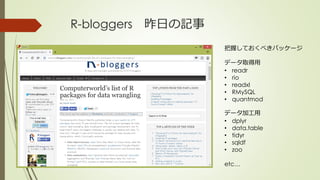
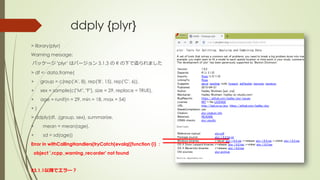
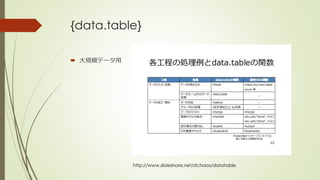
The document discusses several R packages for data wrangling (preprocessing) tasks. It provides a table with information on popular packages like plyr, reshape2, stringr, lubridate, sqldf, dplyr, data.table, and zoo. While dplyr is commonly used, the document focuses on introducing the plyr package, which can still be useful when working with list-type data. Examples show how to use plyr functions like llply and ddply to apply operations to multiple objects or subsets of data.












![apply family {base}
一つの関数を複数のオブジェクトに適用して得られた結果を一括で返す
(例1) iris {base}の各項目の平均
> apply(iris[,-5], 2, mean, na.rm=T)
Sepal.Length Sepal.Width Petal.Length Petal.Width
5.843333 3.057333 3.758000 1.199333
(例2)データフレーム内のファクタを文字列に一括変換
> df <- data.frame(X=LETTERS, x=letters)
> df[] <- lapply(df, as.character)](https://image.slidesharecdn.com/packagesfordatawrangling-150525142720-lva1-app6891/85/Packages-for-data-wrangling-14-320.jpg)
![apply family {base}
(例2)データフレーム内のファクタを文字列に一括変換
> df <- data.frame(X=LETTERS, x=letters)
> str(df)
'data.frame': 26 obs. of 2 variables:
$ X: Factor w/ 26 levels "A","B","C","D",..: 1 2 3 4 5 6 7 8 9 10 ...
$ x: Factor w/ 26 levels "a","b","c","d",..: 1 2 3 4 5 6 7 8 9 10 ...
> df[] <- lapply(df, as.character)
> str(df)
'data.frame': 26 obs. of 2 variables:
$ X: chr "A" "B" "C" "D" ...
$ x: chr "a" "b" "c" "d" ...](https://image.slidesharecdn.com/packagesfordatawrangling-150525142720-lva1-app6891/85/Packages-for-data-wrangling-15-320.jpg)

![ddply {plyr}
install.packages("plyr", type = "source")
library(plyr)
> ddply(df, .(group, sex), summarize,
+ mean = mean(age),
+ sd = sd(age))
group sex mean sd
1 A F 42.43033 8.996826
2 A M 30.09450 13.311536
3 B F 35.64277 11.060713
4 B M 38.96056 6.731923
5 C F 25.01813 4.588658
6 C M 49.29878 NA
> head(df)
group sex age
1 A M 20.23535
2 A F 34.10908
3 A M 45.23656
4 A F 52.72067
5 A M 24.81160
6 A F 37.51441
{dplyr}を使った場合
> df %>% group_by(sex) %>% summarise(mean=mean(age), sd=sd(age))
Source: local data frame [2 x 3]
sex mean sd
1 F 34.51422 10.940603
2 M 37.60556 9.497813](https://image.slidesharecdn.com/packagesfordatawrangling-150525142720-lva1-app6891/85/Packages-for-data-wrangling-18-320.jpg)


