Downloaded 15 times





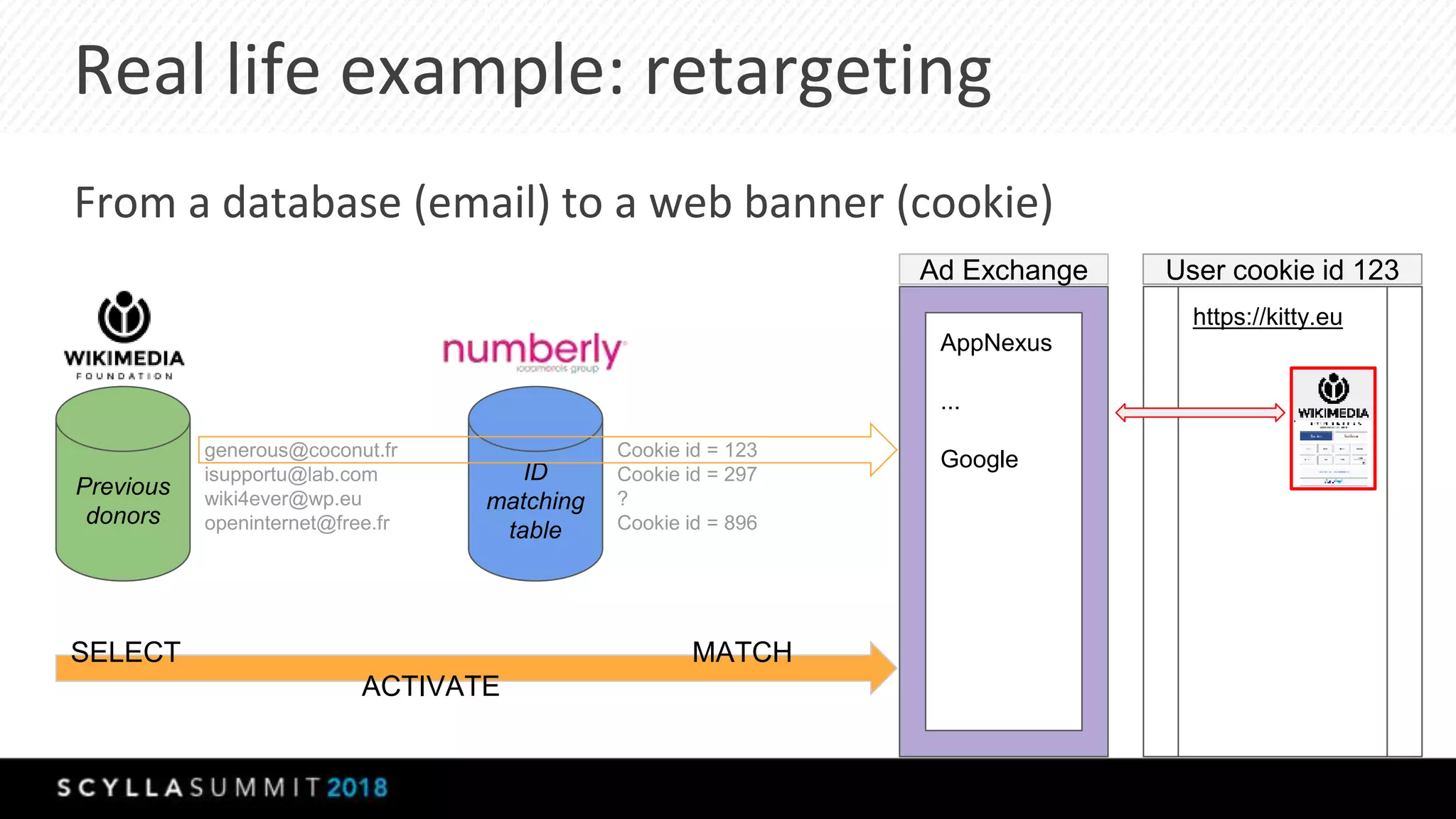
