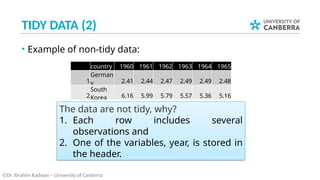
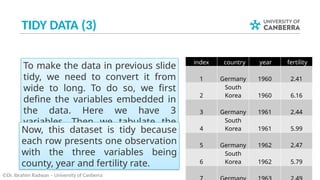
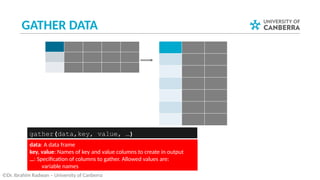
This document outlines Lecture 7 of an Introduction to Data Science course, focusing on data wrangling, tidy data, and practical examples of using R packages like `tidyr` and `dplyr`. It covers key concepts such as importing data, manipulating data frames, and transforming data into a tidy format for analysis. The lecture also includes a case study on unemployment rates and encourages further reading from the book 'R for Data Science'.







![PIPE OPERATOR %>%
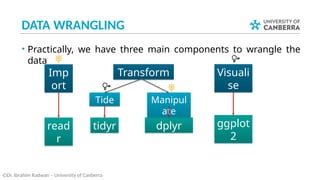
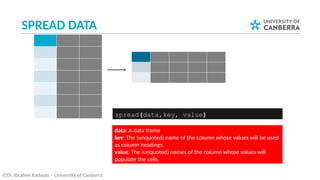
• In data wrangling, most likely, you need to perform series of
operations (i.e. verbs) on the same data.
• This will need you to create intermediate tables temporarily to
save the results to be processed with the next operations.
• R provides an elegant way to perform series of operations on
the same data in one go via using the pipe operator %>%
original data select filter
→ →
©Dr. Ibrahim Radwan – University of Canberra
16 %>% sqrt() %>% log2()
[1] 2
F(x) is the same as
x %>% F](https://image.slidesharecdn.com/lecturenoteswk7-240916123103-7455ebd3/85/description-description-description-description-8-320.jpg)



































![[1062BPY12001] Data analysis with R / week 2](https://cdn.slidesharecdn.com/ss_thumbnails/dataanalyzer01-180307063046-thumbnail.jpg?width=640&height=640&fit=bounds)
