoki (Neo) SATO
Paxos
by
nobu_k
NTTデータ流 Hadoop活用のすすめ ~インフラ構築・運用の勘所~
by
NTT DATA OSS Professional Services
分散システム処理モデルの課題および展望#yjdsw3
by
Yahoo!デベロッパーネットワーク
[db tech showcase Tokyo 2014] D17:こだわろう、一貫性! はじめよう、分散KVS!! ~分散KVSの弱点と、それを克服する...
by
Insight Technology, Inc.
マイニング探検会#10
by
Yoji Kiyota
クラウドを支える基盤技術の最新動向と今後の方向性
by
Masayoshi Hagiwara
20191010 Blockchain GIG #5 石原様資料
by
オラクルエンジニア通信
ブロックチェーンPoCにおける開発リードタイム短縮のポイント
by
LFDT Tokyo Meetup
大規模分散システムの現在 -- Twitter
by
maruyama097
モデル検査入門 #wacate
by
Kinji Akemine
Cloudera大阪セミナー 20130219
by
Cloudera Japan
Principles of Transaction Processing Second Edition 7章 1, 2節
by
Yuichiro Saito
Enterprise Cloud Design Pattern 前編:クラウドアーキテクチャ-の3要素
by
Arichika TANIGUCHI
第2章アーキテクチャ
by
Kenta Hattori
分散処理基盤ApacheHadoop入門とHadoopエコシステムの最新技術動向(OSC2015 Kansai発表資料)
by
NTT DATA OSS Professional Services
Storm×couchbase serverで作るリアルタイム解析基盤
by
NTT Communications Technology Development
2009 splc-relating requirements and feature configurations a systematic approach
by
n-yuki
More from Kumazaki Hiroki
PDF
An overview of query optimization in relational systems 論文紹介
by
Kumazaki Hiroki
PPTX
トランザクション入門
by
Kumazaki Hiroki
PPTX
Cache obliviousの話
by
Kumazaki Hiroki
PPT
Jubatus hackathon2
by
Kumazaki Hiroki
PPTX
キャッシュコヒーレントに囚われない並列カウンタ達
by
Kumazaki Hiroki
PPTX
What is jubatus (short)
by
Kumazaki Hiroki
PPTX
What is jubatus? How it works for you?
by
Kumazaki Hiroki
PPTX
よくわかるHopscotch hashing
by
Kumazaki Hiroki
PPTX
MerDy
by
Kumazaki Hiroki
PPT
Bloom filter
by
Kumazaki Hiroki
PDF
SkipGraph
by
Kumazaki Hiroki
PPT
Lockfree list
by
Kumazaki Hiroki
PPT
Lockfree Priority Queue
by
Kumazaki Hiroki
PPT
Lockfree Queue
by
Kumazaki Hiroki
An overview of query optimization in relational systems 論文紹介
by
Kumazaki Hiroki
トランザクション入門
by
Kumazaki Hiroki
Cache obliviousの話
by
Kumazaki Hiroki
Jubatus hackathon2
by
Kumazaki Hiroki
キャッシュコヒーレントに囚われない並列カウンタ達
by
Kumazaki Hiroki
What is jubatus (short)
by
Kumazaki Hiroki
What is jubatus? How it works for you?
by
Kumazaki Hiroki
よくわかるHopscotch hashing
by
Kumazaki Hiroki
MerDy
by
Kumazaki Hiroki
Bloom filter
by
Kumazaki Hiroki
SkipGraph
by
Kumazaki Hiroki
Lockfree list
by
Kumazaki Hiroki
Lockfree Priority Queue
by
Kumazaki Hiroki
Lockfree Queue
by
Kumazaki Hiroki
分散システムについて語らせてくれ
1.
Copyright©2016 NTT Corp.
All Rights Reserved. 分散システムについて 語らせてくれ 日本電信電話株式会社 ソフトウェアイノベーションセンタ 熊崎 宏樹 (@kumagi)
2.
Copyright©2016 NTT Corp.
All Rights Reserved. 2 1.分散自体を目的にしない事 2.論文を読んでそのまま実装しない事 3.Two Phase Commitを使わない事 4.手を動かす事 目次 分散システムを作る際に気をつけて欲しい事
3.
Copyright©2016 NTT Corp.
