2. 3.5.4 성향 모델링
응답 및 업리프트 모델링
닮은꼴 모델링의 한계:
- 특정한 액션의 무조건적인 확률 추정
- 프로모션이 제공되지 않더라도 구매할 고객들이 프로모션 타겟에 포함됨.
- Score가 높더라도, 실제 운영 시 uplift는 낮을 수 있다.
마케팅 커뮤니케이션을 특징에 추가
Treatment가 주어졌을 때 조건적 확률을 구하는 모델을 만들 수 있다.
- 파일럿 캠페인을 통해 통제그룹을 만듦 ( non- treatment)
- 타겟 / 논 타겟을 랜덤하게 고름
Uplift (실험그룹 응답률 – 통제그룹 응답률) 최대화하는 모델
3. 방법
1) 두개의 확률 각각 모델링, 예측
2) 하나의 모델로 예측. (better)
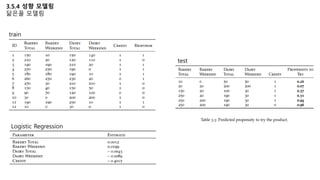
Logistic Regression
-
I(T) = 1 if targeted else 0
4개 그룹에 대해 단일 multinomial model로 추정.
가장 높은 uplift를 가진 고객을 타겟팅 함으로 ROI 최대화.
Pr(R|x) – 단일모델로 추정
Pr(T) / Pr(C) – 주어짐.
3.5.4 성향 모델링
응답 및 업리프트 모델링
4. Segmentation의 결과
-> segment profile
& segment model (= clustering model)
3.5.5 세그멘테이션과 페르소나 기반 모델링
segment profile
- 특징적인 세그먼트의 성질 및 지표와 전형적인 고객 페르소나가 어떻게 설명되는지에 대한 해석을 포함.
- 각 그룹에 대한 통계적 지표 (clustering model로 도출되기 때문)
행동기반 segmentation vs RFM
RFM: 고객을 재무적 결과에 의해 나눔
Segmentation: 결과를 초래하는 특성 파악
페르소나 태그는 고객 행동에 관한 중요한 시그널이다.
5. 3.5.6 생존 분석을 이용한 타겟팅
성향 모델링 한계
- 사건의 확률은 사건까지의 시간으로 표현되지 않음. (활용성 low)
ex. 고객이 할인을 받으면 10일 이내에 구매할것을 5일 내에 구매할것으로 바뀌는것이
할인을 받으면 구매확률이 80%라는 정보보다 유용하다.
- 응답 레이블을 만들기 위해 필요한 결과를 항상 관찰하지 않음
ex. Train data에 ‘이탈하지 않음‘은 ‘아직 이탈하지 않음’을 포함한다. (사실 이탈하지 않음이라는 상태만을 표현하지 않는다)
0, 1이 아닌 구매 까지 시간으로 표
시됨.
S(t): (프로모션 후 구매하지 않은 상태의)
생존 함수
6. 3.5.6 생존 분석을 이용한 타겟팅
As the survival function can be obtained for any
combination of the independent variables, we can
estimate the average or median time-to-purchase
for each customer separately and then use these
values in marketing rules (e. g., send a notification
one day before the expected time-of-purchase) or
targeting scores (e. g., target the ten percent of
customers with the longest expected time to
purchase)
7. 3.5.7 생애가치 모델링
LTV모델링의 목적
- 고객의 브랜드 사용 생애동안 고객의 (수입관점) 가치 추정
서술적 분석
1) Basic: 미래의 특정 기간동안 평균 기대이익의 총합.
T: 시간 (월)
R: 고객당 평균 기대 매출
C: 고객당 평균 기대 비용
- 고객유지 비율을 고려하지 않음
- 화폐 할인율 고려 x (현재 화폐가 미래 가치보다 높음)
2) 표준적 정의: 고객유지 비율 r, 할인율 d 도입
r=0.8 : t마다 고객 20% 이탈.
d=0.15: t후에 화폐가치=현재
x1.15
8. 3.5.7 생애가치 모델링
서술적 분석
3) 순이익 증가 모형:브랜드와 고객의 관계가 성숙해짐에 따라 순이익 증가.
m0: 시작 시점 순이익
mM: 최대 순이익
m_{t}로 R-C를 대체함.
