Downloaded 54 times






![ Prendiamo un codice di titolo finanziario. Spesso in una banca si utilizzano dei codici interni come
riferimento titolo, ma il flusso di alimentazione, che magari arriva da una società di fondi, utilizza un
codice internazionale (ISIN).
Anche in questo caso sarà necessario, per mezzo della vista, recuperare il codice interno da
qualche altra tabella di mapping, prima di caricare la tabella di Staging Area. Queste trasformazioni,
che ho definito come “arricchimento in un mio articolo [1] possono anche essere numerose,
complicando non poco la costruzione della vista finale.
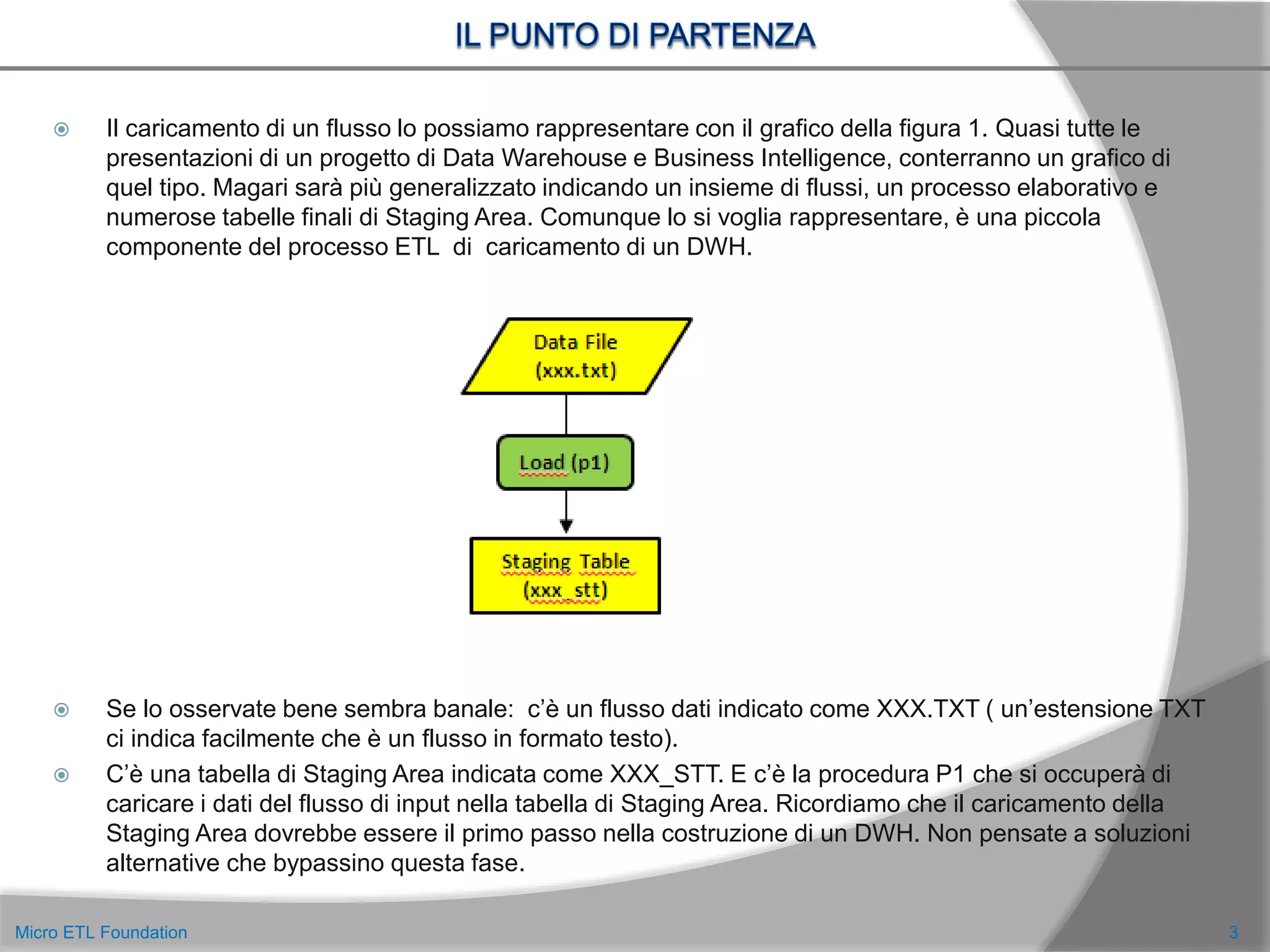
Come potete vedere, al terzo passo di approfondimento, la prima figura si è sicuramente complicata:
sono presenti più strutture e più elementi da considerare. La prima vista permetteva di definire delle
piccole trasformazioni “sintattiche”, la seconda vista permette di aggiungere altre informazioni
“logiche”.