All Rights Reserved. 3 • よくわかってない人でもCloudera Managerをダウンロードして1時間後 には巨大なHadoopクラスタを立ち上げてYARN, HDFS, Spark, HBase などで遊ぶ事ができる。 • 世の中では分散システムが必要以上に喧伝されている • 「コンピュータ1台よりも2台の方が高速」という直感に対して反論するの は意外と難しい • あなたのそのシステム、本当に分散システムじゃないとダメ? 分散自体を目的にしない事
4.
Copyright©2016 NTT Corp.
All Rights Reserved. 4 L1 キャッシュ参照 分岐予測ミス L2 キャッシュ参照 Mutexのlock/unlock メモリ参照 1KBをZIP圧縮 1Gbpsで2KB送る メモリから1MB連続で読む 同一のデータセンタ内のマシンと通信1往復 HDDシーク HDDから1MB読み出し カリフォルニアとオランダ間で通信1往復 システムの肌感覚を掴め 0.5 ns 5 ns 7 ns 25 ns 100 ns 3,000 ns 20,000 ns 250,000 ns 500,000 ns 10,000,000 ns 20,000,000 ns 150,000,000 ns みんなが知っているべき数値 by Jeff Dean
5.
Copyright©2016 NTT Corp.
All Rights Reserved. 5 L1 キャッシュ参照 分岐予測ミス L2 キャッシュ参照 Mutexのlock/unlock メモリ参照 1KBをZIP圧縮 1Gbpsで2KB送る メモリから1MB連続で読む 同一のデータセンタ内のマシンと通信1往復 HDDシーク HDDから1MB読み出し カリフォルニアとオランダ間で通信1往復 システムの肌感覚を掴め 0.5 ns 5 ns 7 ns 25 ns 100 ns 3,000 ns 20,000 ns 250,000 ns 500,000 ns 10,000,000 ns 20,000,000 ns 150,000,000 ns みんなが知っているべき数値 by Jeff Dean
6.
Copyright©2016 NTT Corp.
All Rights Reserved. 6 分散システム化すると基本的に遅くなる。 大抵はネットワークが遅延の支配項になる。 速くなる場合のほうがむしろ例外的と思ったほうが良い。 ワークロードと照らし合わせてマイクロベンチを取った 後で分散システム化を検討して欲しい(頼むから実装上 の重要な意思決定で分散ミドルウェアを使用する事を目 的にしないで欲しい) システムの肌感覚を掴め とにかく測れ 測らずに分散システム化するのは Early Optimizationの一種
7.
Copyright©2016 NTT Corp.
All Rights Reserved. 7 • 分散システムの論文は多く出ているがその大半は「やってみたレポート」 「作ってみた」→「動いたっぽい」→「測った」→「Yappy!」 • 分散システム界隈の研究は過去の研究の蓄積が蓄積扱いされにくい分野の 一つであり、論文を真に受けてはならない • 他にそう感じる研究分野はHCI分野 • 故障モデルなどが実は結構厳しく規定されており、そこを読み飛ばすと痛 い目に遭う 論文を読んでそのまま実装しない事
8.
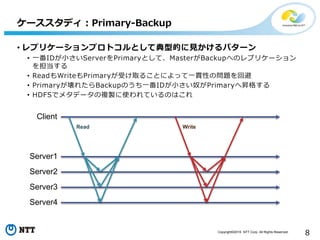
Copyright©2016 NTT Corp.
All Rights Reserved. 8 • レプリケーションプロトコルとして典型的に見かけるパターン • 一番IDが小さいServerをPrimaryとして、MasterがBackupへのレプリケーション を担当する • ReadもWriteもPrimaryが受け取ることによって一貫性の問題を回避 • Primaryが壊れたらBackupのうち一番IDが小さい奴がPrimaryへ昇格する • HDFSでメタデータの複製に使われているのはこれ ケーススタディ:Primary-Backup Client Server1 Server2 Server3 Server4 Read Write
9.
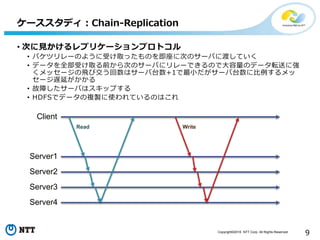
Copyright©2016 NTT Corp.
