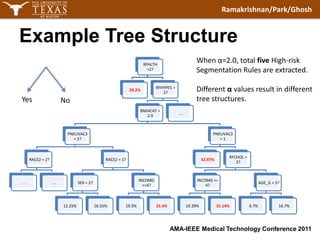
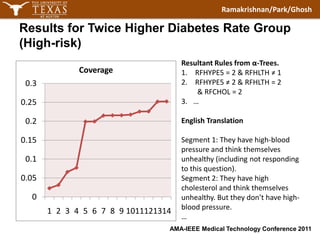
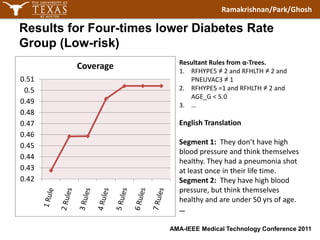
The document discusses using modified α-trees and disjunctive rule combinations to segment diabetes risk groups from a large healthcare dataset. It aims to extract simple, interpretable rules in natural language to identify high-risk groups with diabetes rates twice the normal population as well as low-risk groups with rates four times lower. The method is demonstrated on the BRFSS dataset, extracting rules to define different risk segments based on attributes like blood pressure, health ratings, vaccinations and more. The approach provides alternatives to traditional machine learning for imbalanced healthcare classification problems.