Si entra di più nella logica semantica dell’informazione e si orienta la struttura delle tabelle di
Staging Area verso quelle che saranno le strutture dimensionali finali.
10Micro ETL Foundation](https://image.slidesharecdn.com/tecnichediprogettazionedellastagingareainunprocessoetl-150726074701-lva1-app6892/75/Tecniche-di-progettazione-della-staging-area-in-un-processo-etl-10-2048.jpg)


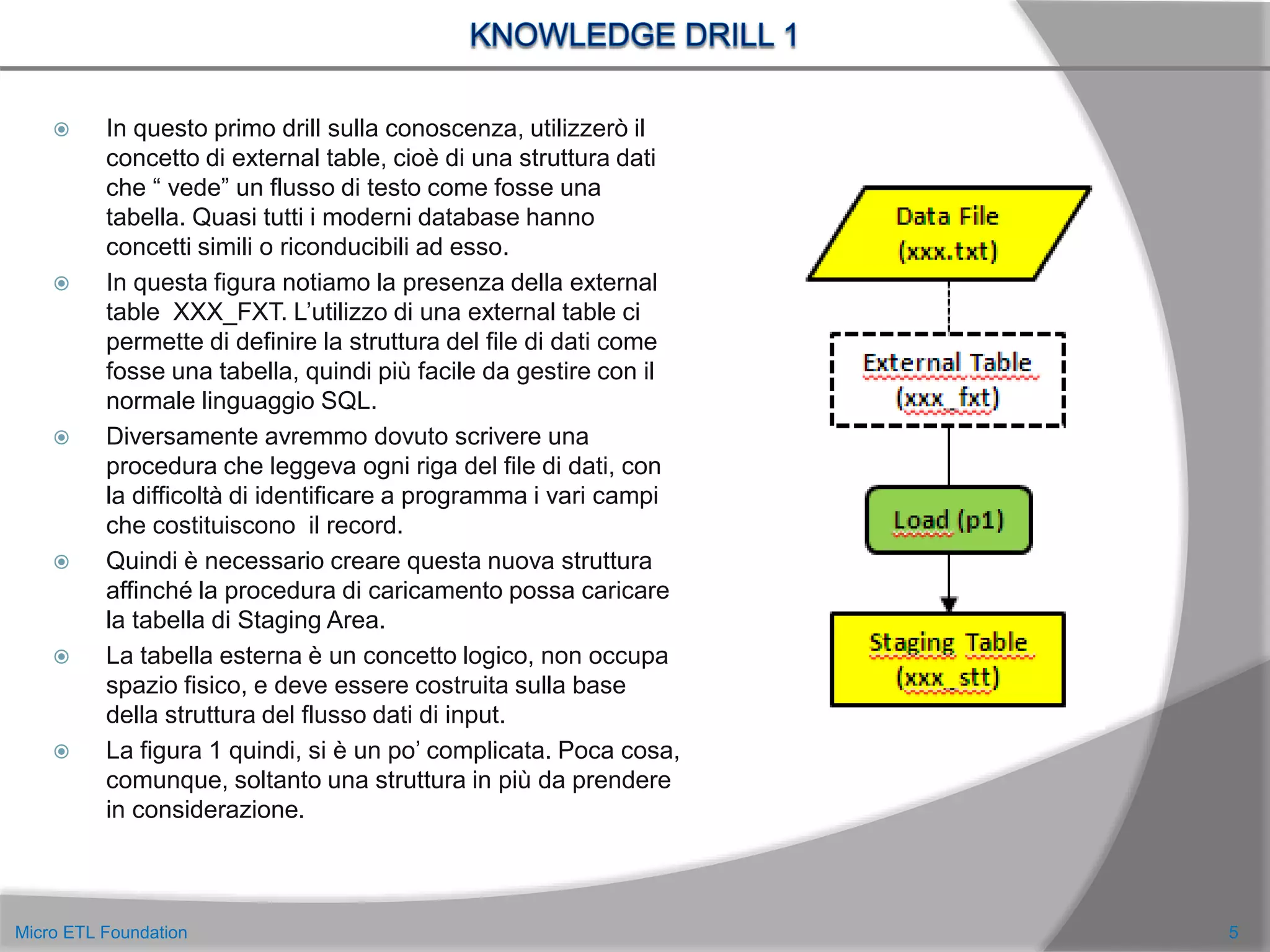
![ Una tabella di log di estremo dettaglio (MEF_MSG_LOT) che fornisce informazioni sulle singole
operazioni (statement di manipolazione dati, informazioni di controllo) che sono contenute
all’interno dei moduli.