All Rights Reserved. 9 • 次に見かけるレプリケーションプロトコル • バケツリレーのように受け取ったものを即座に次のサーバに渡していく • データを全部受け取る前から次のサーバにリレーできるので大容量のデータ転送に強 くメッセージの飛び交う回数はサーバ台数+1で最小だがサーバ台数に比例するメッ セージ遅延がかかる • 故障したサーバはスキップする • HDFSでデータの複製に使われているのはこれ ケーススタディ:Chain-Replication Client Server1 Server2 Server3 Server4 Read Write
10.
Copyright©2016 NTT Corp.
All Rights Reserved. 10 プロトコル名 通信遅延数 メッセージ数 Primary-Backup 4回 2N個 Chain-Replication N+1回 N+1個 ケーススタディ: Primary-Backup と Chain-Replication • 通信の特性を見極めて最適なプロトコルを使おう • Primary-Backupは「細かくて素早い」特性 • Chain-Replicationは「時間が掛かっても通信効率が良い」特性 • どちらもサーバが故障する場合は縮退運転していき、最小1台でも稼動は する
11.
Copyright©2016 NTT Corp.
All Rights Reserved. 11 ちょっと待った
12.
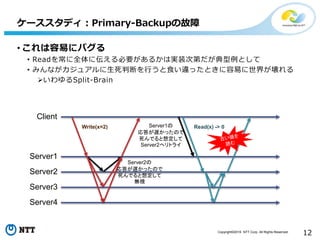
Copyright©2016 NTT Corp.
All Rights Reserved. 12 • これは容易にバグる • Readを常に全体に伝える必要があるかは実装次第だが典型例として • みんながカジュアルに生死判断を行うと食い違ったときに容易に世界が壊れる いわゆるSplit-Brain ケーススタディ:Primary-Backupの故障 Client Server1 Server2 Server3 Server4 Write(x=2) Read(x) -> 0 Server2の 応答が遅かったので 死んでると想定して 無視 Server1の 応答が遅かったので 死んでると想定して Server2へリトライ
13.
Copyright©2016 NTT Corp.
All Rights Reserved. 13 間違った実装が世界を揺るがす • 「Redis Sentinelという自動レプリケーションの仕組みを作りました。 最強です(キリッ」 • しかし特定の実行パターンによって内容物の半分以上が失われる • Jepsen Testが築く屍の山 • 様々な分散ミドルウェアで 意図的にSplit-Brain状態を引き起こして挙動を確認する一連のブログポス ト群:Call me maybe • 面白いぐらい多くのシステムが次々と壊れていく (生き残ったのはZK, Riak, etcd, consulぐらい? • 興味のある人はぜひURL参照 https://aphyr.com/tags/jepsen
14.
Copyright©2016 NTT Corp.
All Rights Reserved. 14 • サーバが壊れた場合の挙動をどうするかは論文に書いてあるけれど、何が 起きたらサーバが壊れたと認識するかは書いてない • これらのプロトコルはサーバの故障情報を天から与えられる物として設計している • プログラマ「そっか、じゃあ通信がタイムアウトしたら故障ね」←バグの温床 • プログラマ「タイムアウトの閾値を大きくすれば誤検知が減って安心だね」←低速化 • プログラマ「タイムアウトの閾値をどうすればいいのさ??」←決定解はない • 分散システムの論文ではシステムに対して前提を置いていることが多いが、 なぜその前提を置いているのかは知識がないとわからない • Primary-BackupとChain-ReplicationはFail-Stop故障モデルを前提 としている • それより厳しい故障モデルの上では容易に壊れる • その故障モデルの解説はこれからする そのプロトコル、凶暴につき
15.
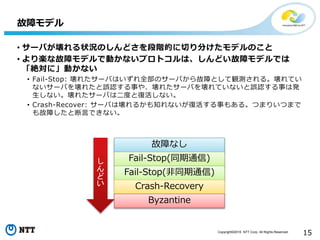
Copyright©2016 NTT Corp.
