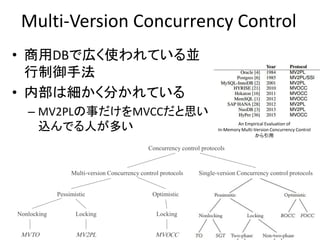
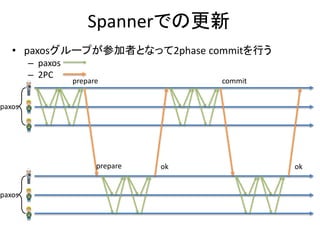
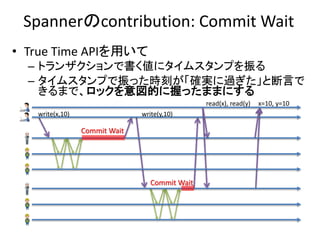
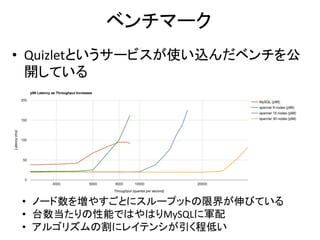
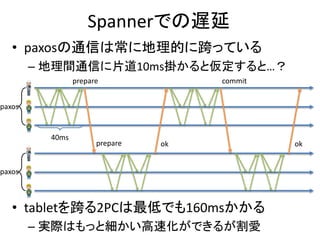
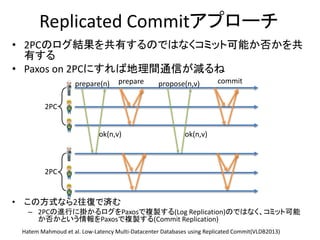
Multi-Version Concurrency Control
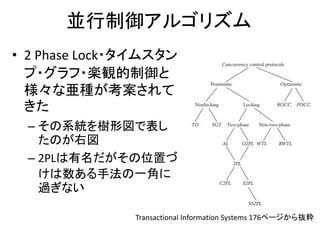
•商用DBで広く使われている並
行制御手法
• 内部は細かく分かれている
– MV2PLの事だけをMVCCだと思い
込んでる人が多い
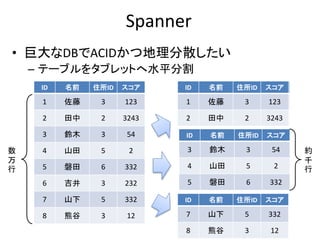
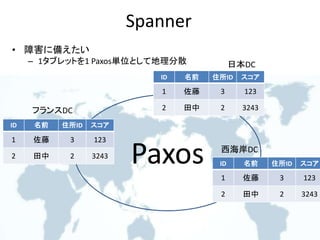
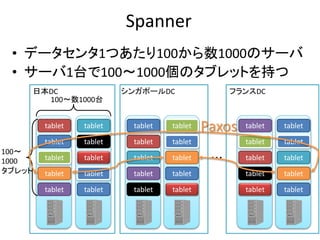
Concurrency control protocols
Single-version Concurrency control protocolsMulti-version Concurrency control protocols
An Empirical Evaluation of
In-Memory Multi-Version Concurrency Control
から引用
OptimisticPessimistic
Nonlocking Locking Locking
MV2PLMVTO MVOCC
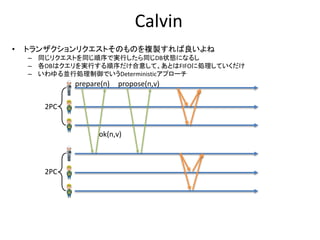
8.
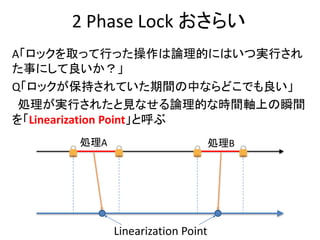
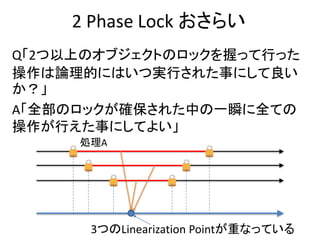
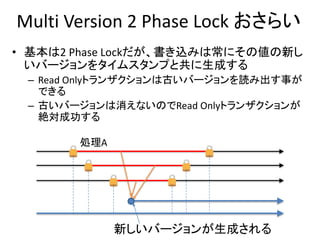
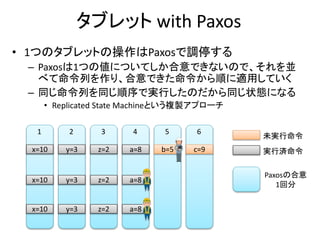
Multi Version 2Phase Lock おさらい
• 基本は2 Phase Lockだが、書き込みは常にその値の新し
いバージョンをタイムスタンプと共に生成する
– Read Onlyトランザクションは古いバージョンを読み出す事が
できる
– 古いバージョンは消えないのでRead Onlyトランザクションが
絶対成功する
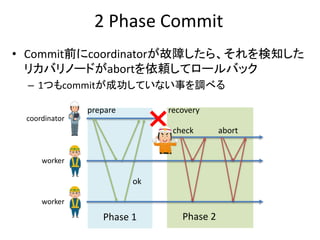
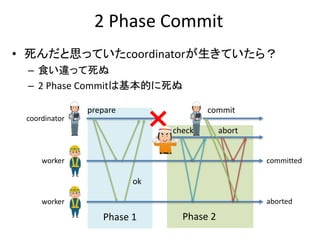
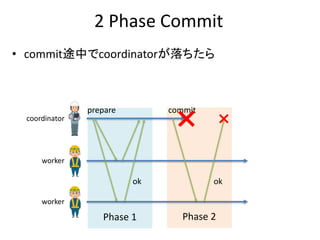
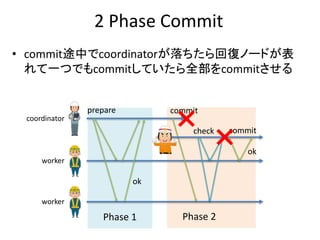
処理A
新しいバージョンが生成される


![トランザクションの基本
• トランザクションとは:CommitかAbortで終わる
複数の手続きの塊
– 例 [Read(x) Read(y) Write(y) Commit]
• トランザクションマネージャとは:トランザクショ
ンを複数並行して流し込んでも、何らかの順序
で一つずつ直列に流し込んだかのような結果を
生み出すシステム
– トランザクションマネージャの中では主に並行制御
アルゴリズムが使われる](https://image.slidesharecdn.com/db-170428160930/85/DB-2-320.jpg)