Download as PDF, PPTX









![DNNの動向(6/12)
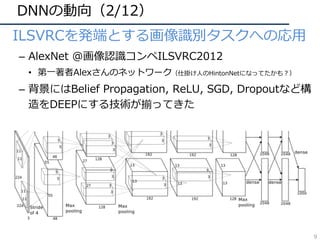
• 構造の深化
– 2014年頃から「構造をより深くする」ための知⾒が整う
– 現在(主に画像識別で)主流なのはResidual Network
AlexNet [Krizhevsky+, ILSVRC2012]
VGGNet [Simonyan+, ILSVRC2014]
GoogLeNet [Szegedy+, ILSVRC2014/CVPR2015]
ResNet [He+, ILSVRC2015/CVPR2016]
ILSVRC2012 winner,DLの⽕付け役
16/19層ネット,deeperモデルの知識
ILSVRC2014 winner,22層モデル
ILSVRC2015 winner, 152層!(実験では103+層も)
13](https://image.slidesharecdn.com/cvpr18reportfinalize-180624063638/85/CVPR-2018-13-320.jpg)
![DNNの動向(7/12)
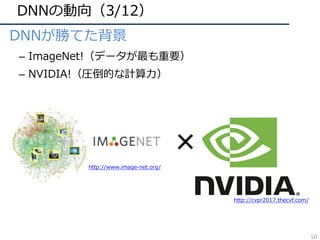
• 他タスクへの応⽤(画像認識・動画認識)
– R-CNN: 物体検出
– FCN: セマンティックセグメンテーション
– CNN+LSTM: 画像説明⽂
– Two-Stream CNN: 動画認識
Person
Uma
Show and Tell [Vinyals+, CVPR15]
R-CNN [Girshick+, CVPR14]
FCN [Long+, CVPR15]
Two-Stream CNN [Simonyan+, NIPS14]
14](https://image.slidesharecdn.com/cvpr18reportfinalize-180624063638/85/CVPR-2018-14-320.jpg)
















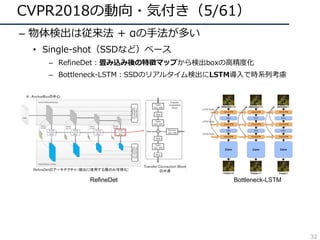

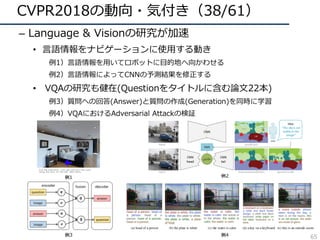
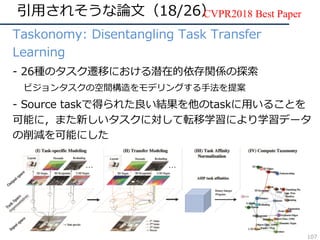
![CVPR2018の動向・気付き(8/61)
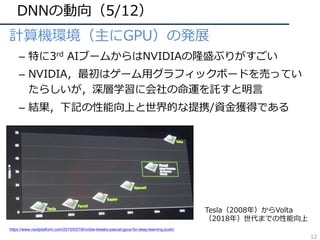
– 3D(xyt, xyz) の畳み込みfilterの再考
• 動画解析における、(3D conv) VS (2D conv + α)
– 3D ResNet : ⼤規模DBによる学習で3D convの有効性を解析
– R(2+1)D:同⼀param数では(2+1)D convの精度が良いことを主張
– MiCT : 3D, 2D convの組み合わせが良いと主張
• RGB-D 画像解析における3D convの冗⻑性を問題視
– SurfConv:画像内の深度情報を考慮した2D convを⽤いて解決
35
SurfConv: Bridging 3D and 2D Convolution for RGBD Images
Hang Chu1,2
Wei-Chiu Ma3
Kaustav Kundu1,2
Raquel Urtasun1,2,3
Sanja Fidler1,2
1
University of Toronto 2
Vector Institute 3
Uber ATG
{chuhang1122, kkundu, fidler}@cs.toronto.edu {weichiu, urtasun}@uber.com
Abstract
We tackle the problem of using 3D information in convo-
lutional neural networks for down-stream recognition tasks.