All Rights Reserved. 15 故障なし • サーバが壊れる状況のしんどさを段階的に切り分けたモデルのこと • より楽な故障モデルで動かないプロトコルは、しんどい故障モデルでは 「絶対に」動かない • Fail-Stop: 壊れたサーバはいずれ全部のサーバから故障として観測される。壊れてい ないサーバを壊れたと誤認する事や、壊れたサーバを壊れていないと誤認する事は発 生しない。壊れたサーバは二度と復活しない。 • Crash-Recover: サーバは壊れるかも知れないが復活する事もある。つまりいつまで も故障したと断言できない。 故障モデル し ん ど い Fail-Stop(同期通信) Fail-Stop(非同期通信) Crash-Recovery Byzantine
16.
Copyright©2016 NTT Corp.
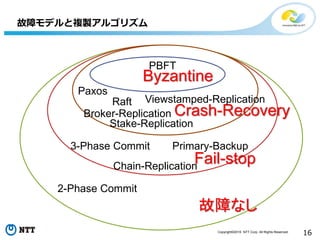
All Rights Reserved. 16 故障モデルと複製アルゴリズム 故障なし Fail-stop Crash-Recovery Byzantine 2-Phase Commit 3-Phase Commit Paxos Raft Primary-Backup Chain-Replication Viewstamped-Replication Broker-Replication Stake-Replication PBFT
17.
Copyright©2016 NTT Corp.
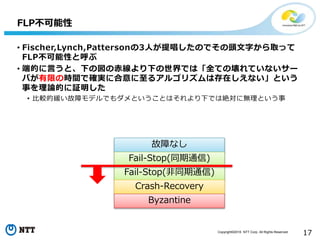
All Rights Reserved. 17 • Fischer,Lynch,Pattersonの3人が提唱したのでその頭文字から取って FLP不可能性と呼ぶ • 端的に言うと、下の図の赤線より下の世界では「全ての壊れていないサー バが有限の時間で確実に合意に至るアルゴリズムは存在しえない」という 事を理論的に証明した • 比較的緩い故障モデルでもダメということはそれより下では絶対に無理という事 FLP不可能性 故障なし Fail-Stop(同期通信) Fail-Stop(非同期通信) Crash-Recovery Byzantine
18.
Copyright©2016 NTT Corp.
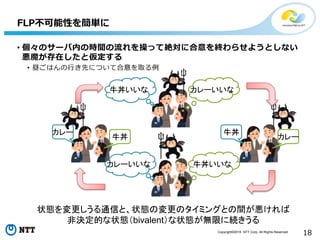
All Rights Reserved. 18 • 個々のサーバ内の時間の流れを操って絶対に合意を終わらせようとしない 悪魔が存在したと仮定する • 昼ごはんの行き先について合意を取る例 FLP不可能性を簡単に 状態を変更しうる通信と、状態の変更のタイミングとの間が悪ければ 非決定的な状態(bivalent)な状態が無限に続きうる カレー 牛丼 牛丼 カレー 牛丼いいな カレーいいな カレーいいな 牛丼いいな
19.
Copyright©2016 NTT Corp.
All Rights Reserved. 19 • 分散システムの問題が複数ある中、それぞれはお互いに「帰着」しあう事 ができる • 合意問題が解ければリーダー選出ができる(リーダーを誰にするかに合意する) • リーダー選出ができれば合意問題が解ける(リーダーが決めた値に全員従う) • 合意問題が解ければアトミックブロードキャストができる(順序について合意する) • アトミックブロードキャストができれば合意問題が解ける(最初の値で合意する) • 合意問題が解ければState Machine Replicationが解ける(Multi Paxos的な) • Replicated State Machineが解ければ合意問題が解ける(合意するステートマシン を作ればよい) などなど • その中で「合意問題が解けない」は他の全ての問題も有限の時間では解けな い事を意味する • みんな無限の時間が掛かりうるから適当に迂回するなり諦めるなりしている FLP不可能性の意味する大事な所
20.
Copyright©2016 NTT Corp.
All Rights Reserved. 20 •全員の参加者から「同じ順序」が観測できるブロード キャスト • 単一のリーダーから全員に送る、というのも立派な一つの解 • 参加者がそれぞれバラバラの順序で受信したブロードキャスト メッセージを、同一の順序で観測し直すように合意する、という 方法もある 個々のアルゴリズムは詳しくないのでまた今度 補足:アトミックブロードキャスト ZooKeeperはZookeeper Atomic Bloadcast(ZAB)プロトコル を使っている。
21.
Copyright©2016 NTT Corp.
