Download to read offline










![HUAWEI TECHNOLOGIES CO., LTD. Page 14
Any regressor + fixed sigma: 𝑝 𝑦 𝒙) = 𝑵(𝒇 𝒙; 𝛉 , 𝝈)
› Linear regression
› Classical neural nets
We learn the parameters (𝑤(𝒙) and 𝜃(𝒙)) with a deep neural net:
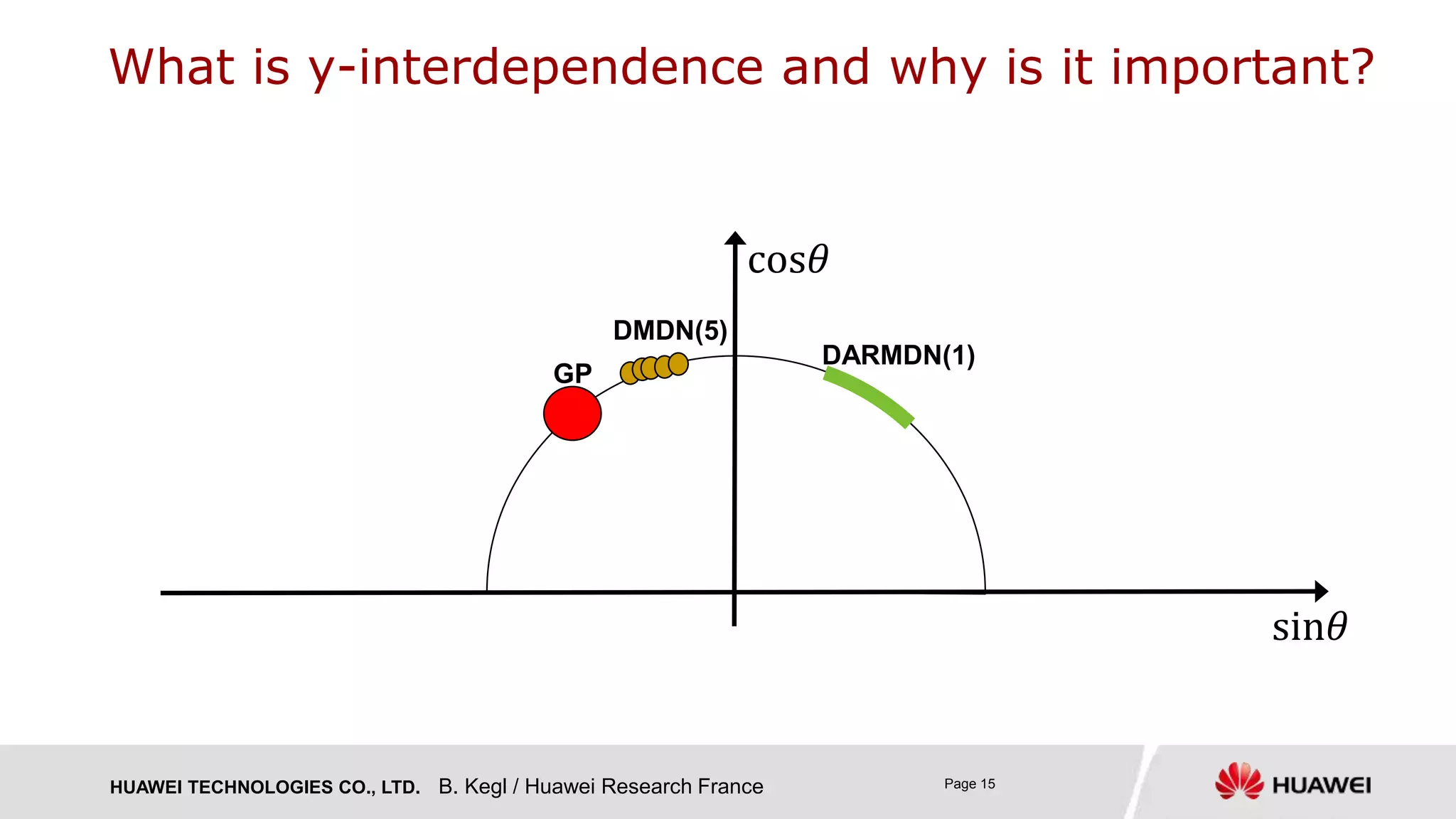
deep autoregressive mixture density nets = DARMDN ("darm-dee-en")
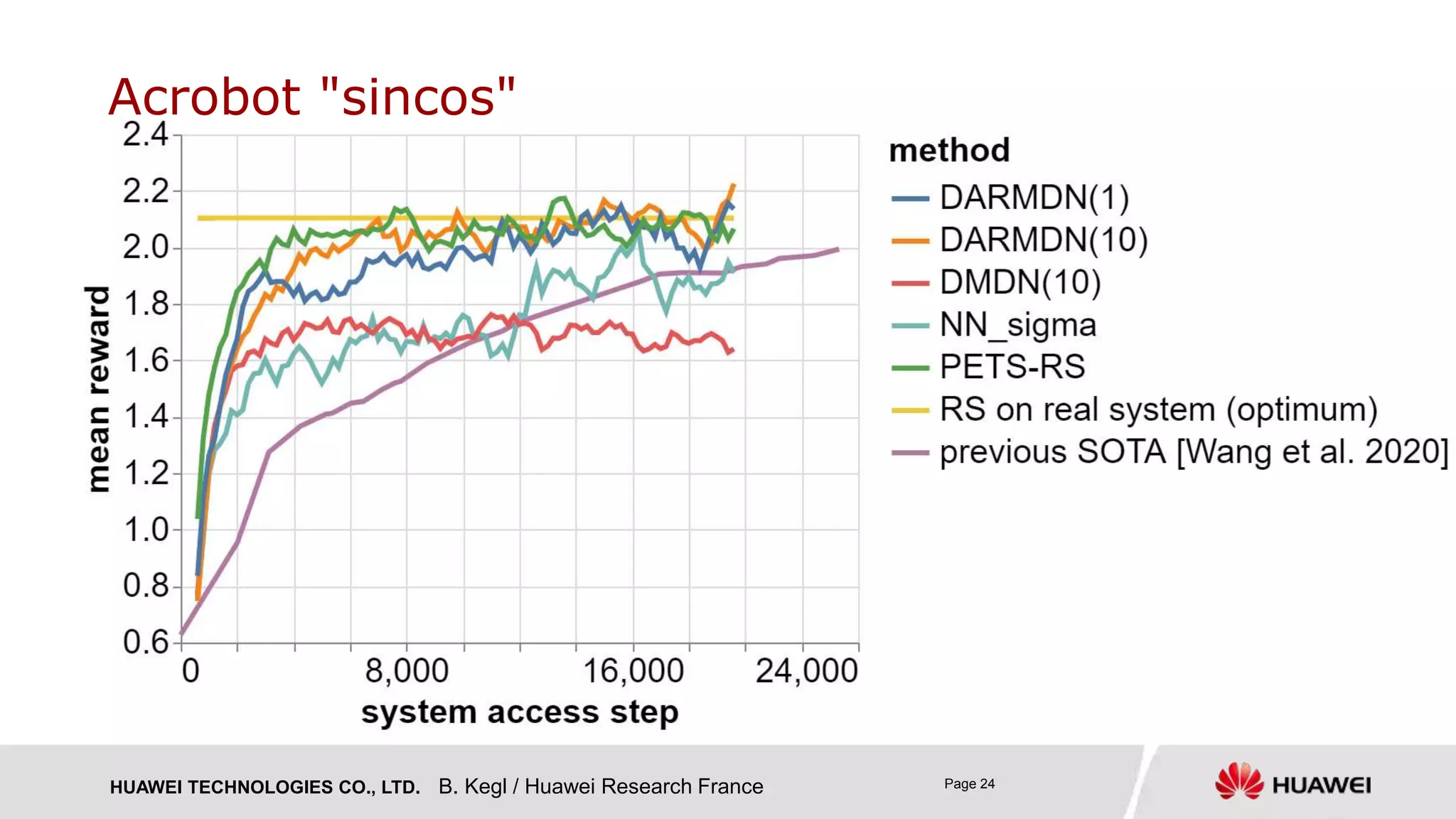
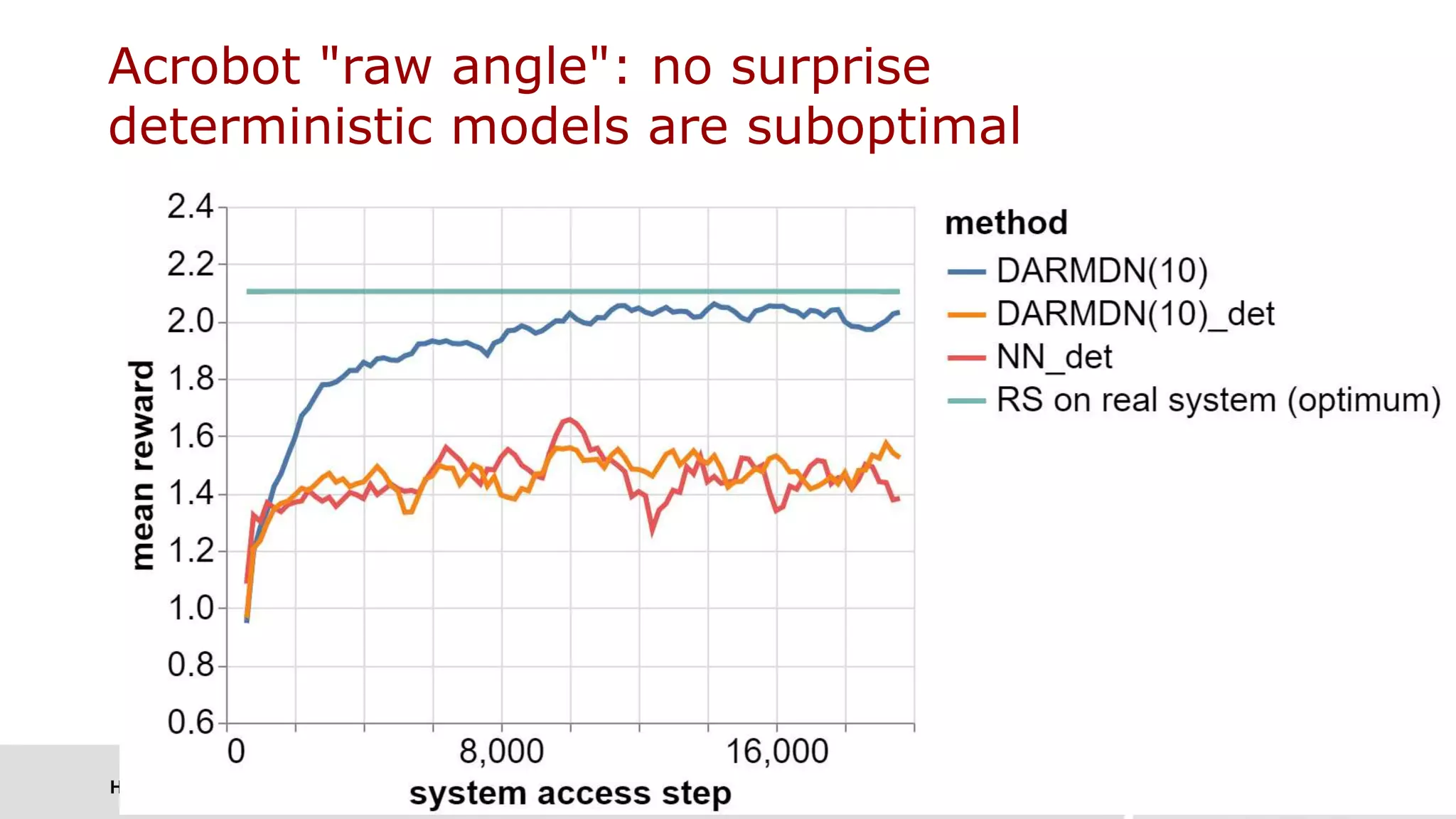