Using depth as an additional channel alongside the RGB
input has the scale variance problem present in image con-
volution based approaches. On the other hand, 3D convo-
lution wastes a large amount of memory on mostly unoc-
cupied 3D space, which consists of only the surface vis-
ible to the sensor. Instead, we propose SurfConv, which
“slides” compact 2D filters along the visible 3D surface.
SurfConv is formulated as a simple depth-aware multi-scale
2D convolution, through a new Data-Driven Depth Dis-
cretization (D4
) scheme. We demonstrate the effectiveness
of our method on indoor and outdoor 3D semantic segmen-
tation datasets. Our method achieves state-of-the-art per-
formance with less than 30% parameters used by the 3D
convolution-based approaches.
1. Introduction
While 3D sensors have been popular in the robotics
community, they have gained prominence in the computer
vision community in the recent years. This has been
the effect of extensive interest in applications such as au-
tonomous driving [11], augmented reality [32] and urban
planning [47]. These 3D sensors come in various forms
such as active LIDAR sensors, structured light sensors,
stereo cameras, time-of-flight cameras, etc. These range
sensors produce a 2D depth image, where the value at every
Image Convolution
3D Convolution
Surface Convolution
2D conv
2D conv
2D conv
2D conv
2D conv
fc
(a) R2D
3D conv
3D conv
3D conv
3D conv
3D conv
fc
(d) R3D
(2+1)D conv
fc
(2+1)D conv
(2+1)D conv
(2+1)D conv
(2+1)D conv
(e) R(2+1)D
2D conv
2D conv
2D conv
3D conv
3D conv
fc
(b) MC
3D conv
3D conv
3D conv
2D conv
2D conv
fc
(c) rMCx x
space-time pool space-time pool space-time pool space-time pool space-time pool
clip clip clip clip clip
igure 1. Residual network architectures for video classification considered in this work. (a) R2D are 2D ResNets; (b) MCx are
ResNets with mixed convolutions (MC3 is presented in this figure); (c) rMCx use reversed mixed convolutions (rMC3 is shown here); (d)
R3D are 3D ResNets; and (e) R(2+1)D are ResNets with (2+1)D convolutions. For interpretability, residual connections are omitted.
3. Convolutional residual blocks for video dimensions of the preceding tensor zi 1. Each filter yields](https://image.slidesharecdn.com/cvpr18reportfinalize-180624063638/85/CVPR-2018-35-320.jpg)











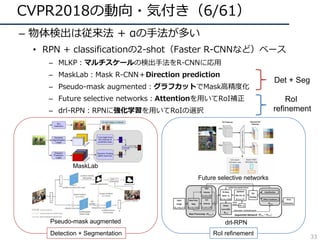
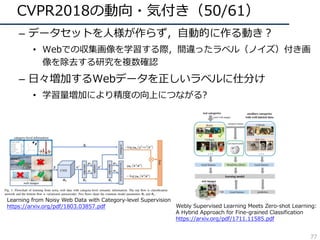
![CVPR2018の動向・気付き(22/61)
– 学習を効率化するような⼿法が⽬⽴つように
• ラベルなしデータの活⽤
– 被っていたので略
• 他ドメイン(データセット)の活⽤
– Domain Adaptation関係の⼿法
– 弱教師あり学習の活⽤
– PackNetのような複数のデータセットの情報を残していく学習⽅法
(a) Initial filter for Task I (b) Final filter for Task I (c) Initia
60% pruning + re-training training
Figure 1: Illustration of the evolution of a 5⇥5 filter with steps o
illustrated in (a). After pruning by 60% (15/25) and re-training,
denote 0 valued weights. Weights retained for Task I are kept fixe
We allow the pruned weights to be updated for Task II, leading
pruning by 33% (5/15) and re-training leads to filter (d), which i
Domain Adaptive Faster R-CNN for Object Detection in the Wild
Yuhua Chen1
Wen Li1
Christos Sakaridis1
Dengxin Dai1
Luc Van Gool1,2
1
Computer Vision Lab, ETH Zurich 2
VISICS, ESAT/PSI, KU Leuven
{yuhua.chen,liwen,csakarid,dai,vangool}@vision.ee.ethz.ch
Abstract
etection typically assumes that training and test
wn from an identical distribution, which, how-
ot always hold in practice. Such a distribution
ill lead to a significant performance drop. In
e aim to improve the cross-domain robustness of
tion. We tackle the domain shift on two levels:
e-level shift, such as image style, illumination,
the instance-level shift, such as object appear-
tc. We build our approach based on the recent
art Faster R-CNN model, and design two do-
ation components, on image level and instance
uce the domain discrepancy. The two domain
components are based on H-divergence theory,
lemented by learning a domain classifier in ad-
aining manner. The domain classifiers on dif-
Figure 1. Illustration of different datasets for autonomous driv-
ing: From top to bottom-right, example images are taken from:
KITTI[17], Cityscapes[5], Foggy Cityscapes[49], SIM10K[30].