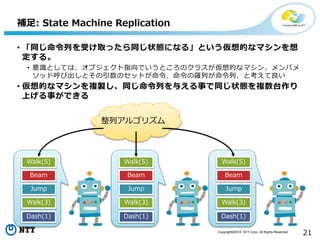
All Rights Reserved. 21 • 「同じ命令列を受け取ったら同じ状態になる」という仮想的なマシンを想 定する。 • 意識としては、オブジェクト指向でいうところのクラスが仮想的なマシン、メンバメ ソッド呼び出しとその引数のセットが命令、命令の羅列が命令列、と考えて良い • 仮想的なマシンを複製し、同じ命令列を与える事で同じ状態を複数台作り 上げる事ができる 補足: State Machine Replication Walk(5) Beam Jump Walk(3) Dash(1) Walk(5) Beam Jump Walk(3) Dash(1) Walk(5) Beam Jump Walk(3) Dash(1) 整列アルゴリズム
22.
Copyright©2016 NTT Corp.
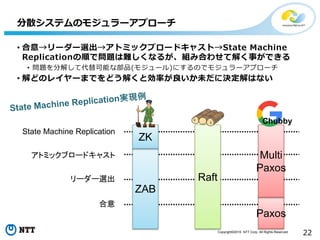
All Rights Reserved. 22 • 合意→リーダー選出→アトミックブロードキャスト→State Machine Replicationの順で問題は難しくなるが、組み合わせて解く事ができる • 問題を分解して代替可能な部品(モジュール)にするのでモジュラーアプローチ • 解どのレイヤーまでをどう解くと効率が良いか未だに決定解はない 分散システムのモジュラーアプローチ State Machine Replication アトミックブロードキャスト リーダー選出 合意 ZAB ZK Raft Paxos Multi Paxos Chubby
23.
Copyright©2016 NTT Corp.
All Rights Reserved. 23 •まともな論文であれば分散システムの歴史に立脚してい るはず •その歴史の中でそのアプローチはどの立ち位置なのか、 問題をどう分解しているのかを理解してから実装する (尺が足りないから話せないFailure Detectorとか Syncronizationとかの問題の話はまた今度) 論文を読んでそのまま実装しない事
24.
Copyright©2016 NTT Corp.
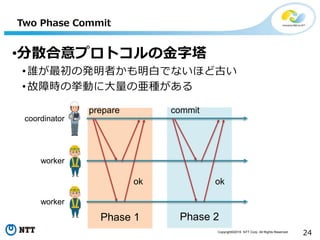
All Rights Reserved. 24 Phase 2 Two Phase Commit •分散合意プロトコルの金字塔 •誰が最初の発明者かも明白でないほど古い •故障時の挙動に大量の亜種がある prepare ok commit ok coordinator worker worker Phase 1
25.
Copyright©2016 NTT Corp.
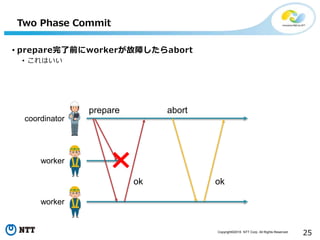
All Rights Reserved. 25 Two Phase Commit • prepare完了前にworkerが故障したらabort • これはいい prepare ok abort ok coordinator worker worker
26.
Copyright©2016 NTT Corp.
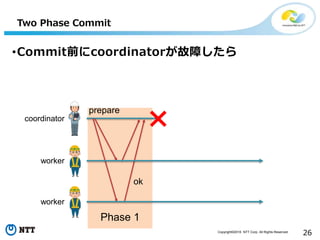
All Rights Reserved. 26 Two Phase Commit prepare ok coordinator worker worker Phase 1 •Commit前にcoordinatorが故障したら
27.
Copyright©2016 NTT Corp.
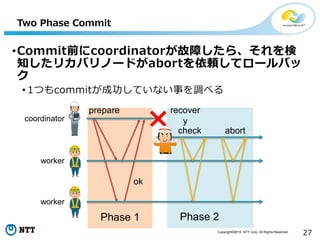
All Rights Reserved. 27 Phase 2 Two Phase Commit •Commit前にcoordinatorが故障したら、それを検 知したリカバリノードがabortを依頼してロールバッ ク • 1つもcommitが成功していない事を調べる prepare ok recover ycoordinator worker worker Phase 1 check abort
28.