한계: 고객의 성질과 마케팅 액션이 어떻게 LTV에 영향을 미치는지
는 예측하지 못함.
9. 3.5.7 생애가치 모델링
마크로프 체인 모델
동시에 여러 단계가 섞여있다
(고객여정 = 고객 유치 + 최대화 + 유지상태)
-> 마코프 체인으로 모델링!
The idea of this approach is to define the set of customer states based on observed
customer properties, such as recency of purchase, estimate the probabilities of
transition between the different states and the corresponding profits and losses, and
then estimate the LTV based on the expected customer path in the state graph [Pfeifer
and Carraway, 2000].
10. 3.5.7 생애가치 모델링
마크로프 체인 모델
column vector G so that the net profit of the i-th state corresponds to its i-th
element:
Consequently, the LTV can be estimated as a sum of such expected values over
several time periods
11. 3.5.7 생애가치 모델링
회귀 모델
마크로프 체인 모델의 한계
- 고객 성질이 추가 될 때마다 상태의 수 기하급수적으로 증가. (모든 상태 전환
경우의 수를 유지해야함)
-> 개념적으로
LTV = 브랜드에 머물 확률 * 기대 순이익 으로 표현됨.
위를 서술적으로 하면 정적인 유지비율과 평균 이익으로 예측,
마코프 체인과 같은 확률적 모델링을 하려면, 각 요소에 대해 회귀 모델을
적용하는 것.
* Su(t): 고객의 생존 함수
- 고객이 이탈하는 시점을 추정하도록 훈련
- 이탈사건 정의
- 직접 측정 (ex. 고객이 서비스 해지)
- 비즈니스 규칙에 의해 휴리스틱 측정 (휴면고객)
* m(u, t): 각 고객 세그먼트에 대한 평균 순이익 값 추정
12. 3.6 캠페인 디자인과 운영
3.6.1 고객 여정
타겟팅 + LTV모델 = 마케팅 의사 결정의 기초
마케팅 캠페인은 여러 액션과 의사결정으로 이뤄진 흐름.
여러 개의 모델이 합쳐지고 여러 시그널과 제약 조건이 고려된 최적화들이 동시에 이뤄져야한다.
이 흐름은 여러 타겟팅 모델 + 예산의 제약 + 고객의 경험 특징으로 모수화됨.
고객 생애주기 소매업체와 고객의 상호작용
브랜드 레벨의 관심과 목표 장기적이고 우월한 고객경험 제공 필요
트랜잭션 단위 (구매, 클릭) 소매 업체와 고객과의 상호작용 (이벤
트 접촉 – 상품 연구 – 상품 검색 – 구
매결정 –배송 경험 – 구매후기 등 일련
의 사건들)
마케팅 캠페인은 고객의 여정에 영향을 미치려 함.
프로그램 기반 시스템은 캠페인 템플릿의 저장소를 보유하고
각 템플릿은 언제 캠페인 액션이 유발되고
어떻게 상황을 처리해야 하는지 관한 법칙
그에 대해 요구하는 액션에 대한 모수를 추정 & 예측하는 모델 포함.
시스템의 책임은 템플릿 모수의 추정 및 최적화, 그리고 최적 템플릿의 동
적인 선택
13. 3.6.2 제품 프로모션 캠페인
신규 고객 유치 동일 카테고리 구매가 많은 고객에게 우리 브랜드
도 써보세요!
소비 최대화 캠페인 기존 고객에게 3개 구매 시 1달러 할인
고객 유지 캠페인 기존 구매에 비해 구매량 줄어든 고객에게 프로모
션
응답 모델링 프레임워크로 어떤 고객이 응답확률이 높은지를 통해 고객 선
정 가능.
그 외 고려할 사항:
• 3.6.2.1. 타깃팅 과정
• 예산, 프로모션 모수 선택 (3.6.2.2. 예산 수립과 최대빈도 제한)
• 특정 제품에 대한 판매 프로모션.
ex. 할인쿠폰, 1+1쿠폰, 체험 샘플
• 구매 유발(프로모션)과 구매(쿠폰상환)로 이뤄지는 간단한 고객 여정에 대응.
• 모든 마케팅 목적에 부합.
