Download as PDF, PPTX



































![NLP (Natural Language Processing): [continued…]
Entity disambiguation: how to determine which entity is being
referred to; e.g. “Amazon” can be the rainforest in South America,
or the online store
Sentiment analysis: identifying the mood/attitude/emotion of a
statement
Tools & techniques: enriching the data](https://image.slidesharecdn.com/webinar19092018-knowledgegraphs-thepowerofgraph-basedsearch-180919142734/85/Knowledge-Graphs-The-Power-of-Graph-Based-Search-40-320.jpg)



![Inferencing / deriving new facts: deductive method [continued..]
Use external data sources to obtain new facts; e.g. hook into a
thesaurus to deduce/derive synonyms (ConceptNet, WordNet, ..)
Use the graph to deduce a set of rules (or begin with a seed set,
using ML) which enrich the graph, and subsequently enrich the
rules as more data gets added to the graph: feedback loop
Tools & techniques: enriching the data](https://image.slidesharecdn.com/webinar19092018-knowledgegraphs-thepowerofgraph-basedsearch-180919142734/85/Knowledge-Graphs-The-Power-of-Graph-Based-Search-44-320.jpg)


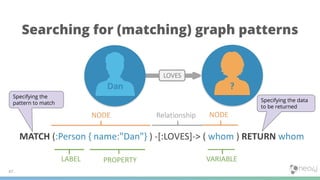
![// Pattern description (ASCII art)
MATCH (me:Person)-[:FRIEND]->(friend)
// Filtering with predicates
WHERE me.name = ‘Frank Black’ AND friend.age > me.age
// Projection of expressions
RETURN toUpper(friend.name) AS name, friend.title AS title
// Order results
ORDER BY name, title DESC
Variable-length relationship patterns
MATCH (me)-[:FRIEND*]-(foaf) // Traverse 1 or more FRIEND relationships
MATCH (me)-[:FRIEND*2..4]-(foaf) // Traverse 2 to 4 FRIEND relationships
// Path binding returns all paths (p)
MATCH p = (a)-[:ONE]-()-[:TWO]-()-[:THREE]-()
// Each path is a list containing the constituent nodes and relationships, in order
RETURN p
DQL: reading data
Input: a property graph
Output: a table
This tells you why the answer was returned (going
back to the context a Knowledge Graph provides)](https://image.slidesharecdn.com/webinar19092018-knowledgegraphs-thepowerofgraph-basedsearch-180919142734/85/Knowledge-Graphs-The-Power-of-Graph-Based-Search-48-320.jpg)




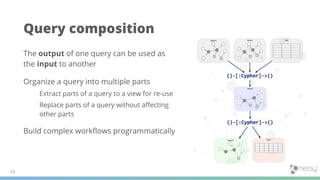



![PATH PATTERN
older_friends = (a)-[:FRIEND]-(b) WHERE b.age >
a.age
MATCH p=(me)-/~older_friends+/-(you)
WHERE me.name = $myName AND you.name = $yourName
RETURN p AS friendship
Path Pattern: example](https://image.slidesharecdn.com/webinar19092018-knowledgegraphs-thepowerofgraph-basedsearch-180919142734/85/Knowledge-Graphs-The-Power-of-Graph-Based-Search-57-320.jpg)

![MATCH (p:Person {name: Jack})-[r1:FRIEND]-()-[r2:FRIEND]-(friend_of_a_friend)
RETURN friend_of_a_friend.name AS fofName
+---------+
| fofName |
+---------+
| “Tom” |
+---------+
Cypher today
:Person
{ name : Jack }
:Person
{ name : Anne }
:Person
{ name : Tom }
:FRIEND :FRIEND
Usefulness proven in practice over
multiple industrial verticals
r1 and r2 may not be
bound to the same
relationship within the
same pattern
Rationale was to avoid potentially
returning infinite results for varlength
patterns when matching graphs
containing cycles (this would have been
different if we were just checking for the
existence of a path)
r1 r2](https://image.slidesharecdn.com/webinar19092018-knowledgegraphs-thepowerofgraph-basedsearch-180919142734/85/Knowledge-Graphs-The-Power-of-Graph-Based-Search-59-320.jpg)






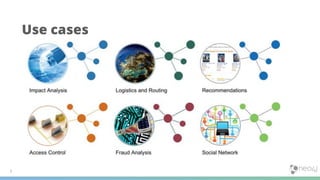
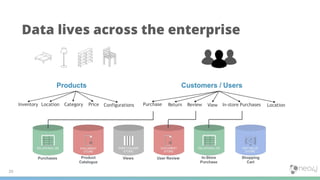
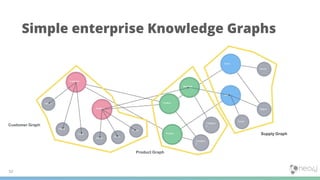
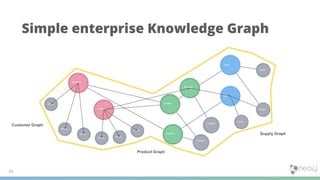
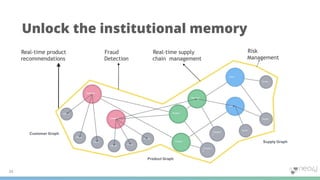
1) Knowledge graphs are graphs that are enriched with data over time, resulting in graphs that capture more detail and context about real world entities and their relationships. This allows the information in the graph to be meaningfully searched. 2) In Neo4j, knowledge graphs are built by connecting diverse data across an enterprise using nodes, relationships, and properties. Tools like natural language processing and graph algorithms further enrich the data. 3) Cypher is Neo4j's graph query language that allows users to search for graph patterns and return relevant data and paths. This reveals why certain information was returned based on the context and structure of the knowledge graph.






































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
