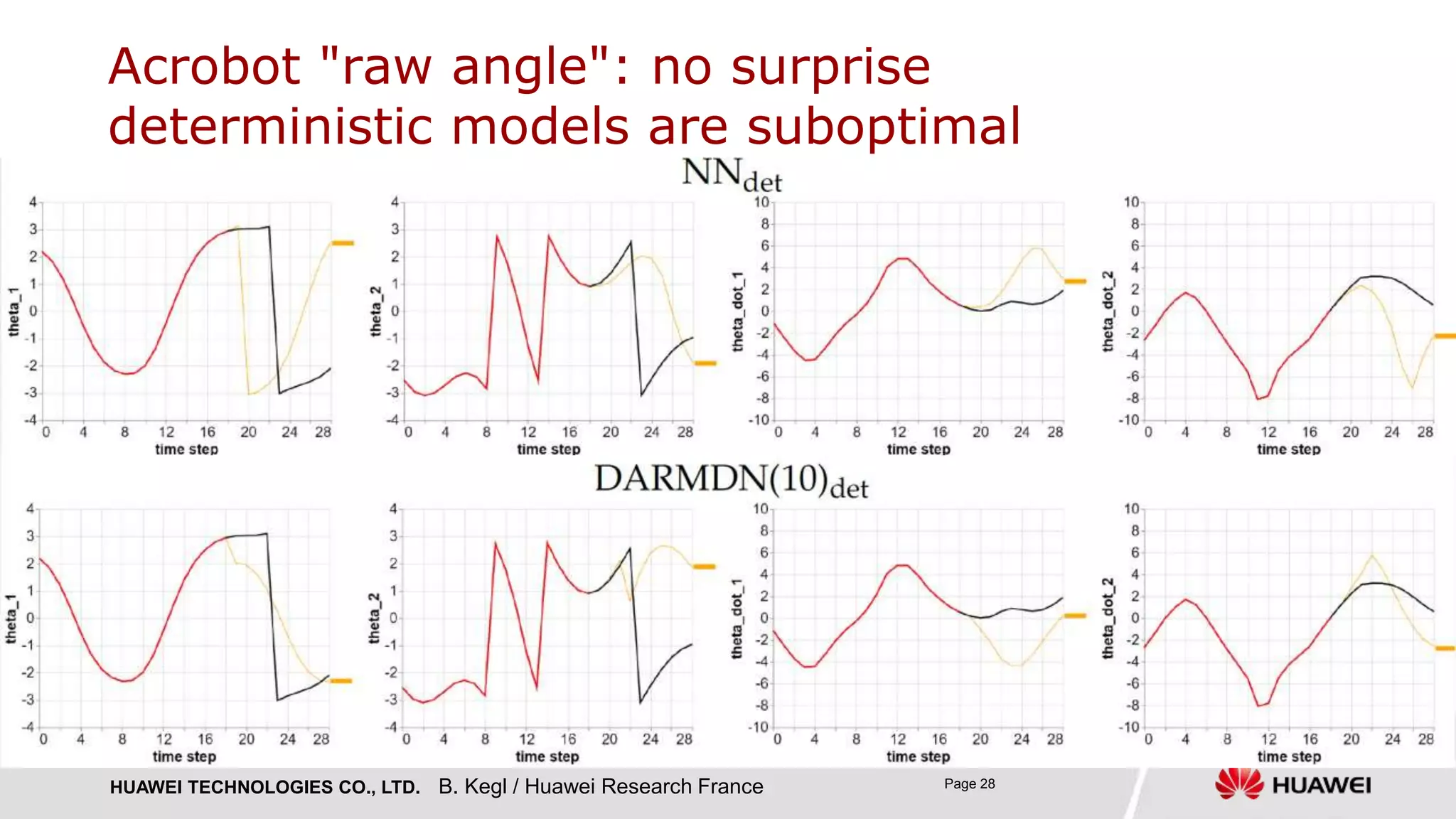
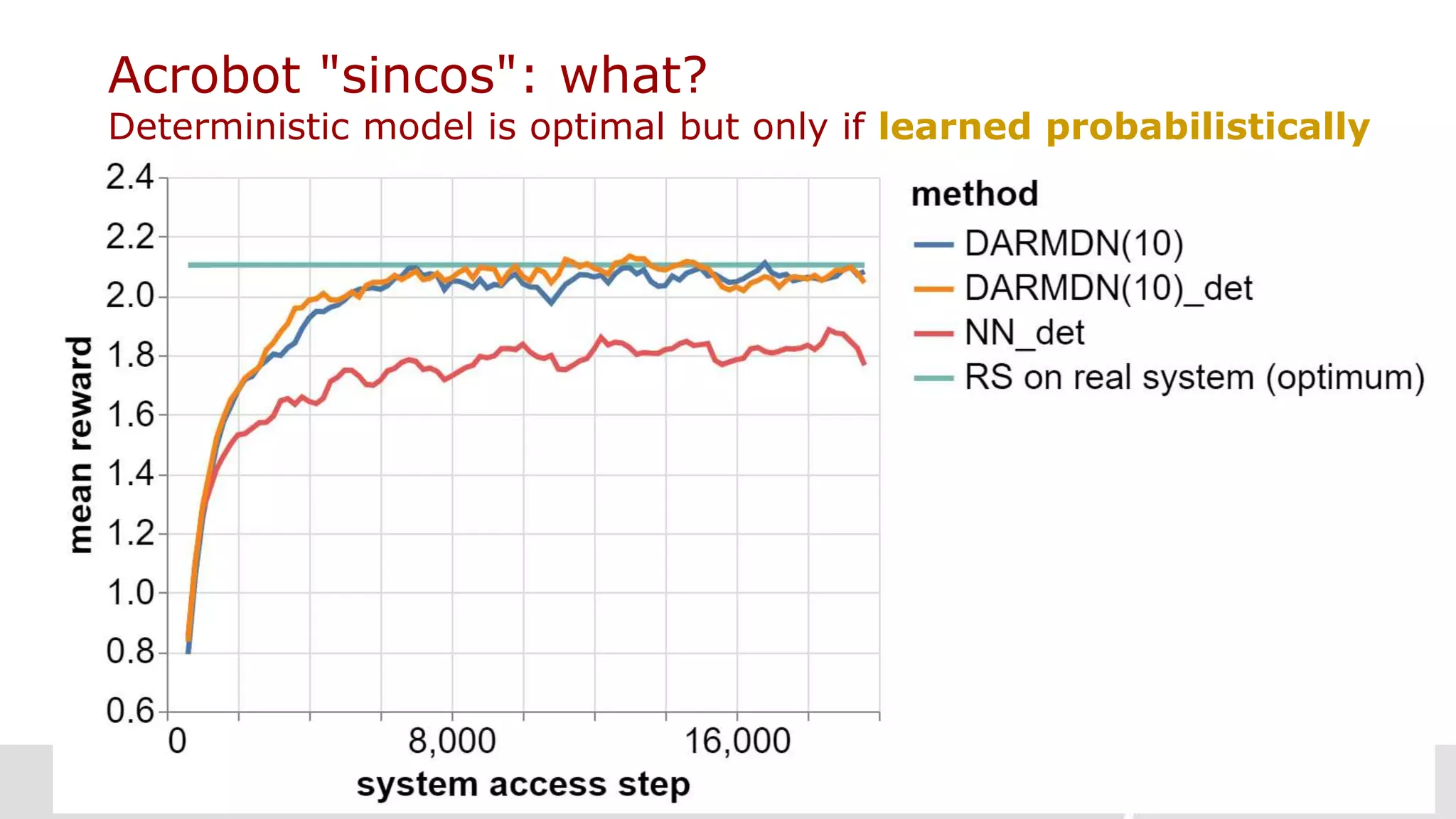
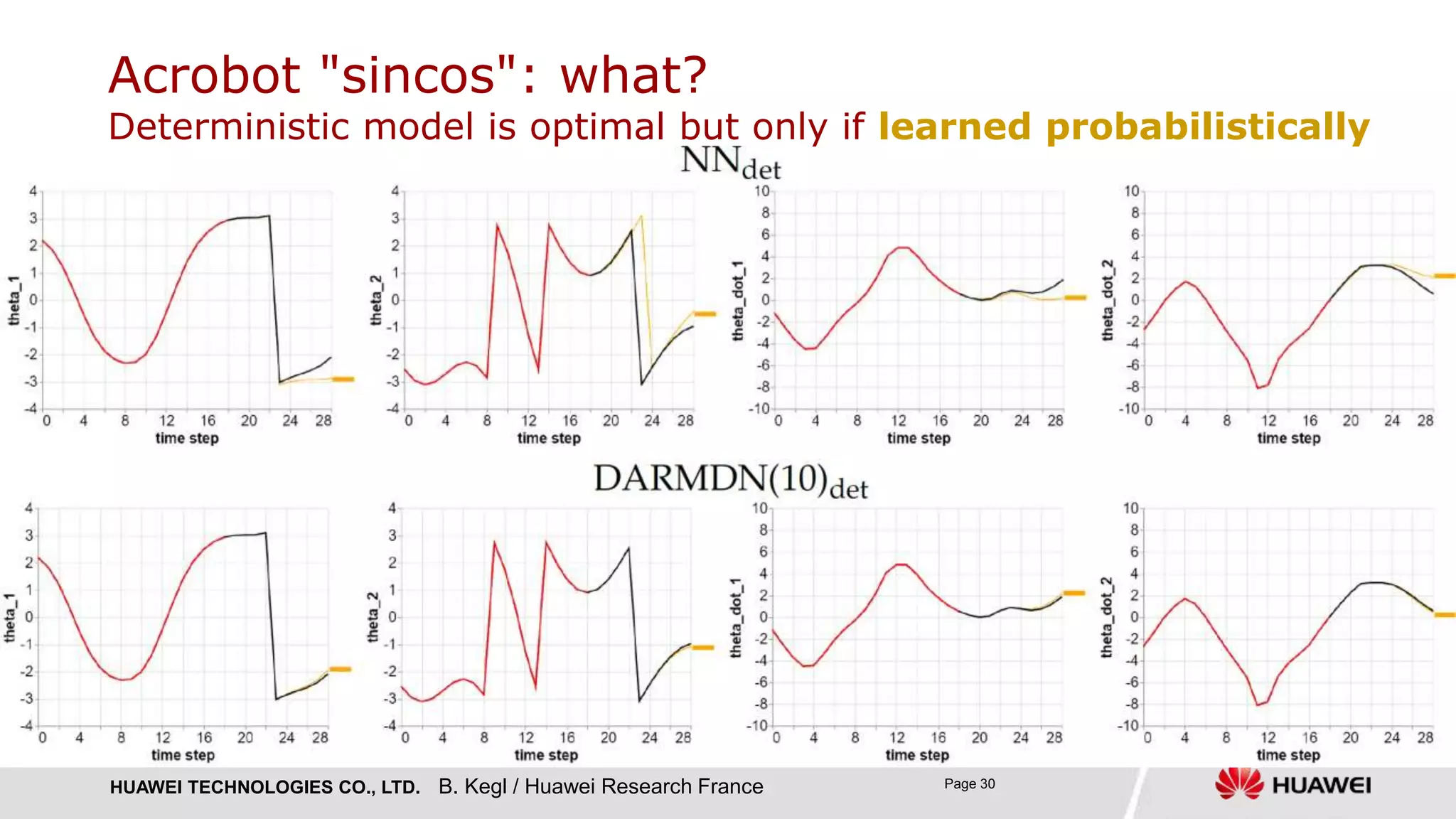
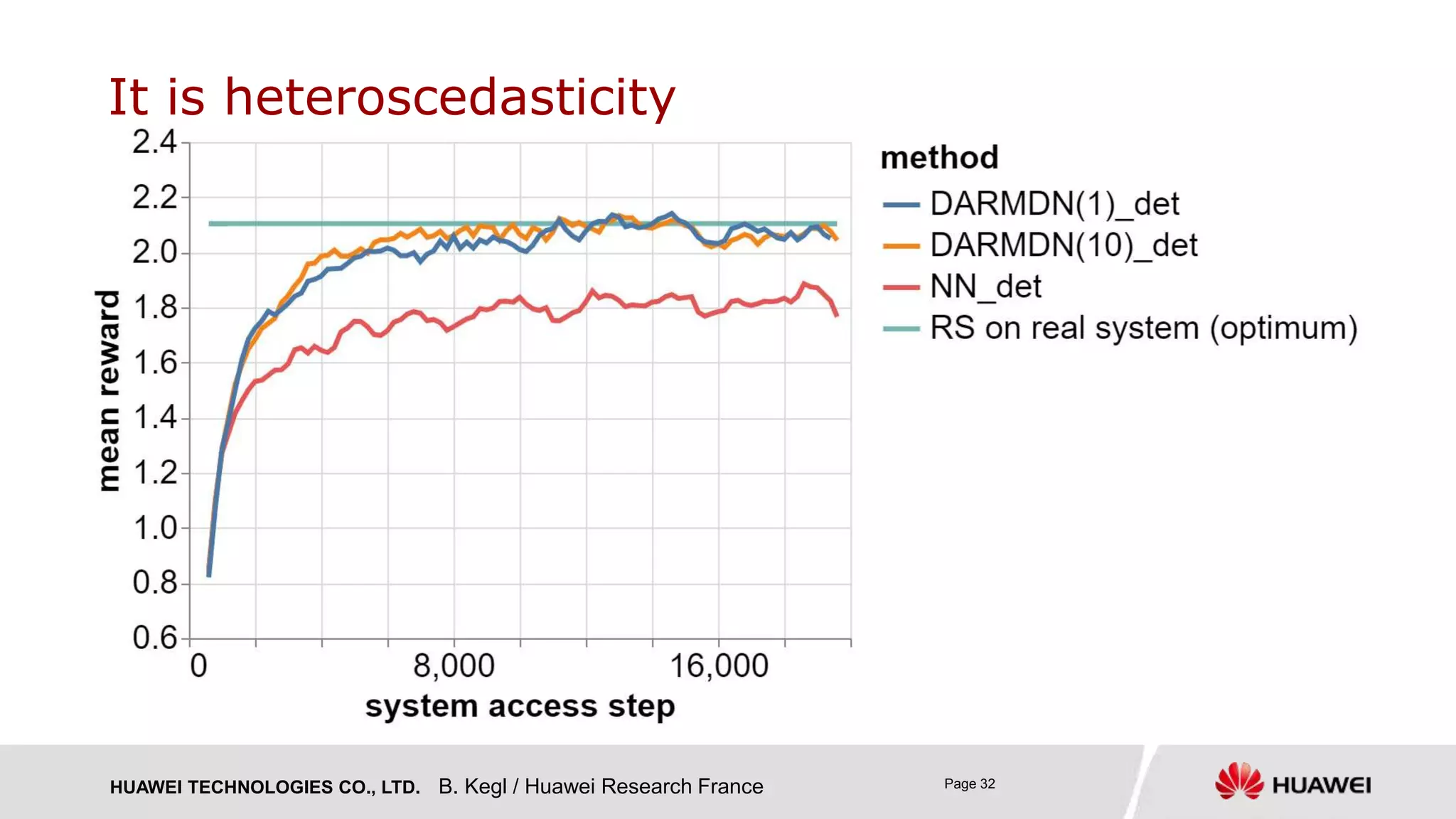
› DARMDN(1) with a single Gaussian component: heteroscedastic 𝑝 𝑦 𝒙) = 𝑵 𝝁 𝒙 , 𝝈 𝒙
› DARMDN(10)
Non-autoregressive models
› Gaussian process
› DMDN(10): classical mixture density nets with multivariate Gaussian components [Bishop 1994]
› Both assume y-independence
How do we learn the model?