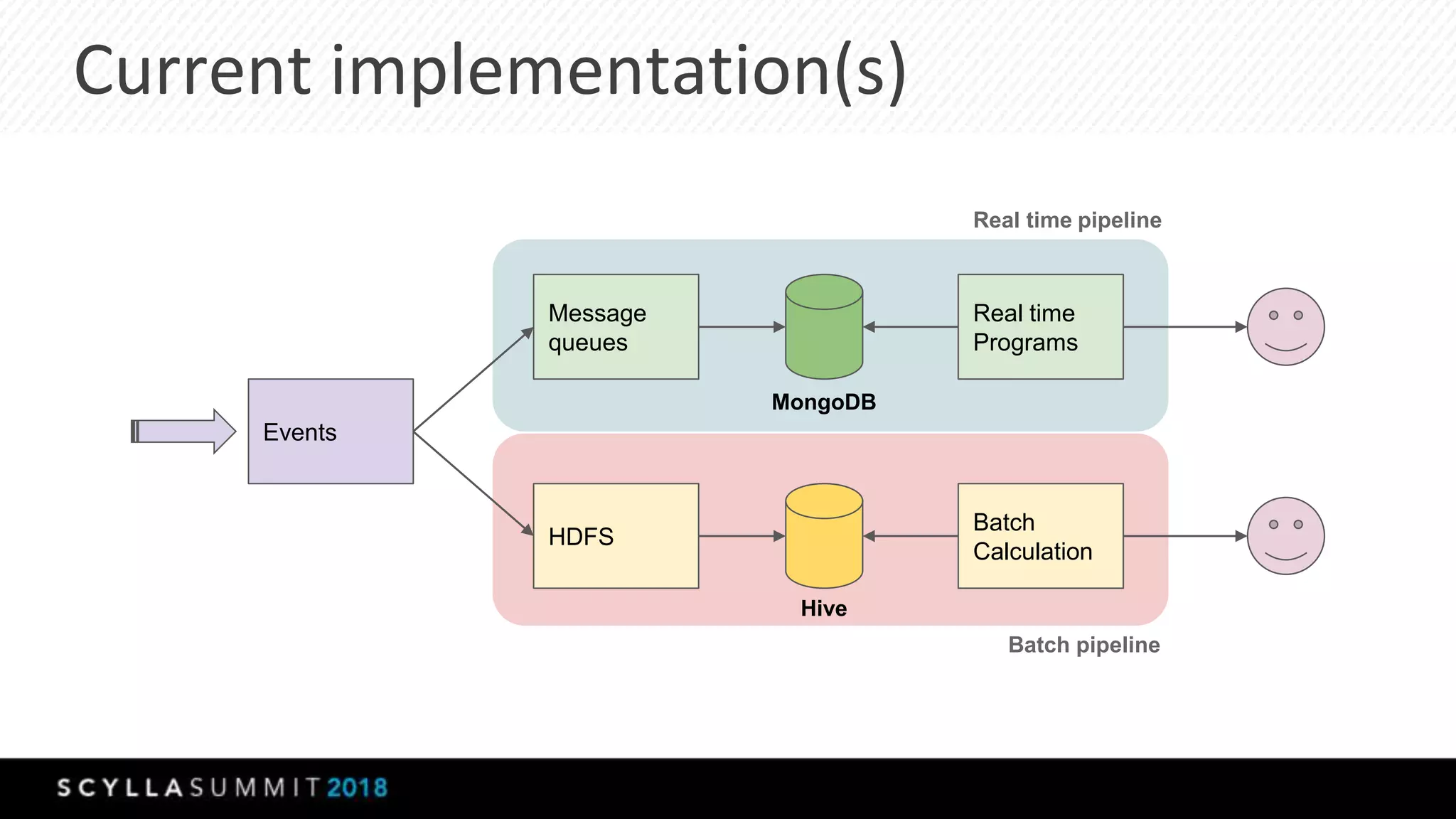
