Download as PDF, PPTX








![{
AST demo (Esprima)
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"declarations": [
{
"id": {
"type": "Identifier",
"name": "foo"
},
"init": {
"type": "BinaryExpression", var foo = bar + 1;
"operator": "+",
"left": {
"type": "Identifier",
"name": "bar"
},
"right": {
"type": "Literal",
"value": 1
}
}
}
],
"kind": "var"
}
}
]
http://esprima.org/demo/parse.html](https://image.slidesharecdn.com/virtual-machine-and-javascript-engine-111221000420-phpapp01/85/Virtual-machine-and-javascript-engine-10-320.jpg)


![Bytecode (JSC)
8 m_instructions; 168 bytes at 0x7fc1ba3070e0;
1 parameter(s); 10 callee register(s)
[ 0] enter
[ 1] mov! ! r0, undefined(@k0)
[ 4] get_global_var! r1, 5
[ 7] mov! ! r2, undefined(@k0)
[ 10] mov! ! r3, 2(@k1)
[ 13] call!! r1, 2, 10
function foo(bar) { [ 17] op_call_put_result! ! r0
return bar + 1; [ 19] end! ! r0
} Constants:
k0 = undefined
foo(2); k1 = 2
3 m_instructions; 64 bytes at 0x7fc1ba306e80;
2 parameter(s); 1 callee register(s)
[ 0] enter
[ 1] add! ! r0, r-7, 1(@k0)
[ 6] ret! ! r0
Constants:
k0 = 1
End: 3](https://image.slidesharecdn.com/virtual-machine-and-javascript-engine-111221000420-phpapp01/85/Virtual-machine-and-javascript-engine-13-320.jpg)

![Stack vs. register
local a,t,i 1: PUSHNIL 3
a=a+i 2: GETLOCAL 0 ; a
3: GETLOCAL 2 ; i
4: ADD
local a,t,i 1: LOADNIL 0 2 0
5: SETLOCAL 0 ; a
a=a+i 2: ADD 0 0 2
a=a+1 6: SETLOCAL 0 ; a
a=a+1 3: ADD 0 0 250 ; a
7: ADDI 1
a=t[i] 4: GETTABLE 0 1 2
8: SETLOCAL 0 ; a
a=t[i] 9: GETLOCAL 1 ; t
10: GETINDEXED 2 ; i
11: SETLOCAL 0 ; a](https://image.slidesharecdn.com/virtual-machine-and-javascript-engine-111221000420-phpapp01/85/Virtual-machine-and-javascript-engine-15-320.jpg)


![Direct threading
typedef void *Inst; mov 0xffffffffffffffe8(%rbp),%rdx
Inst program[] = { &&ADD, &&SUB }; lea 0xffffffffffffffe8(%rbp),%rax
Inst *ip = program; addq $0x8,(%rax)
goto *ip++; mov %rdx,0xffffffffffffffd8(%rbp)
jmpq *0xffffffffffffffd8(%rbp)
ADD:
... ADD:
goto *ip++; ...
mov 0xffffffffffffffe8(%rbp),%rdx
SUB: lea 0xffffffffffffffe8(%rbp),%rax
... addq $0x8,(%rax)
goto *ip++; mov %rdx,0xffffffffffffffd8(%rbp)
jmp 2c <interpreter+0x2c>
http://gcc.gnu.org/onlinedocs/gcc/Labels-as-Values.html](https://image.slidesharecdn.com/virtual-machine-and-javascript-engine-111221000420-phpapp01/85/Virtual-machine-and-javascript-engine-18-320.jpg)









![Solution: Inline Threading
ICONST_1_START: *sp++ = 1;
ICONST_1_END: goto **(pc++);
INEG_START: sp[-1] = -sp[-1];
INEG_END: goto **(pc++);
DISPATCH_START: goto **(pc++);
DISPATCH_END: ;
size_t iconst_size = (&&ICONST_1_END - &&ICONST_1_START);
size_t ineg_size = (&&INEG_END - &&INEG_START);
size_t dispatch_size = (&&DISPATCH_END - &&DISPATCH_START);
void *buf = malloc(iconst_size + ineg_size + dispatch_size);
void *current = buf;
memcpy(current, &&ICONST_START, iconst_size); current += iconst_size;
memcpy(current, &&INEG_START, ineg_size); current += ineg_size;
memcpy(current, &&DISPATCH_START, dispatch_size);
...
goto **buf;
Interpreter? JIT!](https://image.slidesharecdn.com/virtual-machine-and-javascript-engine-111221000420-phpapp01/85/Virtual-machine-and-javascript-engine-29-320.jpg)
