B. Kegl / Huawei Research France](https://image.slidesharecdn.com/20200710balazsdarmdn60min1-200913150744/75/DARMDN-Deep-autoregressive-mixture-density-nets-for-dynamical-system-modelling-14-2048.jpg)


![HUAWEI TECHNOLOGIES CO., LTD. Page 22
1. Collect samples from a random policy
2. Train model on collected samples
3. Learn control policy on the model
4. Apply control policy on real system and collect the data, go back to 2.
Model-based RL loop
B. Kegl / Huawei Research France
We retrain the model after each episode of 200 steps
Control policy is classical random shooting (RS) [Richards 2005]
› Simulate trajectories of 𝑁 = 10 steps using random actions
› Select the optimal trajectory (with the highest reward after 𝑁 steps)
› Execute the first action of the optimal trajectory](https://image.slidesharecdn.com/20200710balazsdarmdn60min1-200913150744/75/DARMDN-Deep-autoregressive-mixture-density-nets-for-dynamical-system-modelling-21-2048.jpg)


![HUAWEI TECHNOLOGIES CO., LTD. Page 33
Model-based control, bandits, and reinforcement learning
› Learn to control the system in a sample efficient way:
» "real world will not become faster in a few years, contrary to computers"
[Chatzilygeroudis et al., 2019]
› State of the art suffers from the lack of efficient system modelling tools