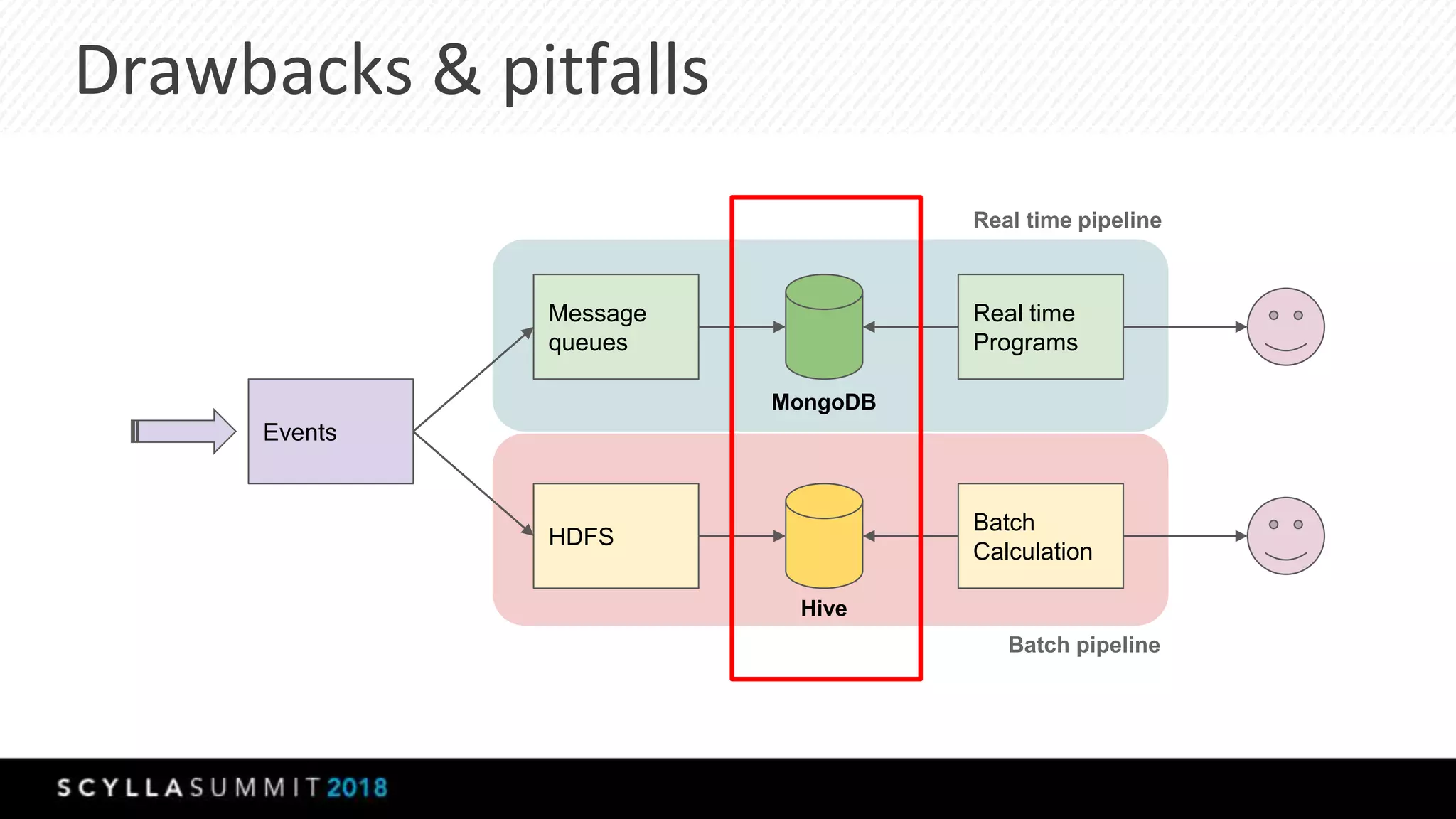