14. 3.6.2 제품 프로모션 캠페인
타깃팅 과정
응답 모델링 프레임워크로 어떤 고객이 응답확률이 높은지를 통해 고객 선
정 가능.
그 외 고려할 사항:
• 3.6.2.1. 타깃팅 과정
• 예산, 프로모션 모수 선택 (3.6.2.2. 예산 수립과 최대빈도 제한)
타깃팅 모드
1) Batch: 프로모션이 제공될 고객 리스트가 미리 준비되어 있어야함.
2) Real-time: 변하는 고객 프로파일, 맥락에 유연하게 대응 가능.
- Batch 모드의 모의 실험 기능도 가능.
여기서는 Realtime (실시간) 타깃팅을 다룸.
Hard targeting 특정 상황 및 고객에게 유효한 프로모션 고르기: 비
즈니스 룰과 조건에 의해 초기 필터링.
Soft targeting (프로모션의) 점수를 생산하는 예측 모델을 사용하
여 프로모션 정렬
Thresholding 한계점 선정 예산 수립과 최대빈도 제한
15. 3.6.2 제품 프로모션 캠페인
타깃팅 과정
[하드 타겟팅]
목표: 특정 상황에 합당한 프로모션을 고르는 것.
구매수량 조건 고객이 특정 제품, 브랜드, 카테고리에서 일정 수량 이상을 구매할 때 프로모션 실행
Ex. 안마의자 3개 구매 시 하나 더! 는 무의미하다. 고가 안마의자를 3개씩 사는 경우는 거의 없음.
첫 구매 조건 특정 기간동안 특정 제품이나 브랜드를 구매하지 않았던 고객에게 프로모션 시행.
Ex. 배달의민족 안써본 사람을 찾습니다.
채널 조건 특정 채널을 통해 소통할 때 프로모션 시행
Ex. BBQ 네고왕 – BBQ앱을 통해서만 할인 받음
리타겟팅 조건 이전에 제공됐거나 상환됐던 프로모션에 기반을 두고 시행.
ex. ?
위치 조건 고객 위치 정보에 따라 프로모션 시행
ex. 유튜브 지역광고
구매 가능 조건 재고 없거나 특정채널 판매 안되면 프로모션 대상x
[소프트 타겟팅]
The goal of the soft-targeting stage is to select the most relevant offers and filter out options that are likely
to be inefficient. Soft targeting is often done by using propensity models.
Scoring models can be combined with special conditions that complement the logic encapsulated in the
model. For instance, the basic look-alike acquisition model identifies customers who are similar to natural
triers, but it does not ensure that a promotion will not be offered to those who already buy the product. In
contrast, maximization and retention promotions typically should not be offered to customers who do not
consume the promoted product. These additional checks can be implemented as a condition.
16. 3.6.2 제품 프로모션 캠페인
예산 수립과 최대 빈도 제한
캠페인의 운영 몇가지 통제 사항 포함
1) 단일 캠페인에서 고객이 받을 수 있는 프로모션의 수와 고객에게 전달되는 커뮤니케이션 수는 제한되야함.
2) 캠페인 예산과 가능한 최대 프로모션의 수 제한
-> ROI를 최적화 하기 위해 프로모션 최적 개수 결정해야함.
[최대 예산 수립]
모든 고객을 스코어에 따라 정렬
고객들을 같은 크기의 버킷으로 나눠 순서대로 버킷에 넣음. ( 1 <= len(bucket) <= Population )
타깃팅 문제는 타깃팅 리스트에 들어갈 최적의 버킷 숫자를 결정하는 것 또는 최상위 버킷과 최하위 버킷을 구분
할 한곗값 점수를 찾는 것.
min Pr(R_{i}), (i in bucket)
uplift로 대체가능 (lift는 실제 운영시 캠페인 성과가 안좋을수도 있다)
17. 3.6.2 제품 프로모션 캠페인
예산 수립과 최대 빈도 제한
랜덤 전략은 손해 (프로모션당 1달러 비용 발생)
3번째 버킷까지만 이익.
30% 고객에 ROI 최대화.
-> 최대 예산을 사용하는 것은 ROI 최대화가 아니라
20,000달러의 손해가 발생.