Una tabella di configurazione degli indirizzi di posta (MEF_EMAIL_CFT) a cui inviare gli alert relativi
ai problemi di caricamento.
Sono quattro tabelle di metadati molto importanti per la gestione del processo e si possono trovare
degli esempi del loro utilizzo, in due mie presentazioni già pubblicate su Slideshare [7], [9].
Per comodità, nel disegno, queste tabelle sono state associate solo al modulo P1, ma ovviamente
tutti i moduli devono essere in grado di utilizzarle.
Abbiamo finalmente ottenuto il disegno conclusivo ? Ora abbiamo tutti gli elementi per stimare con
più attenzione il tempo necessario a costruire tutte le strutture e le componenti elaborative della
figura ? Anche in questo caso la risposta è nuovamente no.
14Micro ETL Foundation](https://image.slidesharecdn.com/tecnichediprogettazionedellastagingareainunprocessoetl-150726074701-lva1-app6892/75/Tecniche-di-progettazione-della-staging-area-in-un-processo-etl-14-2048.jpg)
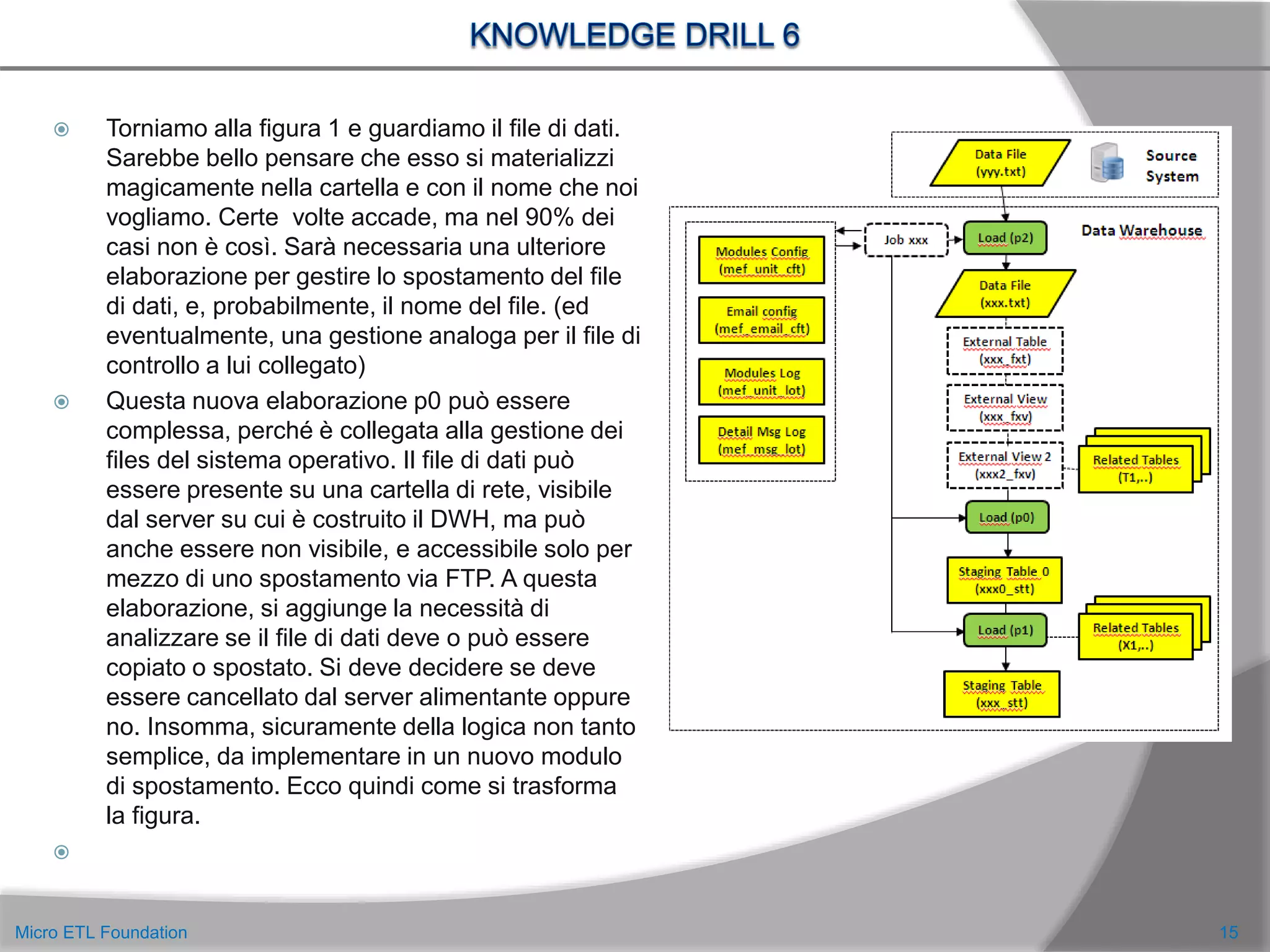
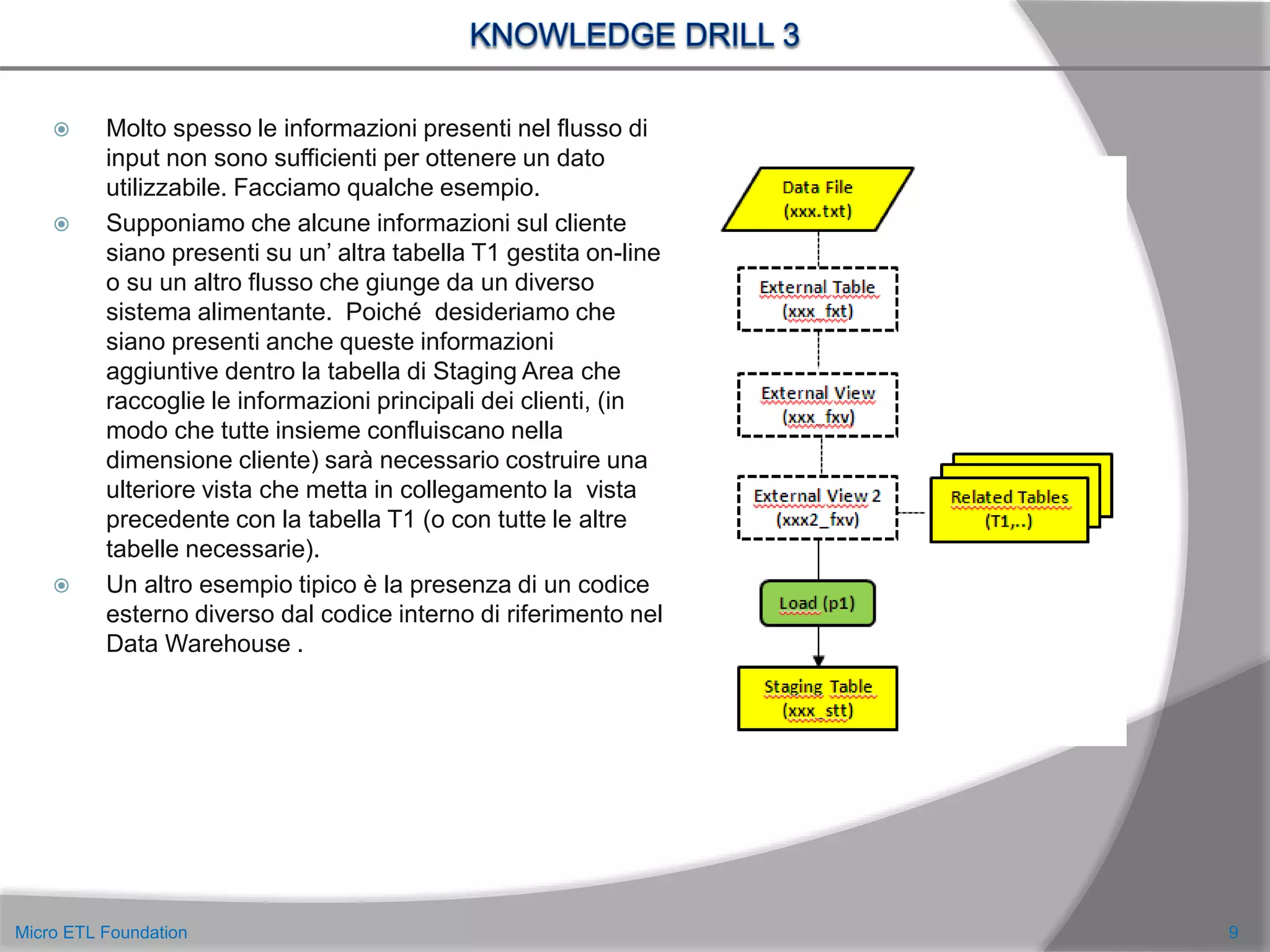
![ Possiamo considerare i metadati aggiunti nel Drill precedente, come metadati legati al processo.
Mancano ancora i metadati legati alle strutture, cioè alla composizione dei file di dati.
Ritengo molto importante avere la struttura dei file di dati in una tabella, perché ci permette di
costruire in modo dinamico gli statement di creazione delle strutture di supporto e di inserzione dei
dati. Non sarà necessario costruire uno statement specifico per ogni flusso alimentante: sarà
sufficiente chiamare una unica procedura che prende in input il codice flusso e genera lo statement di
insert.