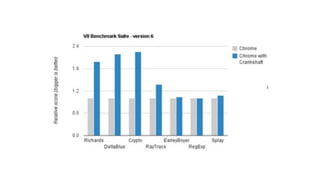
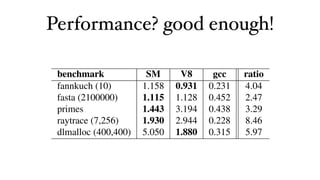
![in Figure 5, reads are far more common than writes: over all
Write_indx
roughly comparable to me
1.
Write_prop Read_prop
0.8
traces the proportion of reads to writes is 6 to 1. Deletes comprise
Write_hash Read_hash class-based languages, suc
Write_indx Read_indx
only .1% of all events. That graph further breaks reads, writes
Write_prop Read_prop Delet_prop ric discussed in [23]. Studi
But property are rarely deleted and deletes into various specific types; prop Delet_hash to accesses
refers
0.8
Write_hash Read_hash
DIT of 8 and a median of
0.6
Write_indx Read_indx Delet_indx
Write_prop Read_prop Delet_prop Define and maximum of 10. Figu
Write_hash Read_hash
Write_indx Read_indx
Delet_hash
Delet_indx
Create
Call median prototype chain le
0.6
10
Write_prop Read_prop Delet_prop Define Throw chain length 1, the minimu
0.4
Write_hash Read_hash Delet_hash Create Catch
Write_indx Read_indx Delet_indx Call have at least one prototyp
Read_prop Define
Object.prototype. The m
1.0
Delet_prop Throw
9
0.4
Read_hash Delet_hash Create Catch
is 10. The majority of site
0.2
Read_indx Delet_indx Call
Delet_prop Define Throw
Delet_hash Create Catch reuse, but this is possibly
8
0.8
Delet_indx Call to achieve code reuse in J
0.2
Define Throw
0.0
Create Catch sures directly into a field o
prototypes have similar in
7
Call
280s
Fbok
Apme
Bing
Blog
Digg
Flkr
Gmai
Gmap
Lvly
Twit
Wiki
Goog
IShk
Word
Ebay
YTub
All*
Prototype chain length
Throw
0.6
0.4 Flkr 0.0
Catch
Only 0.1% delete
5.4 Object Kinds
280s
Fbok
Gmai
Gmap
Lvly
Twit
Wiki
Apme
Bing
Blog
Digg
Goog
IShk
Word
Ebay
YTub
All*
6
280S
BING
BLOG
EBAY
FBOK
DIGG
FLKR
GMIL
GMAP
GOGL
ISHK
LIVE
MECM
TWIT
ALL*
WIKI
WORD
YTUB
Figure 7 breaks down the
Fbok
Bing
Blog
Digg
Flkr
Gmai
Gmap
Lvly
Twit
Wiki
Goog
IShk
Word
Ebay
YTub
All*
into a number of categorie
5
built-in data types: dates (D
Fbok
Gmap
Lvly
Twit
Wiki
Flkr
Gmai
Goog
IShk
Word
Ebay
YTub
All*
0.2
ument and layout objects
4
rors. The remaining objec
Lvly
Twit
Wiki
Goog
IShk
Word
Ebay
0.0 YTub
All*
mous objects, instances, fu
jects are constructed with a
3
Figure 5. Instruction mix. The per-site proportion of read, write, while instances are constr
280S
BING
BLOG
EBAY
FBOK
LIVE
ALL*
DIGG
FLKR
GMIL
GMAP
GOGL
ISHK
MECM
TWIT
WIKI
WORD
YTUB
delete, call instructions (averaged over multiple traces). A function object is creat
2
An Analysis of the Dynamic Behavior ofthe interpreter a
uated by JavaScript Programs](https://image.slidesharecdn.com/virtual-machine-and-javascript-engine-111221000420-phpapp01/85/Virtual-machine-and-javascript-engine-50-320.jpg)
