(초대박 할인 행사를 전국에 하는게 꼭 이익은 아닐수도
있다)
18. 3.6.2 제품 프로모션 캠페인
예산 수립과 최대 빈도 제한
[예산 분배]
baseline – eps < actual rate < baseline + eps 가 되도록 하는
threshold 함수.
Pseudo code
19. 3.6.3 다단계 프로모션 캠페인
타깃팅 시스템이 기본적인 통계를 갖고 다른 프로모션 모수를 평가하고 캠페인 결과를 예측 할수 있는지 알아보자.
H(q): 프로모션 제품을 q개 구매한 transaction count
보다 고객 여정에 장기적으로 영향을 주기 위해 3단계로 정교화.
• stage1: 오퍼에 대해 고객에 알려주는 단계 ex. 제품 X를 Q개 이상 사면 다음 구매시 할인 제공. 더 많이 살수록 더 절약
• stage2: 분배 - 고객은 타겟팅, 고객의 구매 수준에 따라 동적으로 쿠폰할인율 책정
• stage3: 상환 – 소비자는 이전에 얻은 쿠폰을 상환하기 위해 제품 구매
최소 구매량 Q = 3 -> 3개 이상 구매한 고객에게 쿠폰 발행
qi : 수량 at level i
di : 해당하는 할인 값
c : 쿠폰 발행 추가 비용
쿠폰 발행은 히스토그램 H(q)에 기반하여 예측
기대 상환 개수는 할인율을 특징으로 포함하는 응답모델( r(d) )에 의해 예측
수준 i에서의 쿠폰 비용은 다음과 같이 예측
20. 3.6.4 고객 유지 캠페인
• 신규 고객 유치 비용은 기존 고객의 유지비용보다 10~20배 -> 고객 유지가 더 쌈!
• LTV와 uplift를 더 중시함. (프로모션 캠페인과 비교)
1) 추가 연락은 고객 이탈을 촉진할 수 있음. (거슬림)
2) 이탈할 기회가 있다는 것을 알려주는 셈
[이탈 확률 기반 타겟팅]
고객 유지 캠페인의 기본적 접근: 이탈 확률을 기반으로 타깃팅하는 것
• 고객 유지 전략이 집중적
- 유지 offer를 받지 않을 때의 이탈확률 예측
• 고객 유지 전략이 포괄적
- 거의 모든 고객이 treatment를 받는다면 고객이 그
조건에서 이탈할 확률 예측
이탈까지 걸리는 시간을 예측하기 위해 생존 분석을 활용 할 수 있음.
21. 3.6.4 고객 유지 캠페인
이탈확률 기반은 캠페인의 장기적인 결과를 고려하지 않음.
[캠페인의 장기적 결과 계산: LTV]
• 유지 노력은 해당 고객의 LTV를 유지, 모든 이탈은 LTV를 잃는 것.
• 특정 고객에 대해: 이탈확률 X LTV = 기대 손해
기대손해가 높은 고객을 대상으로 고객 유지 프로모션을 진행.
(3.37)의 한계: 이탈 uplift를 계산하지 않음.
[고객 유지성 savability]
고객 유지 활동에 긍정적으로 반응할 확률을 예측
• uplift 모델들의 전형적인 단점을 가짐: uplift가 두 랜덤 변수로 이뤄지는 것에 따른 추정 값의 높은 분산이 포함.
• 손실 기댓값 기법과 결합하면
uplift > 0 :
treatment가 고객 유지에 부정적 효과.
uplift < 0 :
treatment가 고객 유지에 긍정적 효과.
22. 3.6.5 충전 Replenishment 캠페인
화장품, 필터 등 소모품을 충전하는 고객 대상 캠페인.
1) 제품 및 카테고리별 평균 구매 주기 예측
• 고객별로 최근 구매일을 바탕으로
• 평균 구매 주기가 도달한 고객에게 프로모션 보냄
• 보충 주기의 추정이 정확하지 않음
2) 고객간 주기의 차이를 고려
• 고객 세그먼트나 페르소나별로 추정값을 나눔
• 생존분석을 통해 구매 시기 추정 가능
• 생존시간에 영향을 미치는 요인들을 처방적으로 사용할 수 있음.
23. 3.7 자원 할당
3.7.1 채널에 따른 할당
타겟팅 최적화의 문제는 쿠폰 등과 같은 고객에게 할당할 자원이 제한됐을 때의 자원 할당 문제였음.