![{data.table}
data.tableへの変換
> iris.tbl <- data.table(iris)
> iris.tbl
Sepal.Length Sepal.Width Petal.Length Petal.Width
Species
1: 5.1 3.5 1.4 0.2 setosa
2: 4.9 3.0 1.4 0.2 setosa
3: 4.7 3.2 1.3 0.2 setosa
4: 4.6 3.1 1.5 0.2 setosa
5: 5.0 3.6 1.4 0.2 setosa
---
146: 6.7 3.0 5.2 2.3 virginica
147: 6.3 2.5 5.0 1.9 virginica
148: 6.5 3.0 5.2 2.0 virginica
149: 6.2 3.4 5.4 2.3 virginica
150: 5.9 3.0 5.1 1.8 virginica
> class(iris.tbl)
[1] "data.table" "data.frame"
#キーの設定⇨高速要素抽出
>setkey(iris.tbl, Species)
> tables()
NAME NROW NCOL MB COLS
KEY
[1,] iris.tbl 150 5 1
Sepal.Length,Sepal.Width,Petal.Length,Petal.Width,Spe
cies Species
Total: 1MB](https://image.slidesharecdn.com/packagesfordatawrangling-150525142720-lva1-app6891/85/Packages-for-data-wrangling-22-320.jpg)
![{stringr}
文字列操作
文字列の結合: str_c
> str_c("ABC", "123")
[1] “ABC123” ⇦スペース無し結合
> paste("ABC", "123")
[1] "ABC 123“
> paste("ABC", "123“, sep=‘’)
[1] "ABC123“](https://image.slidesharecdn.com/packagesfordatawrangling-150525142720-lva1-app6891/85/Packages-for-data-wrangling-23-320.jpg)
![{stringr}
文字列操作
文字列の結合: str_c
> str_c("ABC", "123")
[1] “ABC123” ⇦スペース無し結合
> paste("ABC", "123")
[1] "ABC 123“
> paste("ABC", "123“, sep=‘’)
[1] "ABC123“
文字列の長さ: str_length
> str_length("KOBER")
[1] 5
文字列の抽出: str_sub
> str_sub('this is a hampen', start = 3, end = 5)
[1] "is “
> str_sub('これははんぺんです', start = 3, end = 5)
[1] "ははん"
文字列の反復: str_dup
> str_dup('this is a hampen', times = 2)
[1] "this is a hampenthis is a hampen"
文字列の置換: str_replace
> str_replace("これははんぺんです", "はんぺん", "ちくわ")
[1] "これはちくわです"](https://image.slidesharecdn.com/packagesfordatawrangling-150525142720-lva1-app6891/85/Packages-for-data-wrangling-24-320.jpg)
![{stringr}
文字列操作
文字列の結合: str_c
> str_c("ABC", "123")
[1] “ABC123” ⇦スペース無し結合
> paste("ABC", "123")
[1] "ABC 123“
> paste("ABC", "123“, sep=‘’)
[1] "ABC123“
文字列の長さ: str_length
> str_length("KOBER")
[1] 5
文字列の抽出: str_sub
> str_sub('this is a hampen', start = 3, end = 5)
[1] "is “
> str_sub('これははんぺんです', start = 3, end = 5)
[1] "ははん"
文字列の反復: str_dup
> str_dup('this is a hampen', times = 2)
[1] "this is a hampenthis is a hampen"
文字列の置換: str_replace
> str_replace("これははんぺんです", "はんぺん", "ちくわ")
[1] "これはちくわです"
半角⇔全角
> library(Nippon)
> zen2han("12345ABC")
[1] "12345ABC"
> x <- "12345ABC"
> x
[1] "12345ABC"
> zen2han(x)
[1] "12345ABC"](https://image.slidesharecdn.com/packagesfordatawrangling-150525142720-lva1-app6891/85/Packages-for-data-wrangling-25-320.jpg)

![{lubridate}
時間を扱う
{base}
as.Date("19810322", format = "%Y%m%d")
{lubridate}
ymd("19810322")
> library(lubridate, type = ‘source’)
> ymd("19810322")
Error in gsub("+", "*", fixed = T, gsub(">", "_e>", num)) :
invalid multibyte string at
'<8c>)<28>?![[:alpha:]]))|((?<H_s_e>2[0-
4]|[01]?¥d)¥D+(?<M_s_e>[0-
5]?¥d)¥D+((?<OS_s_S_e>[0-5]?¥d¥.¥d+)|(?<S_s_e>[0-
6]?¥d))))'](https://image.slidesharecdn.com/packagesfordatawrangling-150525142720-lva1-app6891/85/Packages-for-data-wrangling-27-320.jpg)
![{lubridate}
時間を扱う
{base}
as.Date("19810322", format = "%Y%m%d")
{lubridate}
ymd("19810322")
> library(lubridate, type = ‘source’)
> ymd("19810322")
Error in gsub("+", "*", fixed = T, gsub(">", "_e>", num)) :
invalid multibyte string at
'<8c>)<28>?![[:alpha:]]))|((?<H_s_e>2[0-
4]|[01]?¥d)¥D+(?<M_s_e>[0-
5]?¥d)¥D+((?<OS_s_S_e>[0-5]?¥d¥.¥d+)|(?<S_s_e>[0-
6]?¥d))))'
時間の操作をする際のデータの型変更
・ as.Date: 日付だけで十分な場合
・ as.POSIXct:日時を扱いたい場合
・ as.POSIXlt: 時間、分、秒等各要素を取り出したい場合
・ as.integer: (規則・不規則)時系列データに関する
処理を行う必要がある場合
・ as.ts: 時系列関数を利用する場合
・ as.zoo, as.xts:時系列処理用パッケージを利用する場合
個人的な使い分け
なのですが…
もっといい方法お
しえてください](https://image.slidesharecdn.com/packagesfordatawrangling-150525142720-lva1-app6891/85/Packages-for-data-wrangling-28-320.jpg)





































