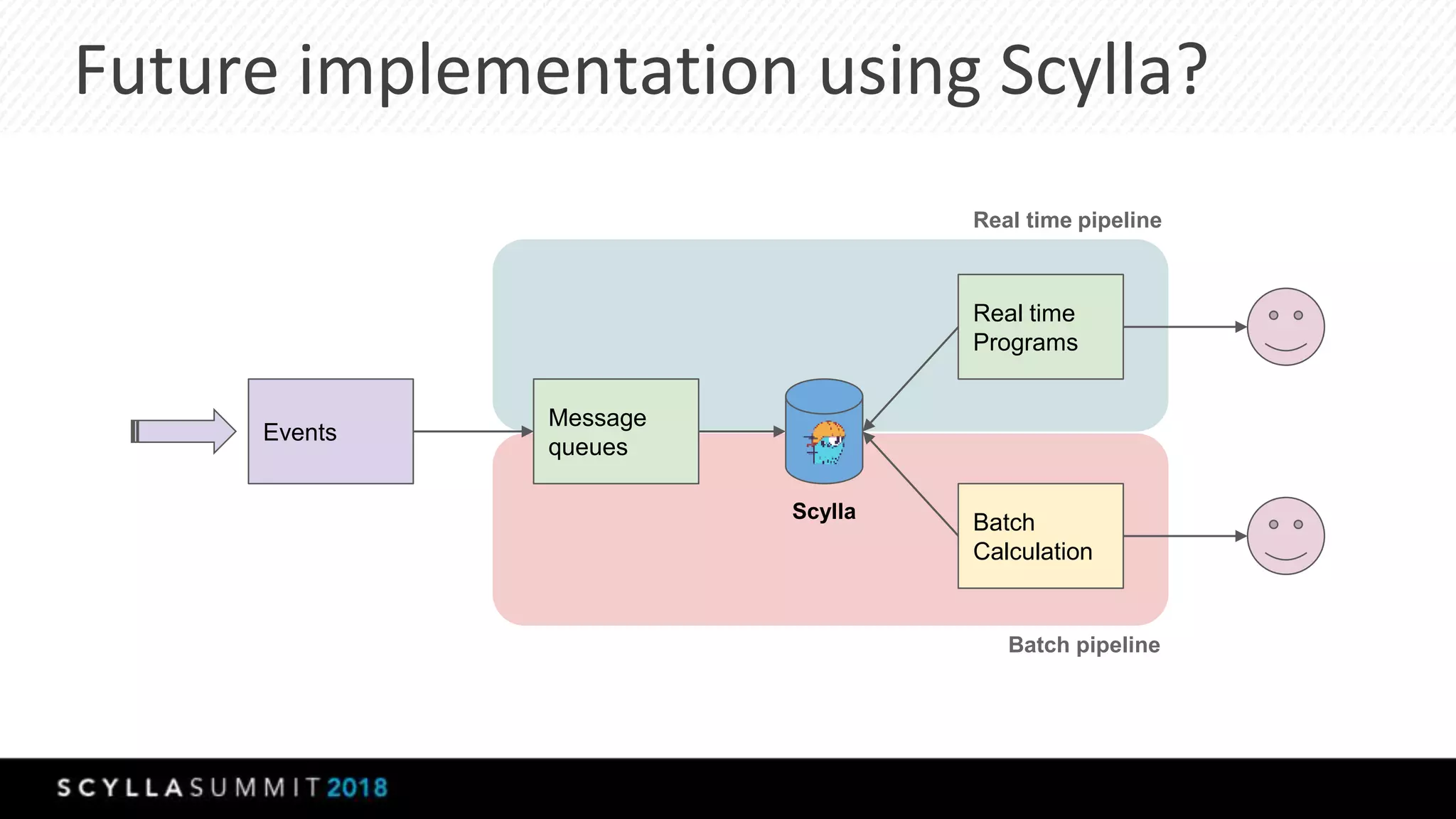