Copyright©2016 NTT Corp.
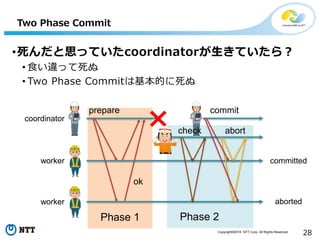
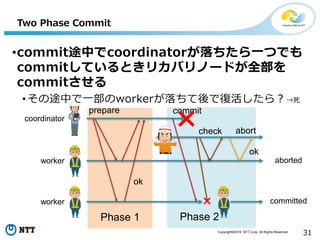
All Rights Reserved. 28 Phase 2 Two Phase Commit •死んだと思っていたcoordinatorが生きていたら? • 食い違って死ぬ • Two Phase Commitは基本的に死ぬ prepare ok coordinator worker worker Phase 1 abort commit committed aborted check
29.
Copyright©2016 NTT Corp.
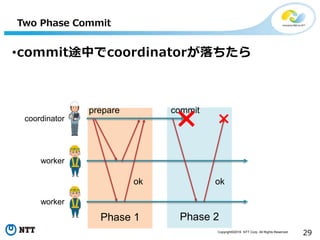
All Rights Reserved. 29 Phase 2 Two Phase Commit •commit途中でcoordinatorが落ちたら prepare ok commit ok coordinator worker worker Phase 1
30.
Copyright©2016 NTT Corp.
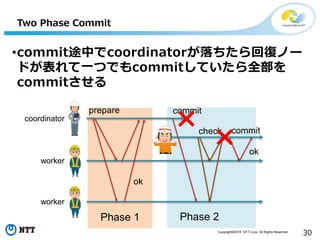
All Rights Reserved. 30 Phase 2 Two Phase Commit •commit途中でcoordinatorが落ちたら回復ノー ドが表れて一つでもcommitしていたら全部を commitさせる prepare ok commit coordinator worker worker Phase 1 commitcheck ok
31.
Copyright©2016 NTT Corp.
All Rights Reserved. 31 Phase 2 Two Phase Commit •commit途中でcoordinatorが落ちたら一つでも commitしているときリカバリノードが全部を commitさせる •その途中で一部のworkerが落ちて後で復活したら?→死 prepare ok commit coordinator worker worker Phase 1 abortcheck ok committed aborted
32.
Copyright©2016 NTT Corp.
All Rights Reserved. 32 Two Phase Commit •Two Phase Commitは故障したり復活したりするとす ぐ壊れる •回復中に壊れるパターンや回復ノードが壊れるパターンま で挙げだすと壊せるシナリオは山ほど出てくる •弱点を補強したという触れ込みの3 Phase Commitなん てものもあるけどやはり壊れている •GoogleのChubbyの開発者Mike Burrows「合意プロ トコルは一つしかない。Paxosだ」(≒他の合意プロトコ ルは全て合意不能) 覚えていただきたい事実: 2 Phase Commitはバグっている
33.
Copyright©2016 NTT Corp.
All Rights Reserved. 33 •「Paxosっていうアルゴリズムがあるんですが…説明す るには難しいのでまた今度にします」←分散システムに ついて語る人あるある •Paxos怖くないよ!合意しかできないだけだよ! 分散システムあるある
34.
Copyright©2016 NTT Corp.
All Rights Reserved. 34 Paxos •Lamport先生が「参加者の故障や復活がある場合絶対 に合意には至れない」ということを証明しようとして逆 に生み出してしまった合意プロトコル • 実は故障に耐える合意プロトコルは他にもviewstamped replicationと かstake replicationとかいろいろあるが、きっちり証明されたのは Paxosが最初 出典:http://lamport.azurewebsites.net/pubs/pubs.html#lamport-paxos Lamport先生 最近はTLA+の布教にお熱
35.
Copyright©2016 NTT Corp.
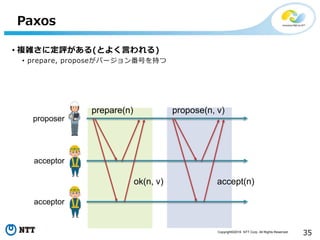
All Rights Reserved. 35 Paxos • 複雑さに定評がある(とよく言われる) • prepare, proposeがバージョン番号を持つ prepare(n) ok(n, v) propose(n, v) accept(n) proposer acceptor acceptor
36.
