Download as PDF, PPTX






























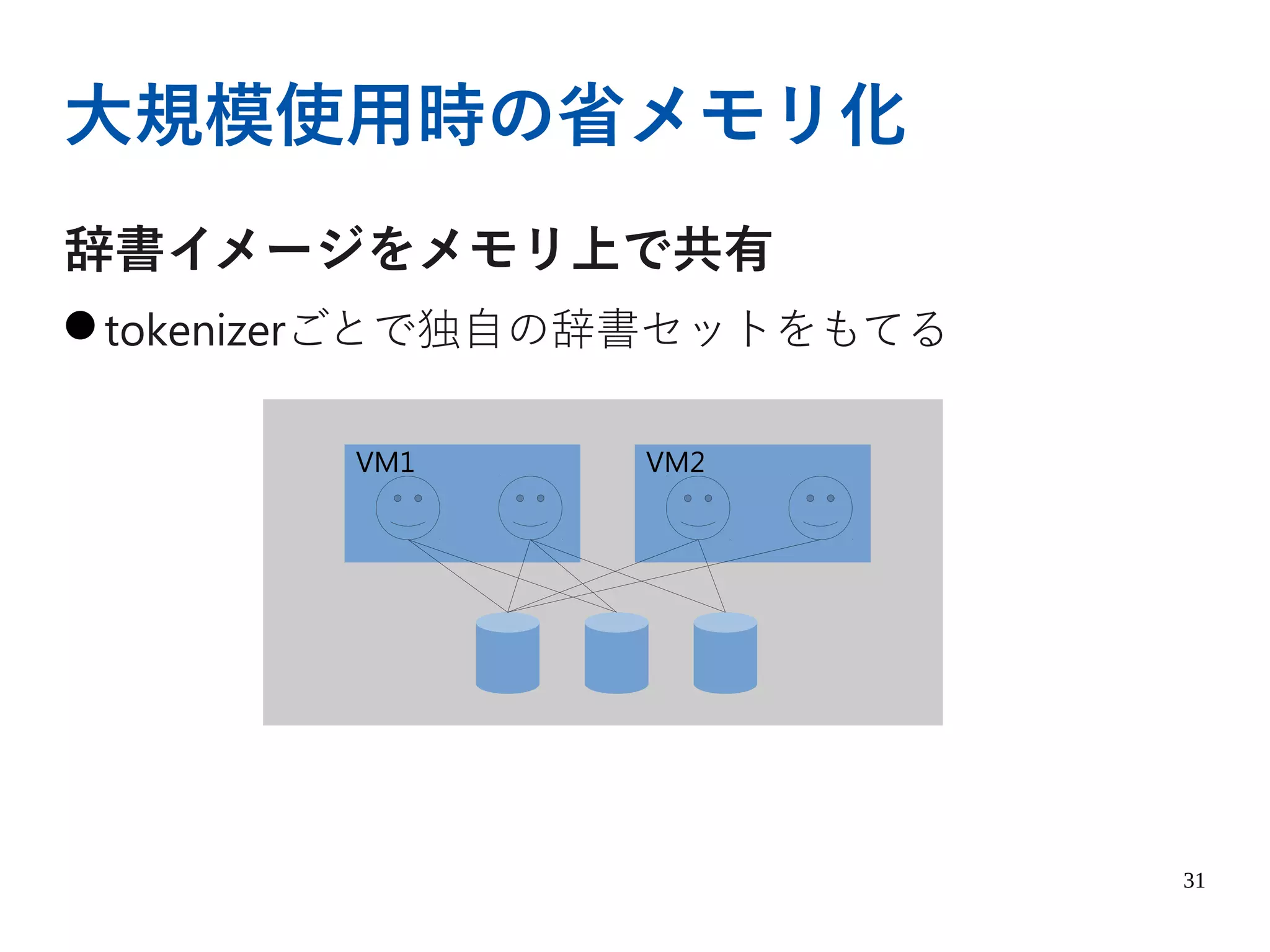


形態素解析の技術 形態素解析技術については深層学習の登場により枯れた技術だと思われている中で「本当に必要である技術なのか」と様々な議論がされています。 その業界の流れの中で、なぜ徳島NLP研究所でこの技術をあえて注目し研究しているのか、着眼点・利用価値についてご紹介します。 技術自体がブラックボックスとして扱われがちですが、実際に研究していく中で得られたノウハウを開示し、形態素解析の仕組みについて解説をし、内部で利用する技術の選別/処理内容/実利用での注意点をご説明します。 実例として、形態素解析エンジンについても触れる予定です。

![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[RSGT2017] つらい問題に出会ったら](https://cdn.slidesharecdn.com/ss_thumbnails/whenyoumetpainfulproblem-170114024920-thumbnail.jpg?width=640&height=640&fit=bounds)

