Though all datasets cover urban scenes, images in those dataset
vary in style, resolution, illumination, object size, etc. The visual
difference between those datasets presents a challenge for apply-
ing an object detection model learned from one domain to another
domain.
Star GAN Domain Adaptive Faster R-CNN PackNet
49](https://image.slidesharecdn.com/cvpr18reportfinalize-180624063638/85/CVPR-2018-49-320.jpg)





![CVPR2018の動向・気付き(30/61)
– Self-/Un-supervisedな表現学習
• Target taskをより具体化したものが今後注⽬?
– キーポイントマッチングのための表現学習 (3)
– シーン認識、⾏動認識のための表現学習 (4)
ImageNet学習済みモデルを超える挑戦にも引き続き注⽬!
etrically Stable Features Through
Introspection
,⇤
Diane Larlus2
Andrea Vedaldi1
k
2
Computer Vision Group
NAVER LABS Europe
diane.larlus@naverlabs.com
Warped image
Input image
Robust learning
to match
Syntheticwarp
Predicted pixel-wise
representation
Geometrically
stable features
Predicted feature reliability
Figure 1. Our approach leverages correspondences obtained from
synthetic warps in order to self-supervise the learning of a dense
Training on Flying chairs
parameter transferring
Training on 3D movies
...
...
new task ground truth
old model response
Convolutional layers Refinement layers Ground truth
Figure 2. The framework of our proposed geometry guided CNN. We firstly use the synthetic images to train a CNN, and then use the 3D
movies to further update the network.
extracted, represented as a flow map. This dataset contains
22,872 image pairs in total. We show some example images
in Figure 1.
It has been reported that the models trained with synthesis
data perform relatively poor on the real image and video
data [29]. In order to close the domain gap, we propose
(3) https://arxiv.org/abs/1804.01552
(4) http://cseweb.ucsd.edu/~haosu/papers/c
vpr18_geometry_predictive_learning.pdf
57](https://image.slidesharecdn.com/cvpr18reportfinalize-180624063638/85/CVPR-2018-57-320.jpg)




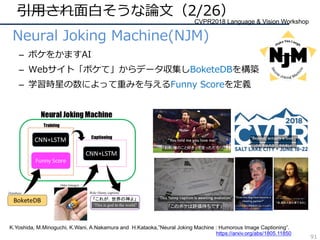
![CVPR2018の動向・気付き(37/61)
– 他分野の技術が積極的に取り⼊れられる
• Attention:あまり無かった1枚の画像のAttentionも出てきた
– Non-local Neural Network:NLPっぽいAttention機構の使い⽅
– Squeeze-and-Estuation Network:CNNに特化したAttention機構
• Embedding:画像+αの組み合わせ
– ⾔語から画像中の物体の位置を推定
– ⾳から画像中の物体の位置を推定
nly on the current and the latest time steps
1).
