Bidirectional LSTM-CRF Modelsfor Sequence Tagging
17
LSTMとCRFの組みわせによって固有表現抽出タスクを試みた
最初の研究。
Bi-LSTMとCRFを組み合わせることでPOS, chunking, 固有表現
抽出タスクでSOTAを達成した。
単語レベルのembeddingと特徴両エンジニアリングによって得
られる特徴量の両方を組み合わせて予測を行なっている。
whether has non initial capital letters
whether has punctuation
letter prefixes and suffixes (with window size of 2 to 5)…
結局特徴量エンジニアリングをしているのでありがたみ浅い
ベストなアーキテクチャーは?
19
Lample etal. の比較とPeirsman のブログ「Named Entity
Recognition and the Road to Deep Learning」の比較。
Bi-LSTMは使った方がよさそう。
学習済みの分散表現もかなり効く。
文字レベルのembeddingとCRFはそこまで大きな効果をも
たらさない?
http://nlp.town/blog/ner-and-the-road-to-deep-learning/
20.
最近の動向
20
Shen etal. (2018) の「Deep Active Learning For Named
Entity」 @ ICLR2018 が詳しい。
CNNをLSTMやGRUに変えたり。
特徴量エンジニアリングを文字ベースDNNに置
換したり。
最近流行りのDilated CNN使ったり。
二つの論点
だいだいCRF使ってない?
そんなに大量にデータあるの?
https://arxiv.org/pdf/1707.05928.pdf
21.
Deep Active LearningFor Named Entity
21
CRFをLSTMに置換して訓練時間を短縮
Active Learning を適用することでデータ数
を約1/4にしながらも、ほぼSOTAを達成。
[感想]
時系列からの特徴量抽出はもはやLSTMの専
売特許ではなく、出力が次の出力に影響を与
える場合にのみ使えば良さそう。
CRFを完全にだいたいするためには出力も
BiLSTMにするべきでは?
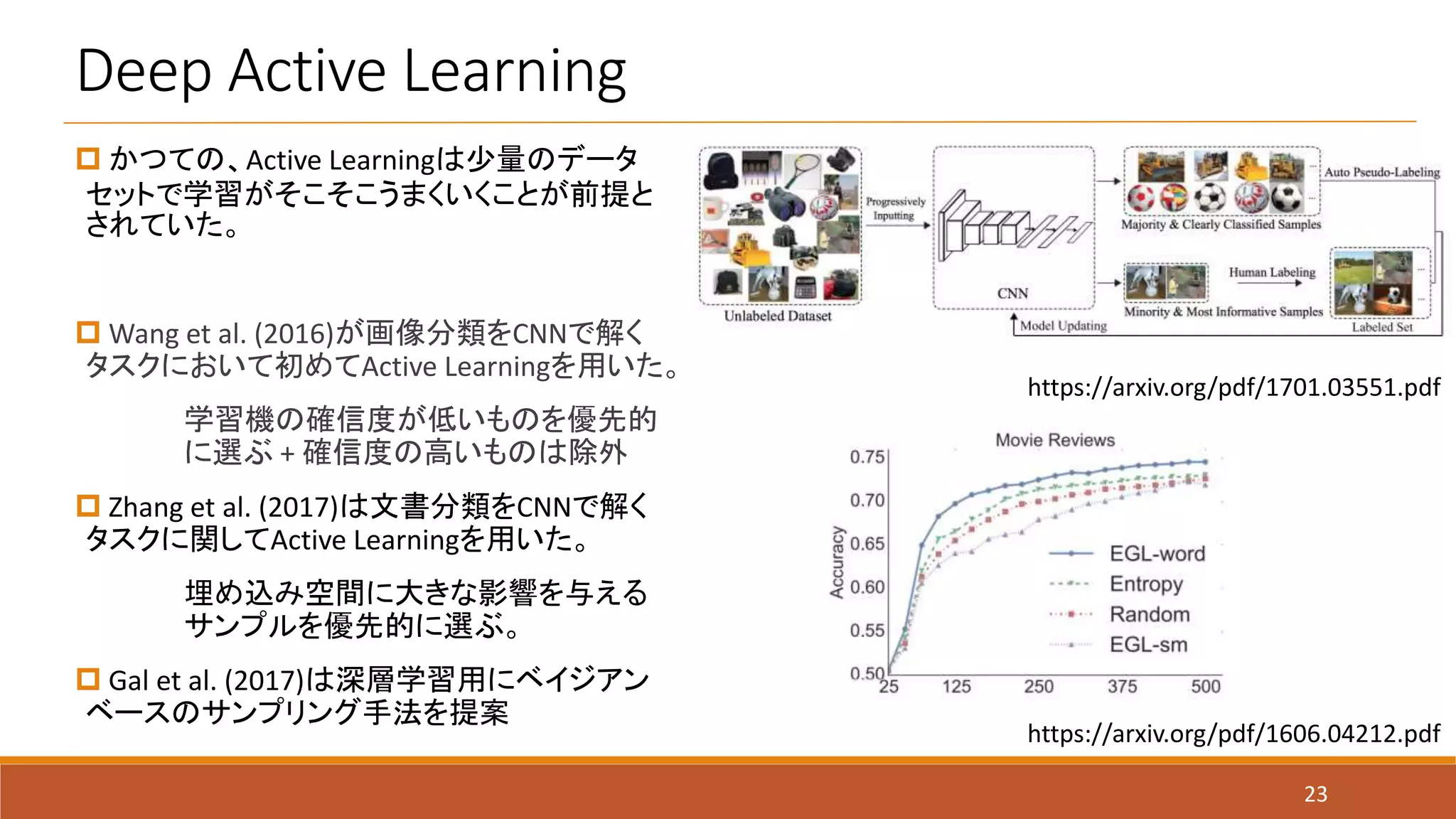
Deep Active Learning
23
かつての、Active Learningは少量のデータ
セットで学習がそこそこうまくいくことが前提と
されていた。
Wang et al. (2016)が画像分類をCNNで解く
タスクにおいて初めてActive Learningを用いた。
学習機の確信度が低いものを優先的
に選ぶ + 確信度の高いものは除外
Zhang et al. (2017)は文書分類をCNNで解く
タスクに関してActive Learningを用いた。
埋め込み空間に大きな影響を与える
サンプルを優先的に選ぶ。
Gal et al. (2017)は深層学習用にベイジアン