회사의 전체 자원에서 마케팅 활동에 얼마의 자원을 할당할지 등의 최적화는 다루지 않았었다. (예, 마케팅 vs 연구 자원)
-> 마케팅 활동에 자원 할당 최적화는 전략적으로 다뤄지지, 시스템에 의해 자동화 할 수 없음.
여기서는 그 외 채널에 따른 할당, 채널별 자원할당, 비즈니스 목표에 따른 자원 할당이 MMM (Marketing Mix Modeling) 기
법을 통해 해결되는지를 다룸.
[채널 믹스 모델링]
매출을 최대화 하기 위해서 여러 채널에 걸친 예산 할당을 최적화
채널에 따라 발생하는 매출 비율?
채널의 비용이 매출을 증가/감소 시키는가?
여러 채널의 최적 비용 분배는?
-> 채널 활동의 함수로 표현하는 회귀모델에 의해 해결
문제
1) 지연된 고객 응답 (delayed reward ? )
2) 이에 따라 여러 캠페인에 대한 응답은 누적적으로 관찰됨. (credit assignment? )
3) 채널활동의 강도와 응답의 크기의 관계는 포화효과 때문에 비선형
이런 효과를 반영하는 모델 : 애드스탁 Adstock 모델
The key assumption made by the adstock model is that each given sales period
retains a fraction of the previous stock of advertising xt : t동안 달러로 표현된 채널 활동 강도 (e.g. 메시지 개수)
yt : 매출
at : 채널 활동이 매출에 미치는 영향 = adstock
24. 3.7.1 채널에 따른 할당
x_{t}: t동안 달러로 표현된 메시지 개수
y_{t}: 매출
a_{t}: 채널 활동이 매출에 미치는 영향 = adstock
관찰된 비즈니스 지표는 adstock의 선형 함수로 추정됨
여러 n개 채널에 대하여 합하면
w: weight
c: baseline
c, 각 lambda_{i} x n개, n개의 w_{i} 추정 필요
관찰된 샘플 y_{t}에 대해 다음 문제를 풀면 모델 적합화
각 채널의 매출에 대한 상대적 공헌
입력 순서에 적용되는 smoothing filter = 시간에 따라 이전 활동의 영향이 감소됨
26. 3.7.1 채널에 따른 할당
앞선 모델은 선형모델. 포화효과에 따른 강도와 수요의 비선형성을 설명 못함.
[수확체감의 법칙 diminishing return]
마케팅 활동에 더 많은 비용을 쓰는 것은 어느 지점 이후에는 더 낮은 추가 수요를 만든다.
AdStock model은 강도 변수의 비선형 변환을 통해 이와 같은 포화효과 설명.
-> e.g. sigmoid function을 사용
s.t.
since xt >0, looks like:
수요의 계절성 과같은 추가 변수로 다항 분산 지연 polynomial distributed lag 같은 복잡한 모델도 있음.
sigmoid function
diminishing return
27. 3.7.2 목적에 따른 할당
3.6. 캠페인의 운영에서 프로모션의 목적에 따라 타깃팅을 최적화 할 수 있었음.
이번에는 전체적 ROI 최대화를 위해 각 목적에 예산을 어떻게 할당하는지 최적화를 다룸.
고객 유지비율은 LTV에 영향을 미치는 주요 요소
-> LTV는 고객 유지 비율의 함수로 간주
예산과 고객 유지 비율의 의존성
R : 고객 당 고객 유지 예산
rmax : 최대 고객 유지 비율의 추정 값
kr: 얼마나 비율이 최댓값에 빨리 근접하는지 나타내는 계수
고객 유치 비율 a를 고객 유치 예산의 함수로 표현
A: 고객당 유치 예산
amax : 최대 응답률의 추정값
Ka : 예산 변화에 대한 감도를 조정하는 모수
특정 고객에 대한 고객 유치 순이익은
28. 3.7.2 목적에 따른 할당
= 유치비율 x LTV(유지) – 잠재고객당 유치 비용
예산 A, R에 대한 최적화 문제는 다음과 같이 표현
결국 매출 최적화 문제.