l operation is also different from a fully-
yer. Eq.(1) computes responses based on
ween different locations, whereas fc uses
In other words, the relationship between xj
nction of the input data in fc, unlike in non-
hermore, our formulation in Eq.(1) supports
le sizes, and maintains the corresponding
t. On the contrary, an fc layer requires a
output and loses positional correspondence
i to yi at the position i).
peration is a flexible building block and can
gether with convolutional/recurrent layers.
nto the earlier part of deep neural networks,
hat are often used in the end. This allows us
hierarchy that combines both non-local and
n.
ons
ribe several versions of f and g. Interest-
θ: 1×1×1 φ: 1×1×1 g: 1×1×1
1×1×1
softmax
z
T×H×W×1024
T×H×W×512 T×H×W×512 T×H×W×512
THW×512 512×THW
THW×THW
THW×512
THW×512
T×H×W×512
T×H×W×1024
x
Figure 2. A spacetime non-local block. The feature maps are
shown as the shape of their tensors, e.g., T⇥H⇥W⇥1024 for
1024 channels (proper reshaping is performed when noted). “⌦”
denotes matrix multiplication, and “ ” denotes element-wise sum.
The softmax operation is performed on each row. The blue boxes de-
note 1⇥1⇥1 convolutions. Here we show the embedded Gaussian
version, with a bottleneck of 512 channels. The vanilla Gaussian
version can be done by removing ✓ and , and the dot-product
version can be done by replacing softmax with scaling by 1/N.
Finding beans in burgers:
Deep semantic-visual embedding with localization
Martin Engilberge1,2
, Louis Chevallier2
, Patrick P´erez2
, Matthieu Cord1
1
Sorbonne universit´e, Paris, France 2
Technicolor, Cesson S´evign´e, France
{martin.engilberge, matthieu.cord}@lip6.fr
patrick.perez@valeo.com louis.chevallier@technicolor.com
Abstract
Several works have proposed to learn a two-path neural
network that maps images and texts, respectively, to a same
shared Euclidean space where geometry captures useful se-
mantic relationships. Such a multi-modal embedding can be
trained and used for various tasks, notably image caption-
ing. In the present work, we introduce a new architecture
of this type, with a visual path that leverages recent space-
aware pooling mechanisms. Combined with a textual path
which is jointly trained from scratch, our semantic-visual
embedding offers a versatile model. Once trained under the
supervision of captioned images, it yields new state-of-the-
art performance on cross-modal retrieval. It also allows the
localization of new concepts from the embedding space into
any input image, delivering state-of-the-art result on the vi-
sual grounding of phrases.
Figure 1. Concept localization with proposed semantic-visual
embedding. Not only does our deep embedding allows cross-
modal retrieval with state-of-the-art performance, but it can also
associate to an image, e.g., the hamburger plate on the left, a lo-
calization heatmap for any text query, as shown with overlays for
three text examples. The circled blue dot indicates the highest peak
in the heatmap.
only does it permit to revisit visual recognition and caption-
ing tasks, but it also opens up new usages, such as cross-
modal content search or generation.
One popular approach to semantic-visual joint embed-
ding is to connect two mono-modal paths with one or mul-
04.01720v2[cs.CV]6Apr2018
与えられたワードから物の位置を推定
SE block Non-local block
Learning to Localize Sound Source in Visual Scenes
Arda Senocak1
Tae-Hyun Oh2
Junsik Kim1
Ming-Hsuan Yang3
In So Kweon1
Dept. EE, KAIST, South Korea1
MIT CSAIL, MA, USA2
Dept. EECS, University of California, Merced, CA, USA3
Abstract
Visual events are usually accompanied by sounds in our
daily lives. We pose the question: Can the machine learn
the correspondence between visual scene and the sound,
and localize the sound source only by observing sound and
visual scene pairs like human? In this paper, we propose a
novel unsupervised algorithm to address the problem of lo-
calizing the sound source in visual scenes. A two-stream
network structure which handles each modality, with at-
tention mechanism is developed for sound source localiza-
tion. Moreover, although our network is formulated within
the unsupervised learning framework, it can be extended
to a unified architecture with a simple modification for the
Figure 1. Where do these sounds come from? We show an ex-
ample of interactive sound source localization by the proposed al-
gorithm. In this paper, we demonstrate how to learn to localize the
sources (objects) from the sound signals.