ベースのサンプリング手法を提案
https://arxiv.org/pdf/1701.03551.pdf
https://arxiv.org/pdf/1606.04212.pdf
24.
Deep Active LearningFor Named Entity
24
Shen et al. (2018)は系列タグ付け問題に対して
Active Learningを用いた。
Least Confidence
Maximum Normalized Log-Probability
Bayesian Active Learning by Disagreement
SUBMODular optimization problem
https://arxiv.org/pdf/1707.05928.pdf

![固有表現抽出とは
2
[定義]
文章中から組織名や国名などの特定のカテゴリの語”固有表現”を抽出するタスク。
[目的]
様々な固有表現を計算機によって自動的に抽出したいから。
現実のテキストには大量の固有表現が含まれているが、辞書に登録されていない固有表現が存在する
場合、形態素解析などを行う時に誤りを引き起こすから。
そのために様々な固有表現を辞書に登録する必要があるが、固有表現は時事刻々新しいものが生まれ、
その数も膨大なので、人手でそれらを登録することは困難であるから。](https://image.slidesharecdn.com/presentation20180730-180730082201/75/slide-2-2048.jpg)


















![Deep Active Learning For Named Entity
21
CRFをLSTMに置換して訓練時間を短縮
Active Learning を適用することでデータ数
を約1/4にしながらも、ほぼSOTAを達成。
[感想]
時系列からの特徴量抽出はもはやLSTMの専
売特許ではなく、出力が次の出力に影響を与
える場合にのみ使えば良さそう。
CRFを完全にだいたいするためには出力も
BiLSTMにするべきでは?](https://image.slidesharecdn.com/presentation20180730-180730082201/75/slide-21-2048.jpg)
![Active Learning
22
[着想]
アノテーションは面倒だしコストもかかるなので効率化が
求められる。
固有表現等ののアノテーションは平易なニュー
ス1つでも1時間半以上かかる。 (Settles+ 2008)
[仮定]
全学習データの中から適切にサンプルを選んで学習可
能な時、学習機の性能は向上する。
[基本方針]
アノテーションの内データから次にアノテーションをする
べきデータを選び出して、新たなラベルを要求する。 http://burrsettles.com/pub/settles.activelearning.pdf](https://image.slidesharecdn.com/presentation20180730-180730082201/75/slide-22-2048.jpg)