= Npotential x 고객유치 순이익 + Ncurrent x LTV(유지비율)
29. Channel
Channel
Channel
3.8 온라인 광고
3.8.1 환경
온라인 광고에서는 기술적 인프라와 데이터 흐름이 매우 복잡하므로 비즈니스 목표는 기술적 능력과 한계에 대한 정확한 분
석 없이는 이해되거나 성취될 수 없다.
제품이나 서비스 판매. 광고 캠페인에 자금을 투자
광고주 / 에이전시: 브랜드를 대신해 광고 캠페인 운영
request
when inventory available
Publisher inventory 판매 (광고 구좌; slot) e.g. websites
광고주는 여러 채널을 통해 인터넷 사용자들 접촉.
e.g. 웹 페이지 배너, 검색 엔진 결과 페이지, 온라인 비
디오 광고 등
impressions and conversions are tracked by an attribution system.
(사용자, 시간, 광고주, impression) 쌍을 기록하는 개체.
채널을 통해 광고를 보는 사람.
광고 노출 = impression
결과
(converge or not)
buy the available ad slot and show the ad to the user - Vickrey (second price) auction / 실시간 입찰 프로세스
30. 3.8.2 목표와 Attribution
브랜드 비즈니스의 목표는 특정 고객과의 관계를 한수준에서 다른 수준으로 이동시키는 것
• 브랜드 인지
• 신규 고객 유치
• 리타겟팅: ex. 인지했지만, 안 사는 고객
브랜드와 광고주 계약의 중요한 특징
• The targeting and bidding processes should be driven by the business objective of the campaign (e. g. , brand
awareness, acquisition, or retargeting) and be restricted by additional rules such as brand safety.
• The effect of the campaign should be measurable, and the metrics should accurately reflect the value added by the
advertiser. – uplift 모델과 연관
• It should be possible to answer the above question about advertiser removal for the case of multiple advertisers
working for the same brand. Credits should be attributed to advertisers proportionally to their contribution to the
total value increment.
[신규 고객당 비용cost per acquisition, CPA]
브랜드 관점에서 캠페인의 전반적 효율 측정 metric
전체 캠페인 비용
전체 컨버젼 수
[Conversion?]
1) impression 이후 액션을post-view action 세는 것
2) 클릭당 비용cost per click, CPC 모델: 광고의 클릭 횟수를 세는것
비용
conversion rate
31. 3.8.2 목표와 Attribution
비용
conversion rate
[신규 고객당 비용cost per acquisition, CPA]
광고주의 마진 = 브랜드가 지불한 가격 - RTB에서 이뤄진 입찰가격
입찰가격 Cbid는 CR의 영향을 받으므로 CR과 Cbid 의 동시 최적화 요구
[복수의 광고주가 있을 경우의 attribution]
credit assignment 문제를 어떻게 해결할 것인가?
-> Last touch attributionLT: 마지막 impression에 모든 credit을 줌
CPA-LT 모델의 한계
• 비즈니스 목적이 리타깃팅 쪽에 치우쳐있음. (구매할 확률이 높은 소비자를 대상으로 하기 때문)
• uplif보다 respond에 최적화.
- no-impression에 응답하는 고객은 ROI 최적화 측면에서는 안 좋음.
• 광고주가 꼼수 쓰도록 함. 싼 slot에 최대한 많이 광고를 꽂으면, 최대한 많은 사용자에게 노출되고, credit을 받을 수 있다.
- aka 융단폭격
advertiser
brand
32. 3.8.3 CPA-LT 모델 타깃팅
CPA-LT 모델 타깃팅의 기본 목표는 광고 노출 직후에 conversion 할거같은 고객을 인지하는 것.
방법1. 랜덤 유저에 대한 랜덤 타겟팅:
- 랜덤 입찰을 해서 훈련 데이터를 만듦
- 비용이 비쌈
실용적인 방안: 단계적 타깃팅 방법론
three sequential steps: calculate the brand proximity, incorporate the ad response, and incorporate the inventory quality
and calculate the bid amount.