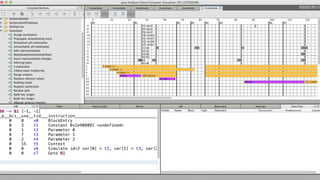
![Built-in objects written in JS
function ArraySort(comparefn) {
if (IS_NULL_OR_UNDEFINED(this) && !IS_UNDETECTABLE(this)) {
throw MakeTypeError("called_on_null_or_undefined",
["Array.prototype.sort"]);
}
// In-place QuickSort algorithm.
// For short (length <= 22) arrays, insertion sort is used for efficiency.
if (!IS_SPEC_FUNCTION(comparefn)) {
comparefn = function (x, y) {
if (x === y) return 0;
if (%_IsSmi(x) && %_IsSmi(y)) {
return %SmiLexicographicCompare(x, y);
}
x = ToString(x);
y = ToString(y);
if (x == y) return 0;
else return x < y ? -1 : 1;
};
}
...
v8/src/array.js](https://image.slidesharecdn.com/virtual-machine-and-javascript-engine-111221000420-phpapp01/85/Virtual-machine-and-javascript-engine-73-320.jpg)



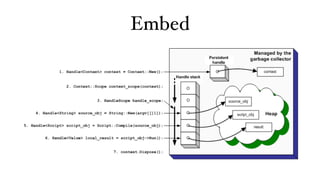
![Expose Function
v8::Handle<v8::Value> Print(const v8::Arguments& args) {
for (int i = 0; i < args.Length(); i++) {
v8::HandleScope handle_scope;
v8::String::Utf8Value str(args[i]);
const char* cstr = ToCString(str);
printf("%s", cstr);
}
return v8::Undefined();
}
v8::Handle<v8::ObjectTemplate> global = v8::ObjectTemplate::New();
global->Set(v8::String::New("print"), v8::FunctionTemplate::New(Print));](https://image.slidesharecdn.com/virtual-machine-and-javascript-engine-111221000420-phpapp01/85/Virtual-machine-and-javascript-engine-80-320.jpg)







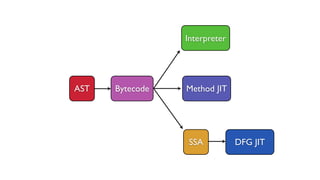







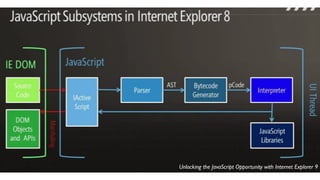
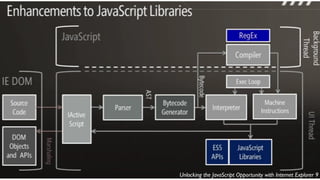







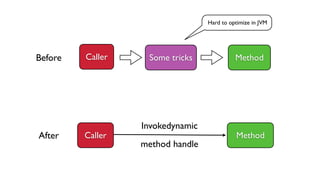












![...
function _foo($bar) {
define i32 @foo(i32 %bar) nounwind readnone ssp {
var __label__;
entry:
var $0=((($bar)+1)|0);
%0 = add nsw i32 %bar, 1
return $0;
ret i32 %0
}
}
function _main() {
define i32 @main() nounwind readnone ssp {
var __label__;
entry:
return undef;
ret i32 undef
}
}
Module["_main"] = _main;
...](https://image.slidesharecdn.com/virtual-machine-and-javascript-engine-111221000420-phpapp01/85/Virtual-machine-and-javascript-engine-121-320.jpg)














The document discusses virtual machines and JavaScript engines. It provides a brief history of virtual machines from the 1970s to today. It then explains how virtual machines work, including the key components of a parser, intermediate representation, interpreter, garbage collection, and optimization techniques. It discusses different approaches to interpretation like switch statements, direct threading, and inline threading. It also covers compiler optimizations and just-in-time compilation that further improve performance.

















































![reductio [ad absurdum]](https://cdn.slidesharecdn.com/ss_thumbnails/taualywhssudecboubib-signature-40f4714a7511dbefb3f8b81978ee26a52b8bc17a56b46da771a1d673a5b4d7df-poli-170804175449-thumbnail.jpg?width=640&height=640&fit=bounds)