In questo modo, se arriva la richiesta di documentare la struttura di tutti i file di dati, sarà sufficiente
fare un SQL che estrae queste informazioni dalle tabelle dei metadati.
E saremo sicuri che queste informazioni saranno sempre aggiornate, perché è su di esse che si
basa il processo di caricamento dinamico.
Provate a pensare di avere queste informazioni in un documento Word o Excel (come quasi sempre
succede). Questo documento diventerà obsoleto dopo i primi giorni di test, in cui ci accorgeremo di
dovere fare delle modifiche che agiranno, per problemi di tempo, direttamente sui programmi e quasi
mai sulla documentazione.
Inoltre il file di dati, a prescindere che sia con colonne a lunghezza fissa o con terminatore di colonna,
può avere una intestazione e/o un record di coda contenente il numero di righe presenti nel flusso
(che deve essere controllato in qualche modo). A volte il numero di righe viene fornito in un flusso
separato. Senza contare le situazioni in cui il giorno di riferimento dei dati è presente nel nome del
file di dati stesso o in una riga dell’intestazione e non come campo del flusso. Una trattazione
completa di questi casi la potete leggere in [4,5]. Anche tutte queste informazioni devono essere
gestite per mezzo di tabelle di metadati. Le possiamo vedere nella figura seguente.
16Micro ETL Foundation](https://image.slidesharecdn.com/tecnichediprogettazionedellastagingareainunprocessoetl-150726074701-lva1-app6892/75/Tecniche-di-progettazione-della-staging-area-in-un-processo-etl-16-2048.jpg)
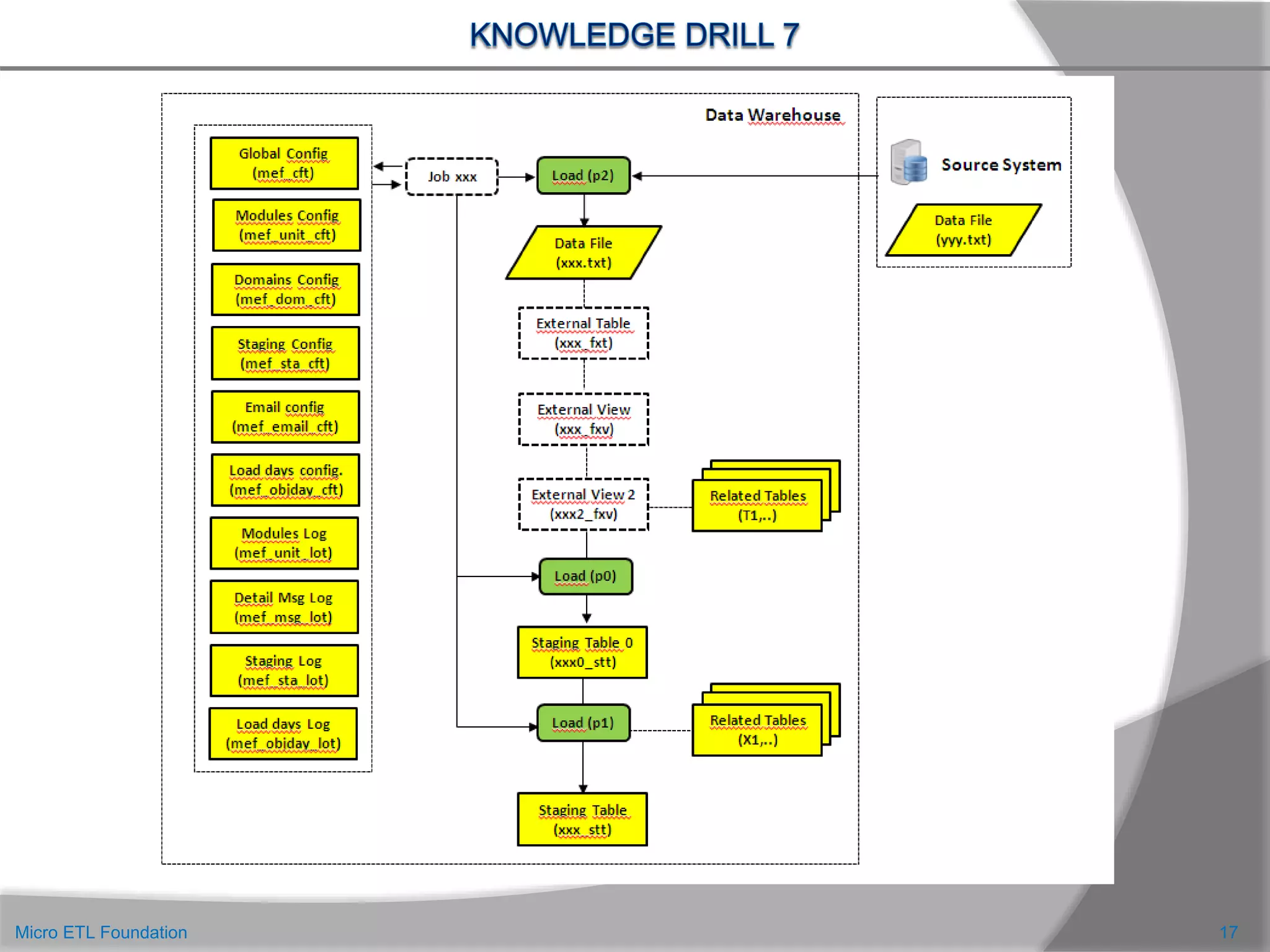
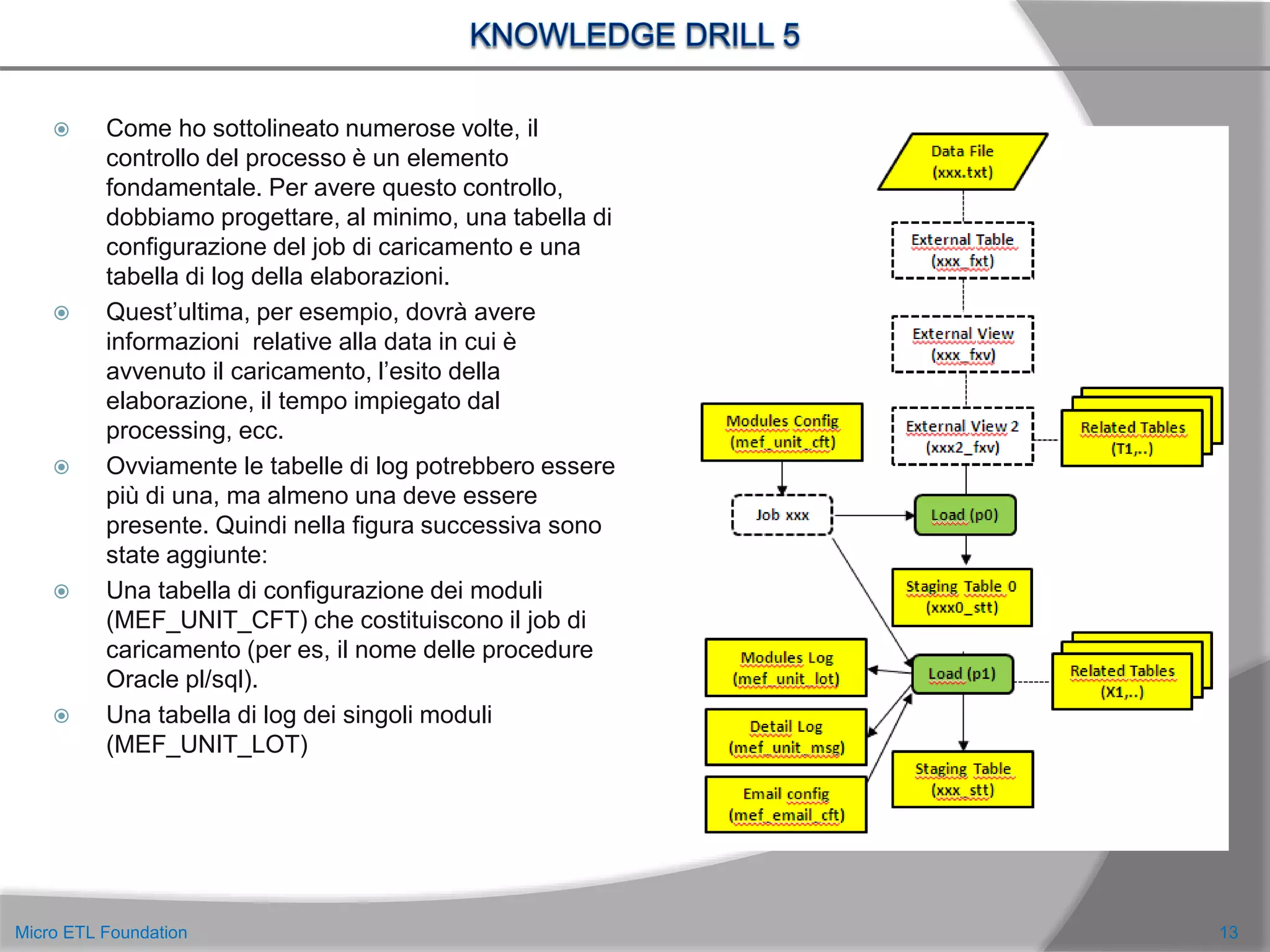
![ L’ultima figura ottenuta però non è ancora completa.In essa, per una gestione ottimale della Staging
Area, abbiamo considerato:
Una tabella di configurazione globale (MEF_CFT) in cui inserire tutte le informazioni utili a tutto il
processo di caricamento. Per esempio il formato unico di trattamento dei campi data, i valori di
default nei casi di dati “null”, la lingua di default delle descrizioni, ecc.
