Downloaded 67 times





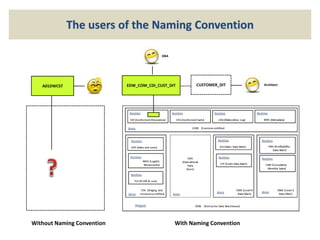











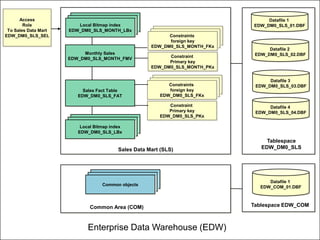

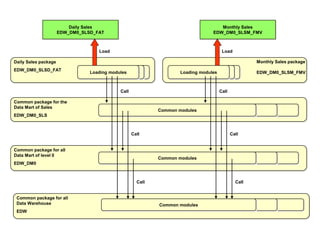



The document discusses naming convention techniques for data warehouses and business intelligence, emphasizing the importance of consistent naming for various entities such as tables, attributes, indexes, integrity constraints, and roles. It outlines a pragmatic approach for applying these conventions, highlighting their utility, especially for database administrators, while allowing for flexibility based on specific needs. Additionally, it provides detailed guidelines and examples for implementing naming conventions across different components of a data warehouse.

















































