[cs.CV]10Mar2018
与えられた音から物の位置を推定
Attention
Embedding 64](https://image.slidesharecdn.com/cvpr18reportfinalize-180624063638/85/CVPR-2018-64-320.jpg)























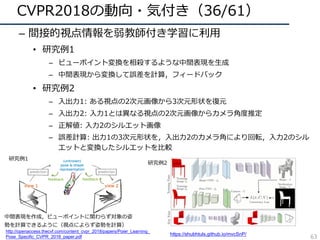
![引⽤されそうな論⽂(3/26)
• PackNet
– 過去のデータセットの記憶を残しつつ複数のデータを学習
– プルーニングとファインチューニングの繰り返しで学習
• ネットワークの各パラメータがそれぞれのデータセットに割り振られるような学習
• 学習をサボってるパラメータを違うデータの学習で有効活⽤しながら学習
(a) Initial filter for Task I (b) Final filter for Task I (c) Initial filter for Task II (d) Final filter for Task II (e) Initial filter for Task III
60% pruning + re-training 33% pruning + re-trainingtraining training
Figure 1: Illustration of the evolution of a 5⇥5 filter with steps of training. Initial training of the network for Task I learns a dense filter as
illustrated in (a). After pruning by 60% (15/25) and re-training, we obtain a sparse filter for Task I, as depicted in (b), where white circles
denote 0 valued weights. Weights retained for Task I are kept fixed for the remainder of the method, and are not eligible for further pruning.
We allow the pruned weights to be updated for Task II, leading to filter (c), which shares weights learned for Task I. Another round of
pruning by 33% (5/15) and re-training leads to filter (d), which is the filter used for evaluating on task II (Note that weights for Task I, in
gray, are not considered for pruning). Hereafter, weights for Task II, depicted in orange, are kept fixed. This process is completed until
desired, or we run out of pruned weights, as shown in filter (e). The final filter (e) for task III shares weights learned for tasks I and II. At
test time, appropriate masks are applied depending on the selected task so as to replicate filters learned for the respective tasks.
2. Related Work
A few prior works and their variants, such as Learning
without Forgetting (LwF) [18, 22, 27] and Elastic Weight
Consolidation (EWC) [14, 16], are aimed at training a net-
work for multiple tasks sequentially. When adding a new
task, LwF preserves responses of the network on older tasks
by using a distillation loss [10], where response targets are
based pruning method introduced in [7, 8] as it is able to
prune over 50% of the parameters of the initial network. As
we will discuss in Section 5.5, we also experimented with
the filter-based pruning of [20], obtaining limited success
due to the inability to prune aggressively. Our work is re-
lated to the very recent method proposed by Han et al. [7],
which shows that sparsifying and retraining weights of a
92](https://image.slidesharecdn.com/cvpr18reportfinalize-180624063638/85/CVPR-2018-92-320.jpg)
![引⽤されそうな論⽂(4/26)
