A d aF a c e : Q u a l i t y
A d a p t i v e M a r g i n f o r F a c e
R e c o g n i t i o n
M i n c h u l K i m , A n i l K . J a i n , X i a o m i n g L i u
D e p a r t m e n t o f C o m p u t e r S c i e n c e a n d E n g i n e e r i n g ,
M i c h i g a n S t a t e U n i v e r s i t y
A r cF a c e : A d d i t i v e A n g u l a r M a r g i n L o s s f o r
D e e p F a c e R e c o g n i t i o n
顔認証の損失関数でデファクトと言えるであろうArcFace (CVPR2019)
正解クラスの分類をcos類似度で角度mだけ難しくしてからsoftmax・cross entropyする
このmをマージンと呼ぶ
7
クラスの代表ベクトル
(がクラス数Cだけ並んだもの)
=最後のFC層/Classifier
クラスの代表ベクトル
と画像xのcos類似度
(がクラス数Cだけ並んだもの)
正解クラス以外は
いつも通り(マージン無)の意
Yu4uさんのQiita記事から引用
(本家ArcFaceの図より見やすい)
8.
M a gF a c e : A U n i v e r s a l R e p r e s e n t a t i o n f o r
F a c e R e c o g n i t i o n a n d Q u a l i t y A s s e s s m e n t
- Qualityが低い=認識が難しいと仮定し、難しいサンプルを過学習しないようにしたい
⇒ マージンmを可変にして、Hardサンプルの分類が難しくなりすぎないように調整
- QualityがL2ノルムとして現れるよう、L2ノルムに基づきマージンが変化する損失を提案
⇒ (結果的に)L2ノルムによるQualityの推定も可能に
8
𝑎𝑖=L2ノルム ⇒ L2ノルムでマージンが変化
L2ノルム
赤点線
=クラス中心のベクトル
Hard
中心となす角: 大
L2ノルム: 小
Easy
中心となす角: 小
L2ノルム: 大
(横軸)cosθ:クラス中心となす角
(縦軸): L2ノルム
ArcFaceとの差分
𝑚(𝑎𝑖): L2ノルム小 ⇒ マージン小 ⇒ 損失小
𝑔(𝑎𝑖): L2ノルム小 ⇒ gの値(=損失)大
⇒ gによる正則化でバランスを取ってる
9.
A d aF a c e で ” や り た い ” こ と
通常のArcFace: 悪影響する超低品質な画像が重要視されてしまう (MagFaceと同じ思い)
Hardさでマージンを決めると、高画質なHardを過少に強調してしまう (MagFaceの問題)
⇒ 品質的に無理ゲーなサンプルの影響は抑え、そうでないHardサンプルは重要視したい
9
10.
A d aF a c e で ” や っ て る ” こ と
- 品質に応じたマージンを設定 (MagFaceと一緒だが式が違う)
- 品質≒L2ノルムとして、ミニバッチのL2ノルム値で正規化(標準化)した値を利用
- (ついでに、)ArcFace(↓のangle)とCosFace(↓のadd)のマージンのつけ方をがっちゃんこ
10
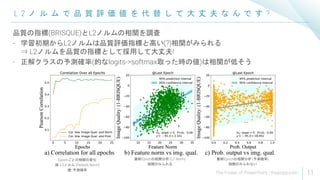
結 果 (A b l a t i o n ) : ハ イ パ ラ の 影 響
- h, m: どう設定してもまぁまぁ良い(CF同等以上)感じ. 特に低品質評価(LQ)は強い
- Proxy(マージンの調整指標): L2ノルム > 予測確率(𝑃𝑦𝑖
) > 画像品質(BRISQUE)
画像品質は計算コストの関係でデータ拡張なしのケースを事前計算
⇒ 学習中にデータ拡張を反映して計算できるためにL2ノルムが良い??
17
hの変化
mの変化
Proxyの変化
18.
結 果 (A b l a t i o n ) : デ ー タ 拡 張 の 適 用 確 率 の 影 響 検 証
- Curricular Faceはデータ拡張すると精度が下がる
- AdaFaceだと適用した方が精度が上がる
(無理ゲーな拡張になった時にマージンを控えめにする仕組みが上手く効いてそう)
18
Bag of Tricks for Image Classification
with Convolutional Neural Networks
(CVPR 2019)のデータ拡張を採用
顔認証だと
ImageNet向けの拡張だと
精度低下しがち
(拡張で認証できない画像出来がちなため)
だけど大丈夫
そうAdaFaceなら
H a rn e s s i n g U n r e c o g n i z a b l e F a c e s f o r
I m p r o v i n g F a c e R e c o g n i t i o n ( E R S )
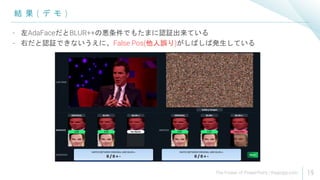
本人ペアスコアが低い話も問題だが、他人ペア(False Pos)スコアが高い方がやばい問題
低品質な画像は特徴空間でクラスタ形成(=高い他人ペアスコアを量産)すると言及
前頁のデモで、こういう他人ペアがArcFaceで出てAdaFaceで出てないところが気になる
(他人ペアスコアが減少して閾値が下がったことで高精度化したのか、
本人ペアスコアが増加して閾値を超えるケースが増えたことで高精度したのか、気になる)
20


























![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)








![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)


