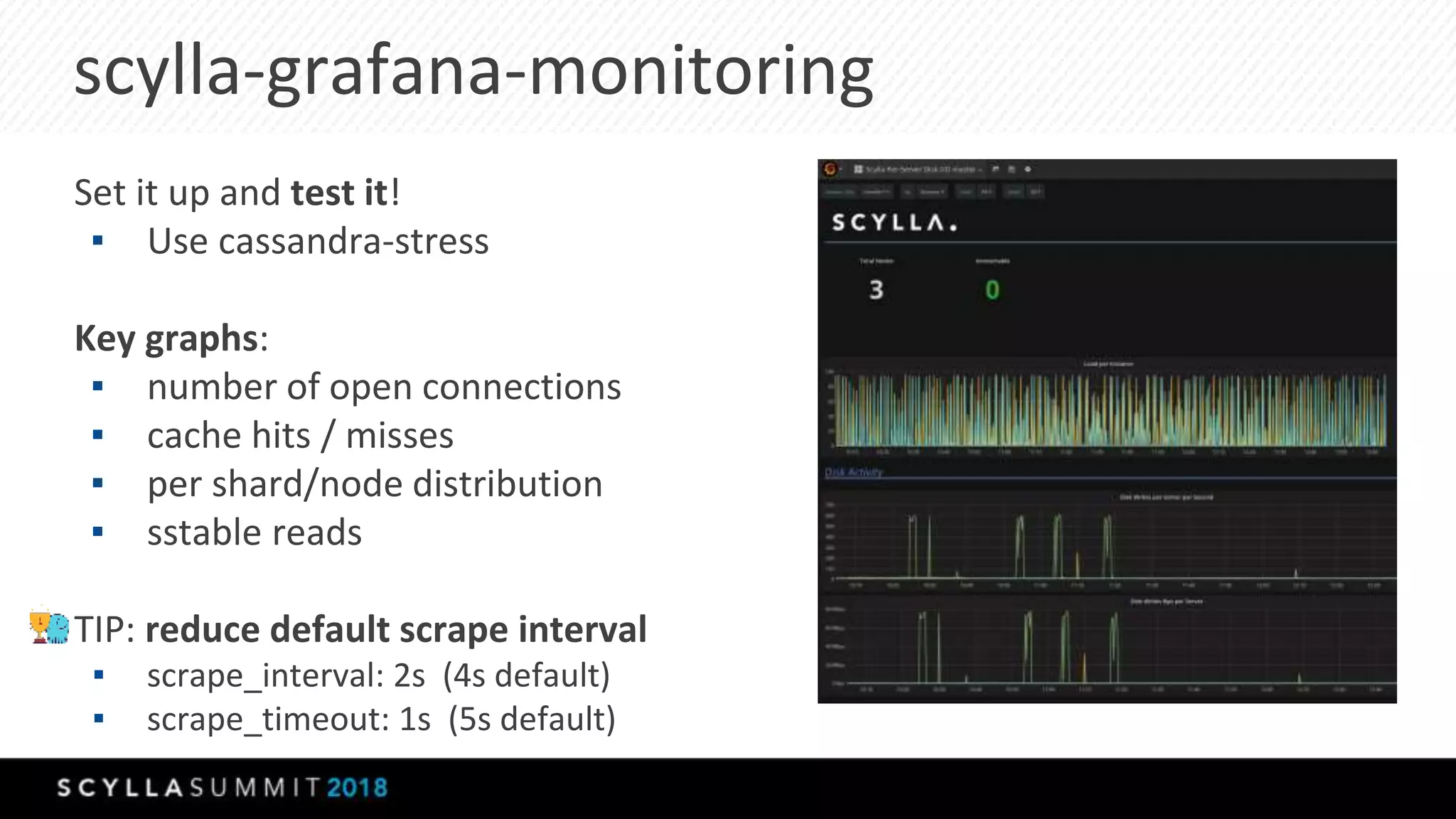