Una tabella di configurazione dei file dati (MEF_IO_CFT), con tutte le informazioni relative al tipo di
file e ai suoi contenuti.
Una tabella di configurazione della struttura dei file dati (MEF_STA_CFT), con i nomi dei campi, tipo,
lunghezza, formati, regole di trasformazione, ecc.
Una tabella di definizione dei domini di valori dei codici (MEF_DOM_CFT). Vedi [6]
Una tabella di configurazione dei giorni di ricevimento dei file di dati (MEF_OBJDAY_CFT). Vedi [7,8]
Una tabella di log (MEF_OBJDAY_LOT) di arrivo dei file di dati.
18Micro ETL Foundation](https://image.slidesharecdn.com/tecnichediprogettazionedellastagingareainunprocessoetl-150726074701-lva1-app6892/75/Tecniche-di-progettazione-della-staging-area-in-un-processo-etl-18-2048.jpg)
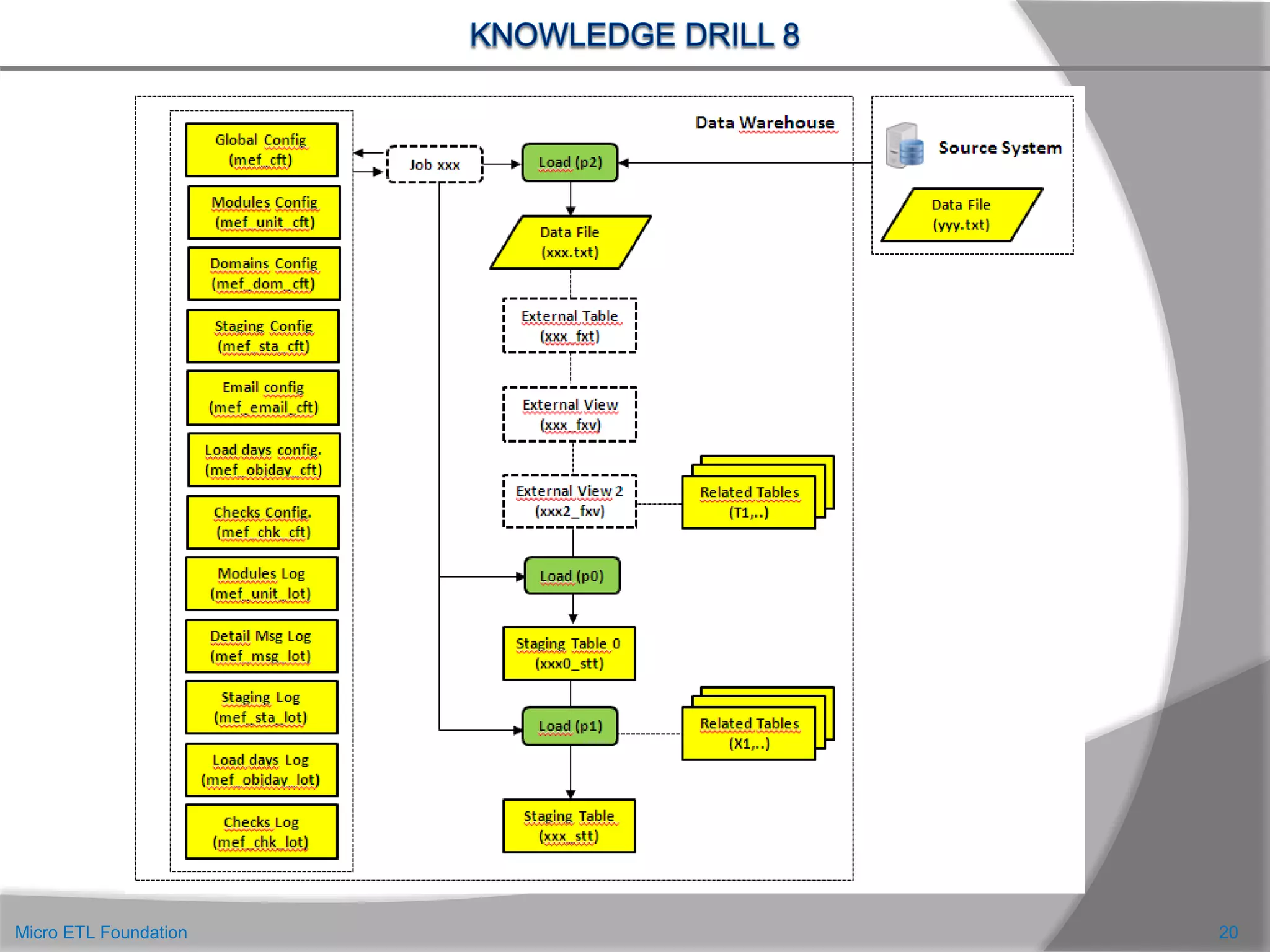
![ Non abbiamo ancora parlato di un altro elemento fondamentale: la qualità del dato.
