Download as PDF, PPTX






























![Don’t believe me?
• In MapStatus.scala
def apply(loc: BlockManagerId, uncompressedSizes:
Array[Long]): MapStatus = {
if (uncompressedSizes.length > 2000) {
HighlyCompressedMapStatus(loc, uncompressedSizes)
} else {
new CompressedMapStatus(loc, uncompressedSizes)
}
}](https://image.slidesharecdn.com/5bgrovermalaska-160614225519/85/Top-5-Mistakes-When-Writing-Spark-Applications-41-320.jpg)




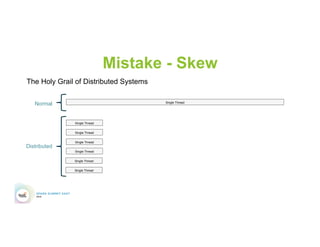
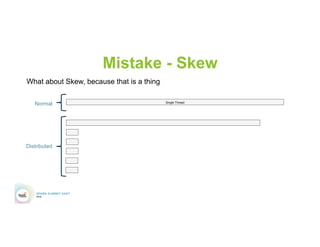


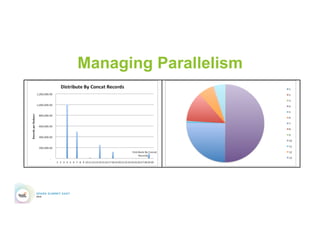
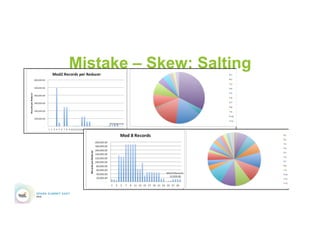

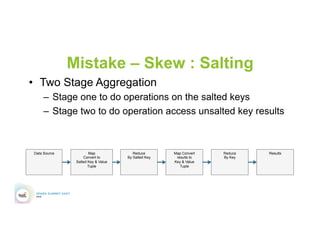
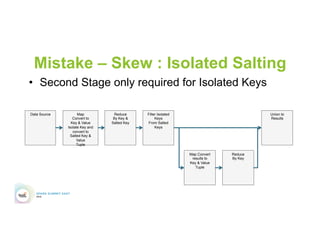
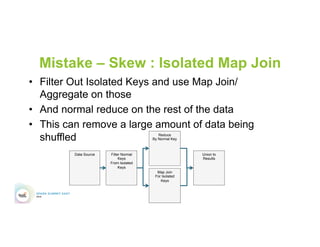
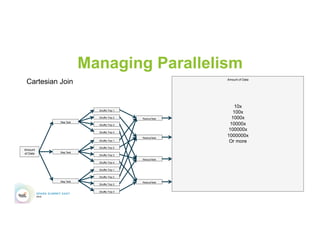
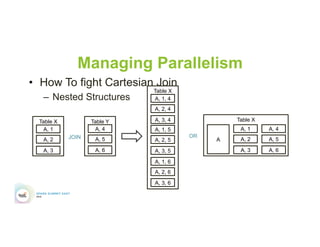






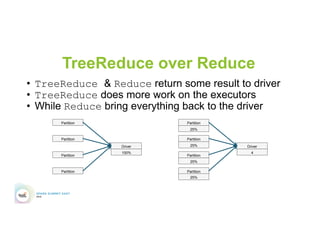












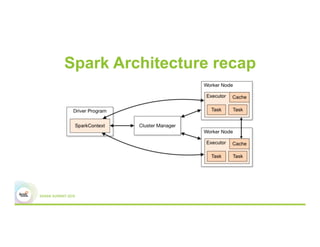
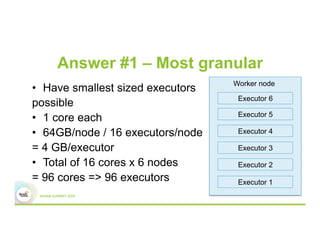
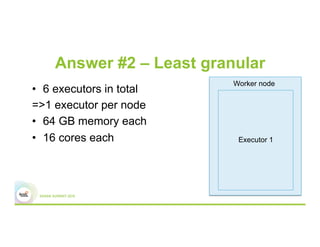
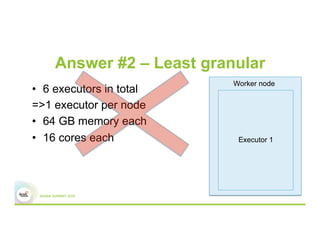
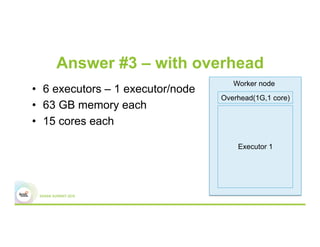
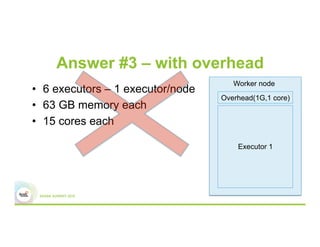
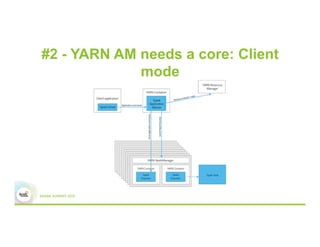
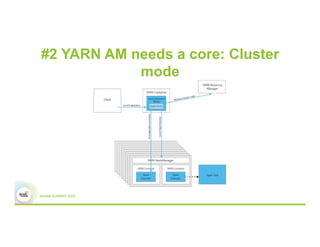
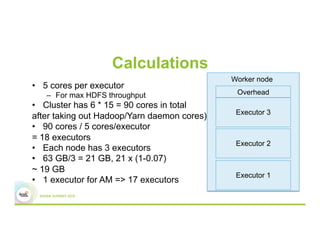
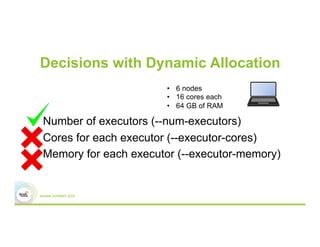
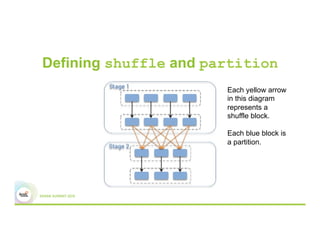
This document discusses 5 common mistakes when writing Spark applications: 1) Improperly sizing executors by not considering cores, memory, and overhead. The optimal configuration depends on the workload and cluster resources. 2) Applications failing due to shuffle blocks exceeding 2GB size limit. Increasing the number of partitions helps address this. 3) Jobs running slowly due to data skew in joins and shuffles. Techniques like salting keys can help address skew. 4) Not properly managing the DAG to avoid shuffles and bring work to the data. Using ReduceByKey over GroupByKey and TreeReduce over Reduce when possible. 5) Classpath conflicts arising from mismatched library versions, which can be addressed using sh