Copyright©2016 NTT Corp.
All Rights Reserved. 36 Paxos • Coordinator • prepare(n)に対して過半数からok(n,v)が貰えたらその中で最大のnに対するvを全 workerに投げる このvがnullなら自分自身のvを使う nullでないならvは生死不明な他のCoordinatorのvである • Acceptor • 過去に見たprepare(n)のうち最大のnであればそれにok(n,v)を返す。そうでなけれ ばng(n') vは過去に一度も合意してない場合nullかも知れない • Learner • 確定した値を読みに来る。Acceptorに最新の値vを訊きに来る。 • 過半数のAcceptorが同じ値を返さない限り、値が読めた(確定した)事にならない • Learnerが観測するフェーズまで含めるとPaxosはThree Phaseある事になる 25行で説明するPaxos: http://nil.csail.mit.edu/6.824/2015/notes/paxos-code.html
37.
Copyright©2016 NTT Corp.
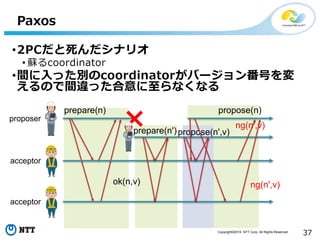
All Rights Reserved. 37 Paxos •2PCだと死んだシナリオ • 蘇るcoordinator •間に入った別のcoordinatorがバージョン番号を変 えるので間違った合意に至らなくなる prepare(n) ok(n,v) proposer acceptor acceptor propose(n',v) propose(n) prepare(n') ng(n',v) ng(n',v)
38.
Copyright©2016 NTT Corp.
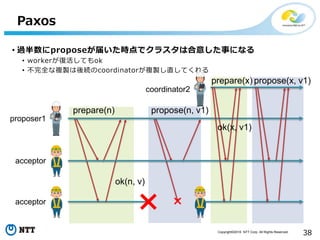
All Rights Reserved. 38 Paxos • 過半数にproposeが届いた時点でクラスタは合意した事になる • workerが復活してもok • 不完全な複製は後続のcoordinatorが複製し直してくれる prepare(n) ok(n, v) propose(n, v1) proposer1 acceptor acceptor coordinator2 prepare(x) ok(x, v1) propose(x, v1)
39.
Copyright©2016 NTT Corp.
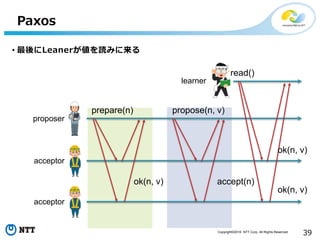
All Rights Reserved. 39 Paxos • 最後にLeanerが値を読みに来る prepare(n) ok(n, v) propose(n, v) accept(n) proposer acceptor acceptor learner read() ok(n, v) ok(n, v)
40.
Copyright©2016 NTT Corp.
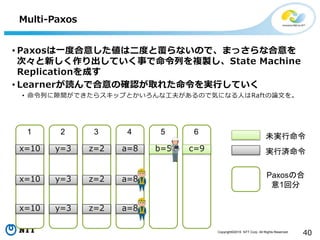
All Rights Reserved. 40 Multi-Paxos • Paxosは一度合意した値は二度と覆らないので、まっさらな合意を 次々と新しく作り出していく事で命令列を複製し、State Machine Replicationを成す • Learnerが読んで合意の確認が取れた命令を実行していく • 命令列に隙間ができたらスキップとかいろんな工夫があるので気になる人はRaftの論文を。 未実行命令 実行済命令x=10 x=10 x=10 1 y=3 y=3 y=3 2 z=2 z=2 z=2 3 a=8 a=8 a=8 4 b=5 5 c=9 6 Paxosの合 意1回分
41.
Copyright©2016 NTT Corp.