Tutte le strutture create fino ad ora, ci hanno permesso di gestire gran parte delle problematiche
collegate a un processo ETL. Sicuramente, le tabelle di metadati ci hanno permesso di ottimizzare e
generalizzare i moduli di elaborazione e di tenere sotto controllo l’esito delle elaborazioni.
Inoltre molte di queste strutture, possono essere utilizzabili non solo per il caricamento della Staging
Area, ma anche per le fasi successive del caricamento. Purtroppo però la figura semplice che
abbiamo visto all’inizio, si è molto complicata. Nuove strutture e nuovi moduli di caricamento si sono
aggiunti per gestire tutta quella varietà si situazioni che si verificano nella realtà.
Come possiamo garantire che il risultato finale è corretto ? Possiamo essere sicuri che, a fronte di un
data file, per esempio di 23915 righe, la tabella finale di Staging Area conterrà esattamente 23915
righe ? Chi ha un minimo di esperienza, sa che tutti questi passaggi intermedi di arricchimento e di
join con altre tabelle potrebbero portare alla perdita o alla duplicazione delle righe iniziali. Ecco
perché è necessario aggiungere ancora alcune tabelle di controllo che ci diano questa sicurezza.
Potrebbero essere utili, per esempio:
Una tabella di configurazione dei controlli di qualità (MEF_CHK_CFT )
Una tabella di log di esito dei controlli (MEF_CHK_LOT) che mostri la quadratura su tutte le strutture
coinvolte nel processo elaborativo.
Un esempio della applicazione di questi controlli lo potete trovare nella slideshare [9]
19Micro ETL Foundation](https://image.slidesharecdn.com/tecnichediprogettazionedellastagingareainunprocessoetl-150726074701-lva1-app6892/75/Tecniche-di-progettazione-della-staging-area-in-un-processo-etl-19-2048.jpg)


![23Micro ETL Foundation
[1] Data Warehouse - What you know about etl process is wrong
[2] Recipes 9 of Data Warehouse and Business Intelligence - Techniques to control the processing units in
the ETL process
[3] Recipes of Data Warehouse and Business Intelligence.A messaging system for Oracle Data Warehouse
(part 1)
[3] Data Warehouse and Business Intelligence - Recipe 7 - A messaging system for Oracle Data
Warehouse (part 2)
[4] Data Warehouse and Business Intelligence - Recipe 1 - Load a Data Source File (with header, footer
and fixed lenght columns) into a Staging Area table with a click
[5] Data Warehouse and Business Intelligence - Recipe 2 - Load a Data Source File (.csv with header, rows
counter in a separate file) into a Staging Area table with a click
[6] Recipes 10 of Data Warehouse and Business Intelligence - The descriptions management
[7] Data Warehouse and Business Intelligence - Recipe 4 - Staging area - how to verify the reference day
[8] Recipe 12 of Data Warehouse and Business Intelligence - How to identify and control the reference day
of a data file
[9] Data Warehouse and Business Intelligence - Recipe 3 - How to check the staging area loading](https://image.slidesharecdn.com/tecnichediprogettazionedellastagingareainunprocessoetl-150726074701-lva1-app6892/75/Tecniche-di-progettazione-della-staging-area-in-un-processo-etl-23-2048.jpg)

L'articolo di Massimo Cenci esplora le complessità del caricamento dei dati nella staging area di un processo ETL, sottolineando l'importanza di questa fase nel successo di un data warehouse. Viene discusso come errori nella progettazione della staging area possano compromettere l'intero workflow e la necessità di affrontare trasformazioni e arricchimenti dei dati, che spesso richiedono elaborazioni complesse. Inoltre, si evidenzia l'importanza di strutture di controllo e log per gestire adeguatamente il processo di caricamento.






























