› Modelling uncertainties is crucial for safety
Bayesian optimization
› Require good and efficient models to quantify uncertainty due to unknown
Transfer learning, meta-learning, and robust reinforcement learning
› Precise probabilistic system models allow to transfer models between systems of the same kind
Anomaly detection
› Anomaly = system state is beyond "likely" behavior
Broader applications of DARMDN
B. Kegl / Huawei Research France](https://image.slidesharecdn.com/20200710balazsdarmdn60min1-200913150744/75/DARMDN-Deep-autoregressive-mixture-density-nets-for-dynamical-system-modelling-32-2048.jpg)



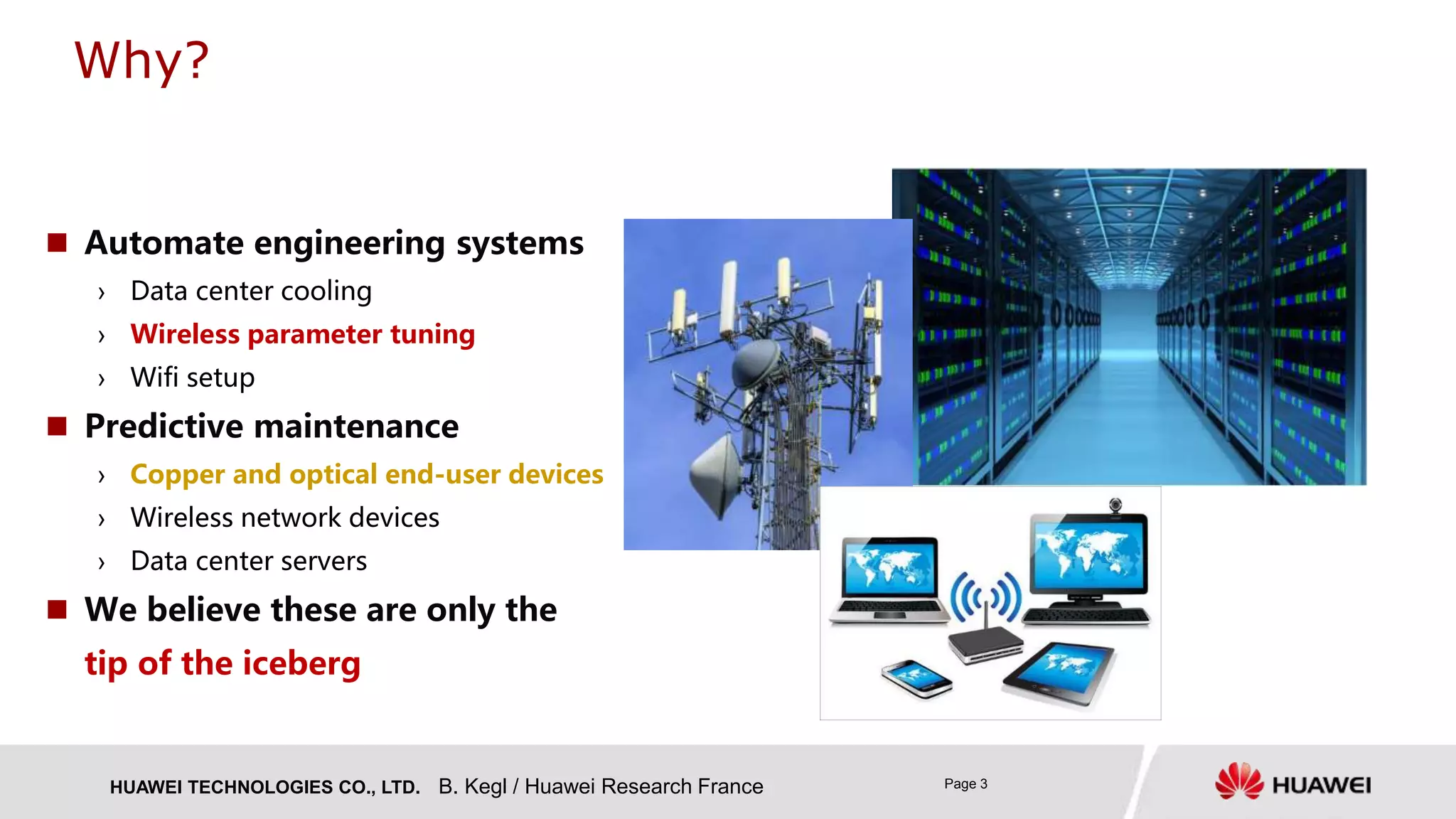
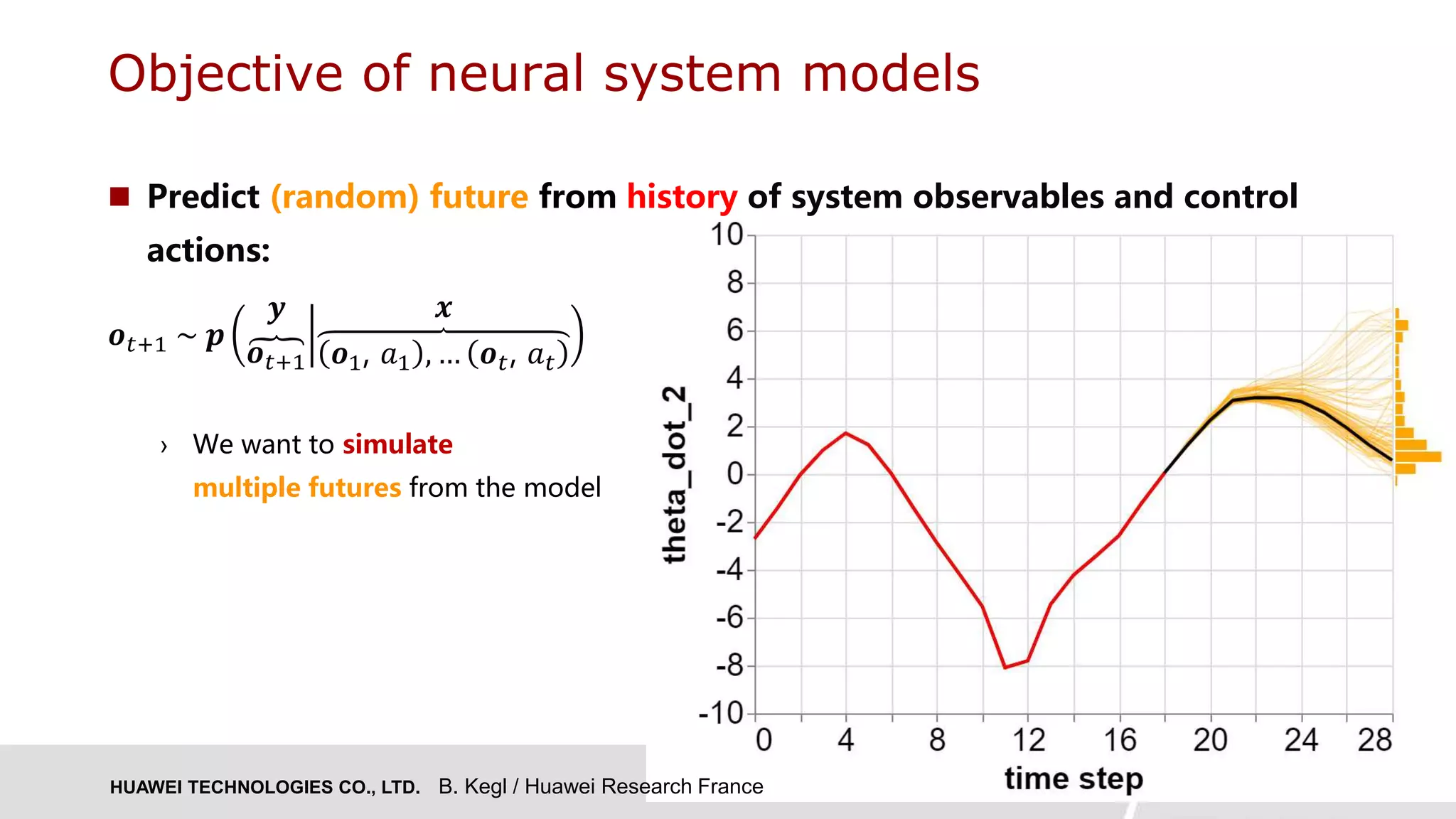
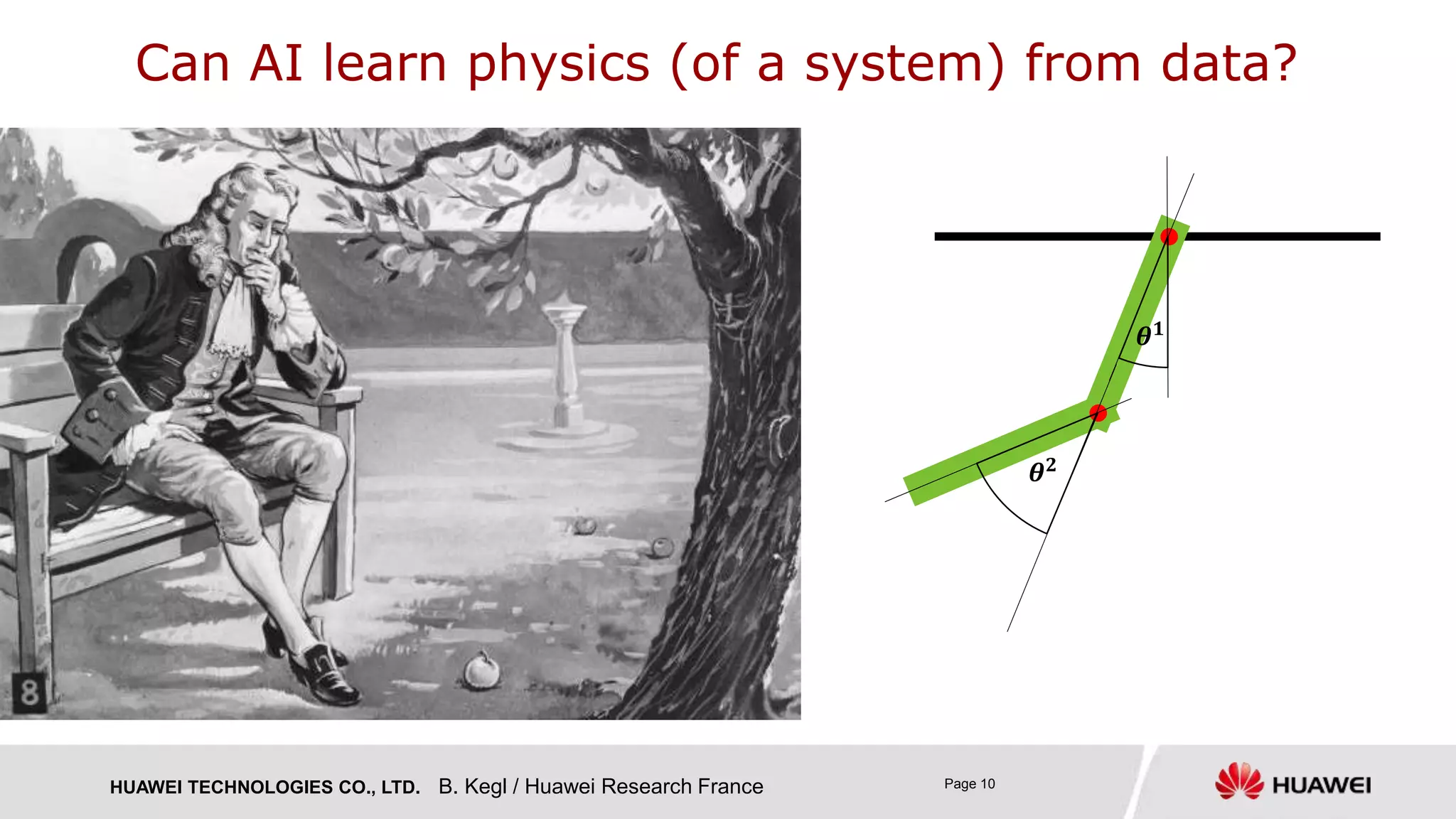
The document presents research on Deep Autoregressive Mixture Density Nets (DARMN) for modeling dynamics of systems, highlighting its applications in automating engineering tasks and predictive maintenance. It discusses the challenges of integrating AI in engineering, the approach of using generative time-series predictors, and methods for efficient sampling and control. The findings suggest that DARMN exhibits superior performance in model-based reinforcement learning, outperforming previous state-of-the-art techniques in certain scenarios.
























