All Rights Reserved. 41 •In Search of an Understandable Consensus Algorithmという衝撃的なタイトルで登場したRaft • Understandableの価値を学会に認めさせるために苦労したのだとか • Paxosが合意(Consensus)しか解いてないのに対し、Raftは 合意はもちろんState Machine Replicationも解ける(=多く の分散アルゴリズム問題に帰着できる) • Googlerは合意アルゴリズムに過ぎないPaxosをロックマネージャ等へ 帰着させるのに大変な苦労をしたが、SMRから帰着させるのはずっと楽 であるという目論見 • PaxosのProposerとLearnerの両方をRaftのLeaderが兼ね ている点がすごい(Multi-Paxos的な高速化をしやすい) RaftとPaxosの類似性
42.
Copyright©2016 NTT Corp.
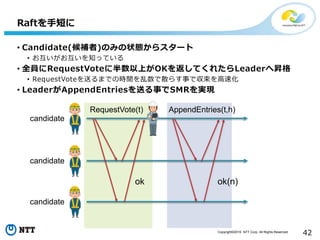
All Rights Reserved. 42 • Candidate(候補者)のみの状態からスタート • お互いがお互いを知っている • 全員にRequestVoteに半数以上がOKを返してくれたらLeaderへ昇格 • RequestVoteを送るまでの時間を乱数で散らす事で収束を高速化 • LeaderがAppendEntriesを送る事でSMRを実現 Raftを手短に RequestVote(t) ok AppendEntries(t,h) ok(n) candidate candidate candidate
43.
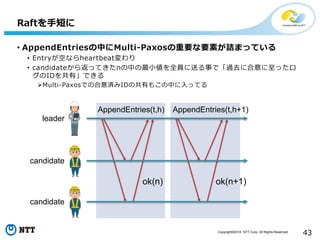
Copyright©2016 NTT Corp.
All Rights Reserved. 43 Raftを手短に AppendEntries(t,h+1) ok(n+1) candidate candidate leader • AppendEntriesの中にMulti-Paxosの重要な要素が詰まっている • Entryが空ならheartbeat変わり • candidateから返ってきたnの中の最小値を全員に送る事で「過去に合意に至ったロ グのIDを共有」できる Multi-Paxosでの合意済みIDの共有もこの中に入ってる AppendEntries(t,h) ok(n)
44.
Copyright©2016 NTT Corp.
All Rights Reserved. 44 Raftを手短に •AppendEntries • Leader「みんなー、Team 13番のリーダーだよ。前回のログの IDは同じTerm13の38だったね。39のログの内容はXXXだよ。 過去にみんなに合意してもらえたIDの最小値は36までだからス テートマシンは36まで進めて良いよ。」 •RequestVote • Candidate「Leader死んでる気がするから僕が立候補します。 前回のログはTerm13の46だったよ。」 •これら2つのRPCだけでMulti-Paxosに相当する事が実 現できるように練りこまれたのがRaft • 過去の合意の観測(PaxosでいうLearnerの仕事)を、Leaderが同 時に行ってRPCの中に折りたたんでいるのがかっこいい。
45.
Copyright©2016 NTT Corp.
All Rights Reserved. 45 •分散システムエアプ勢多すぎる • ポンチ絵とにらめっこし続ける会議をヤメロ •既成品を使うだけではなく、一緒に血反吐吐き ながらコード書きましょう • コードを書かないと見えてこないものはいっぱいある • システムの肌感覚を掴んでこそエンジニア 手を動かせ
Download






























































![[serverlessconf2017]FaaSで簡単に実現する数十万RPSスパイク負荷試験](https://cdn.slidesharecdn.com/ss_thumbnails/faasrps-171104115940-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DI06] 並列分散処理の考え方とオープンソース分散処理系の動向](https://cdn.slidesharecdn.com/ss_thumbnails/di06-170605024555-thumbnail.jpg?width=640&height=640&fit=bounds)
![[de:code 2017] 並列分散処理の考え方とオープンソース分散処理系の動向](https://cdn.slidesharecdn.com/ss_thumbnails/20170524decode17di06hdinsight-170702125017-thumbnail.jpg?width=640&height=640&fit=bounds)



![[db tech showcase Tokyo 2014] D17:こだわろう、一貫性! はじめよう、分散KVS!! ~分散KVSの弱点と、それを克服する...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014d17kvskvs-150126023353-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)


