• Data Distillation
– セルフトレーニングを導⼊したラベルなしデータの効率的な
学習
• 変化を与えた複数のサンプルをモデルに与えて結果を受け取りstudent modelを学習
• ラベルなしデータを使ってCOCOの物体検出・Keypoint検出で⾼精度化ng He
ensemble
predict
l´ar Ross Girshick Georgia Gkioxari Kaiming He
cebook AI Research (FAIR)
g, a special
he learner ex-
scale sources
ng is lower-
datasets, of-
t fully super-
d setting, we
mbles predic-
led data, us-
new training
models have
w possible to
lenging real-
t in the cases
ect detection,
tillation sur-
m the COCO
model A
model B
model C
image ensemble
student model predict
Model Distillation
student model predict
ensembleimage
transform A model A
transform B
transform C
Data Distillation
model A
model A
Figure 1. Model Distillation [18] vs. Data Distillation. In data
distillation, ensembled predictions from a single model applied to 93](https://image.slidesharecdn.com/cvpr18reportfinalize-180624063638/85/CVPR-2018-93-320.jpg)
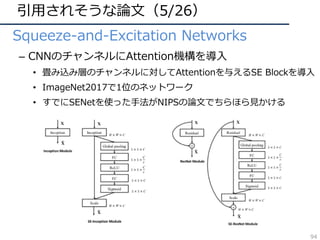
![引⽤されそうな論⽂(6/26)
• Finding beans in burgers
– 画像中から与えられた単語の物体を⾒つける研究
– 単語&画像ベクトルを同⼀特徴空間で学習
• 推定時はClass Activation Mappingに似た⽅法でヒートマップを出
⼒してローカライズ
ns in burgers:
mbedding with localization
lier2
, Patrick P´erez2
, Matthieu Cord1
2
Technicolor, Cesson S´evign´e, France
matthieu.cord}@lip6.fr
is.chevallier@technicolor.com
Figure 1. Concept localization with proposed semantic-visual
embedding. Not only does our deep embedding allows cross-
modal retrieval with state-of-the-art performance, but it can also
associate to an image, e.g., the hamburger plate on the left, a lo-
calization heatmap for any text query, as shown with overlays for
three text examples. The circled blue dot indicates the highest peak
in the heatmap.
ng [10], we resort to batch-based hard min-
art from this work, and from other related
he way we handle localization information.
mbedding and localization Existing
ine localization and multimodal embedding
ep process. First, regions are extracted ei-
ted model, e.g., EdgeBox in [39], or by a
rchitecture. Then the embedding space is
the similarity between these regions and
1, 17] use this approach on the dense cap-
Figure 2. Two-path multi-modal embedding architecture. Im
ages of arbitrary size and text of arbitrary length pass through ded
icated neural networks to be mapped into a shared representatio
vector space. The visual path (blue) is composed of a fully con
95](https://image.slidesharecdn.com/cvpr18reportfinalize-180624063638/85/CVPR-2018-95-320.jpg)
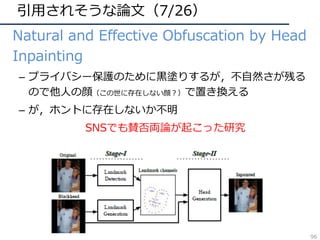
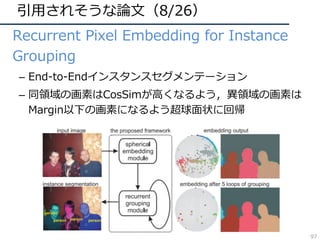
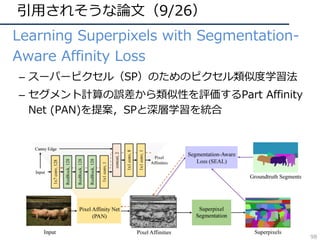

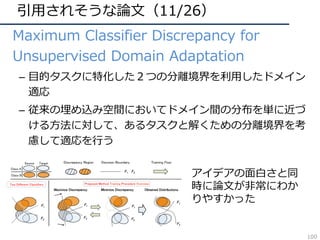
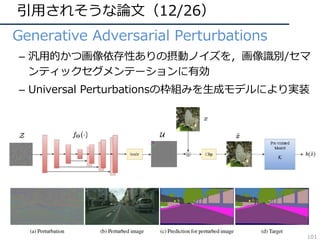