33. 3.8.3 CPA-LT 모델 타깃팅
브랜드 근접성
• 방문 URL을 특징으로 간주하고, 컨버전을 비조건적 브랜드 근접성에 대한 레이블로 사용한 닮은꼴 모델링
• 실제 광고 응답에 대한 데이터가 없는 캠페인 초기에 사용자를 스코어링하기 위해 사용
광고 응답 모델링
• 광고 a에 대한 조건적 컨버전 확률 Pr(Y | u, a)를 추정하는 것.
• 이전 단계의 결과를 다차원 URL 대신 특징으로 사용함 -> 학습 프로세스 효율up
입찰
• 최적 입찰 가격은 컨버전 가치 v(Y)의 기댓값으로 계산된다.
URLi: 1 if visited else 0
ϕui : user의 i번째 브랜드 근접성
fui : user의 i번째 추가 특징 (브라우저 종
류, 위치.. )
bui : user의 i번째 브랜드 근접성
fui : user의 i번째 추가 특징 (브라우저 종
류, 위치.. )
34. 3.8.3 CPA-LT 모델 타깃팅
입찰
인벤토리 품질과 입찰
인벤토리 품질은 impression의 맥락이 됨
• 사용자의 구매 의도와 광고의 적합성 정보 보유. e.g. 호텔 광고 컨버전 야놀자 > 연합뉴스
• 광고의 인식은 상황에 의존한다. e.g. 스크롤 많이 해야 볼수있는 경우
scaling function s1, s2의 기울기는 는 CPA와 컨버전 비율 사이의 균형을 결정한다.
bbase : v(Y) (const) 를 포함하는 basline bid price
s1(.) : scaling func; can map all scores below a certain
threshold to zero (no bidding),
35. 3.8.4 다접촉 애트리뷰션 multi-touch attribution
LT의 맹점은 마지막 impression 이전의 노력은 무시된다는 것이다.
컨버전 이전에 사용자가 거쳐갈수있는 다양한 상태의 네트워크
causal graph / Bayesian network
채널 Ck
채널 Ck의 인과관계
Ws,k :사용자가 특정 순서를 따라 거쳐갈 확률 S의 분포를 모델링.
모든 순서에 균일 분포를 가정:
안정적인 모델을 위해 길이 |S| >=2 인 모든 채널을 버림.
36. 3.8.4 다접촉 애트리뷰션 multi-touch attribution
conversion baseline Pr(Y | ϕ) 는 모든 채널에 동일 -> 삭제
위 방법 외에 통과된 채널들에 기반을 두고 컨버전을 예측하는 회귀모델을 만든 후 회귀 계수의 크기를 비교하는 방법도
있다.
Pr(Y | Ck) can be estimated as the ratio of
converted users who passed through channel
Ck to the total number of users who passed
through the channel
37. 3.9 효율성 측정
행동과 결과가 정확하게 분리돼 있는 방법으로 실험하거나 데이터를 분석할 경우에 인과 관계(마케팅 행동 –> 효율성)가 외부 요인에 좌우되지 않
는다. 생물학이나 의학 같은 분야에서 개발된 실험 프레임워크는 구조적으로 마케팅 캠페인과 비슷한 시나리오에서 응용된다.
3.9.1 랜덤화된 실험
컨버전 비율 – 어떻게 측정?
• n이 작을 경우: R은 분산이 크다.
• n이 클 경우: 보다 안정적 결과 (낮은 분산)
[추정의 신뢰성 측정]
-> 베이지안 기법과 몬테카를로 시뮬레이션으로 추정 값의 신뢰성 측정 가능
목표: 관찰된 컨버전 수 k 가 주어졌을 때 컨버전 비율의 분포 p(R|k)를 알아내는 것.
k: 컨버전 수
n: treatment 받은 수
apply bayes rule on 3.68:
normalizer
P(k | R) : 컨버전 비율이 R일때 k 개의 컨버전을 관찰할 확률
p(R) : 컨버전 비율의 사전 분포; 사전확신
확률 분포!
we start with a prior belief about the rate distribution p(R), and the observed data, that is, the number of
conversions k, provide evidence for or against our belief. The posterior distribution p(R | k) is obtained by
updating our belief based on the evidence that we see
38. 3.9.1 랜덤화된 실험
컨버전 비율 – 어떻게 측정?
1) P(k | R) 항
R이 고정이라 가정, n명중 k명이 컨버전 할 확률은 이항분포로 주어짐.