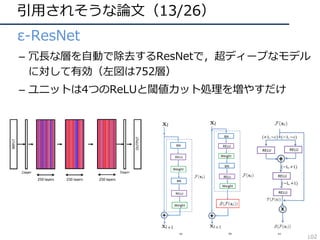
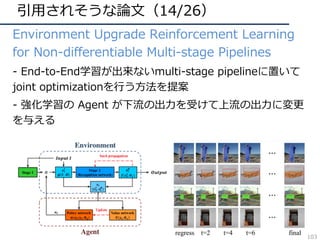



![引⽤されそうな論⽂(26/26)
• Compressed Video Action Recognition
– ビデオをフレームに分解せず、圧縮された情報を直接
3DCNNで処理することで⾏動認識を⾏う
– 学習・推論の⾼速化が可能
– データサイズという動画認識の⼤きな悩みに着⽬
115
deo Action Recognition
2,5⇤
du
Hexiang Hu3,5⇤
hexiangh@usc.edu
R. Manmatha4
manmatha@a9.com
Philipp Kr¨ahenb¨uhl1
philkr@cs.utexas.edu
Austin, 2
Carnegie Mellon University,
ern California, 4
A9, 5
Amazon
to
e-
w
ue
l-
on
eo
in
y,
g-
on
c-
D
on
h-
Our CNN
Traditional CNN
P-frameI-frame P-frame P-frame
Decoded
Stream
Compressed
Stream
Codec
Figure 1: Traditional architectures first decode the video
Accuracy (%)
GFLOPs UCF-101 HMDB-51
et-50 [8] 3.8 82.3 48.9
et-152 [8] 11.3 83.4 46.7
[39] 38.5 82.3 51.6
D [40] 19.3 85.8 54.9
AR 4.2 90.4 59.1
e 3: Network computation complexity and accuracy of
method. Our method is 4.6x more efficient than state-
e-art 3D CNN, while being much more accurate.
Preprocess CNN CNN
(sequential) (concurrent)
100
101
102
60
80
100
Compressed
video
RGB RGB+Flows
Two-stream
Res3D
ResNet-152
CoViAR
Inference time (ms per frame)
Accuracy](https://image.slidesharecdn.com/cvpr18reportfinalize-180624063638/85/CVPR-2018-115-320.jpg)









































![今後の⽅針(1/5)2017からの再掲
• 他の追随を許さぬ強い⼿法を作る!
– 受賞論⽂や注⽬論⽂にあるように「極めて⾼速かつ⾼精度
」を実現,コードをリリースして分野に貢献が理想
– 問題設定に対しての強い⼿法でも構わない
– 作れたらいいですね!=> e.g. DenseNets, YOLO9000,
PAF, PSPNet, Taskonomy[new!], R-FCN-3000-30fps[new!]
…](https://image.slidesharecdn.com/cvpr18reportfinalize-180624063638/85/CVPR-2018-157-320.jpg)







CVPR 2018 ( http://cvpr2018.thecvf.com/ )の参加速報を書きました。 この資料には下記の項目が含まれています。 ・DNNの概要(DNN以前の歴史や最近の動向) ・CVPRで議論されているサブタスクとホットな領域 ・CVPR 2018での動向や気付き ・これから引用されそう(流行りそう, 面白そう)な論文 ・cvpaper.challengeで考案した、研究アイディア ・今後の方針 (・論文まとめはこちらにあります Link: https://github.com/cvpaperchallenge/CVPR2018_Survey ) cvpaper.challenge はコンピュータビジョン分野の今を映し、創り出す挑戦です。論文読破・まとめ・アイディア考案・議論・実装・論文執筆(・社会実装)に至るまで広く取り組み、あらゆる知識を共有しています。 http://hirokatsukataoka.net/project/cc/index_cvpaperchallenge.html

![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [OS3-04] Human-in-the-Loop 機械学習](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-04-220607021031-e69700d5-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]An Image is Worth 16x16 Words: Transformers for Image Recognition at S...](https://cdn.slidesharecdn.com/ss_thumbnails/dl10161-201016015214-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Wav2CLIP: Learning Robust Audio Representations From CLIP](https://cdn.slidesharecdn.com/ss_thumbnails/dlwav2clip1-211105022837-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)



