2) P(R) 항 (사전분포)
likelihood function P(k | R) 가 이항분포 -> 사전켤레분포conjugate prior가 베타 분포
모수 x, y는 과거 데이터에 의해 추정.
이 경우 사후분포 P( R | k )는
P(k | R) : 컨버전 비율이 R일때 k 개의 컨버전을 관찰할 확률
p(R) : 컨버전 비율의 사전 분포; 사전확신
https://stats.stackexchange.com/questions/47771/what-is-the-intuition-behind-beta-distribution/47782#47782
p(R) 이 균일분포라 가정하면 , beta(1, 1)
39. 3.9.1 랜덤화된 실험
컨버전 비율 – 어떻게 측정?
estimate the probability that the conversion rate R lies within some credible interval [a, b]
MC simulation을 사용한 추정 방법
1. 입력 n, k 신뢰수준 0 < q < 100%
2. sample ~ Beta(k+1, n-k+1)
3. desired credible interval을 얻기 위해 생성된 sample의 q/2번째와 (100-q/2)번째 백분위수 값을 추정. e.g. R 추정값이 2.5%와 97.5% 백분위
수 사이에 있다고 95% 신뢰 할 수 있다.
https://stats.stackexchange.com/questions/47771/what-is-the-intuition-behind-beta-distribution/47782#47782
40. 3.9.1 랜덤화된 실험
Uplift
캠페인의 효율성은 보통 test 와 control 그룹의 converstion 비율의 차이인 uplift로 측정된다.
앞서와 비슷하지만, 이번에는 RT와 RC의 결합확률분포를 구해야한다.
랜덤 실험이 test / control이 독립적이 되도록 적절히 디자인 됐다면, 위 확률은 컨버전 비율의 각각의 분포로 나눌 수 있다.
MC simulation을 사용한 추정 방법
1. 입력 kT, nT, kC, nC 신뢰수준 0 < q < 100%
2. 각 샘플로부터 많은 값 L 생성
a. RT ~ Beta(kT +1, nT - kT +1)
b. RC ~ Beta(kC+1, nC- kC +1)
c. L = RT / RC – 1
3. L에 대한 credible interval을 얻기 위해 생성된 sample의 q/2번째와 (100-q/2)번째 백분위수 값을 추정.
매출에 대한 uplfit의 경우는
특정 기간동안 test 와 control 전체 매출을 구한 후 이 두 값으로 부터 얻는다.
L = G / G0 - 1
https://stats.stackexchange.com/questions/47771/what-is-the-intuition-behind-beta-distribution/47782#47782
41. 3.9.2 관찰 연구
온라인 환경에서 랜덤화된 실험을 적용 할 수 있다.
-> 타겟팅과 입찰단계 이후에 사용자를 샘플링하는 방법
https://stats.stackexchange.com/questions/47771/what-is-the-intuition-behind-beta-distribution/47782#47782
문제:
Dummy impression에
입찰 비용 발생
Q. 컨트롤 그룹 선정을
입찰단계 이전으로 옮
길 수 있는가?
s.t.
비용 X
문제:
입찰 과정은 랜덤이 아님.
= arbitrary bias
-> 비적합성과 관련된 임상 시험에 대한 연구를 응용!
42. 3.9.2 관찰 연구
control group에 있지만, 만약 입찰을 했다면 입찰 승자가
되어 impression이 되었을 법한 경우의 예상 컨버전 비율
uplif는 관찰된 RWT와 추론된 RWC의 비율로 추정될 수 있다.
• 문제는 uplift 분포는 통제그룹 선택, 입찰, 컨버전 같은 여러 랜덤 프로세스의 결합이기 때문에 특정하기 어렵다.
• 관찰 결과의 결합 확률분포를 결정하는 사용자의 내재적 성질과 다른 잠재요소들은 관찰할 수 없다.
44. 3.9.2 관찰 연구
시뮬레이션
[깁스 샘플링]
다변량 분포에서 샘플을 뽑아내는데 사용하는 방법.
각 변수는 나머지 변수가 고정된 상태에서 조건분포로부터 샘플됨
p(mu, s | data)에서 어떻게 샘플링 할 것인가?
-> 깁스 샘플링 활용
에서 각각 샘플링함.
1) p( s | mu, data)
2) p( mu | s, data)