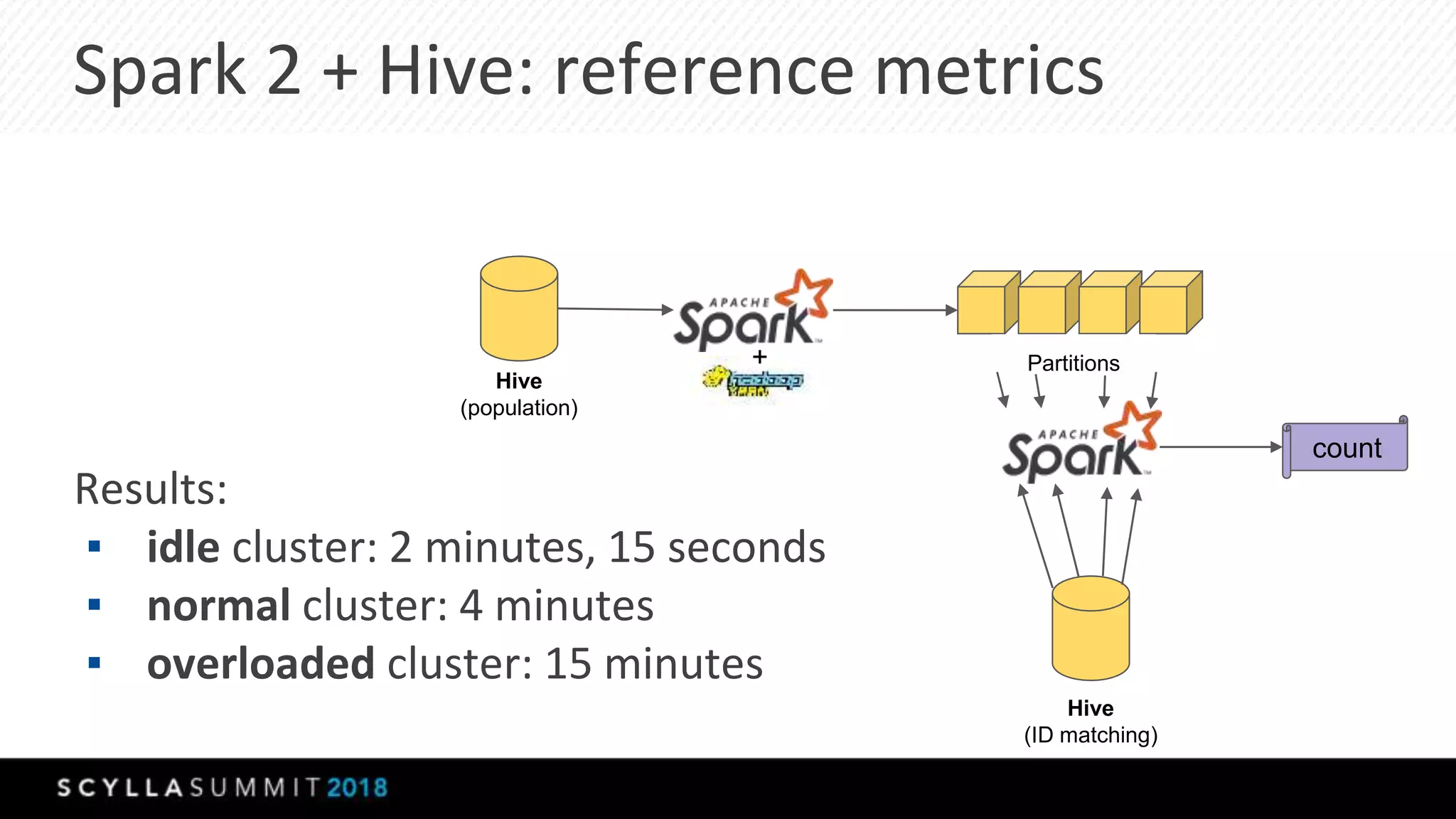


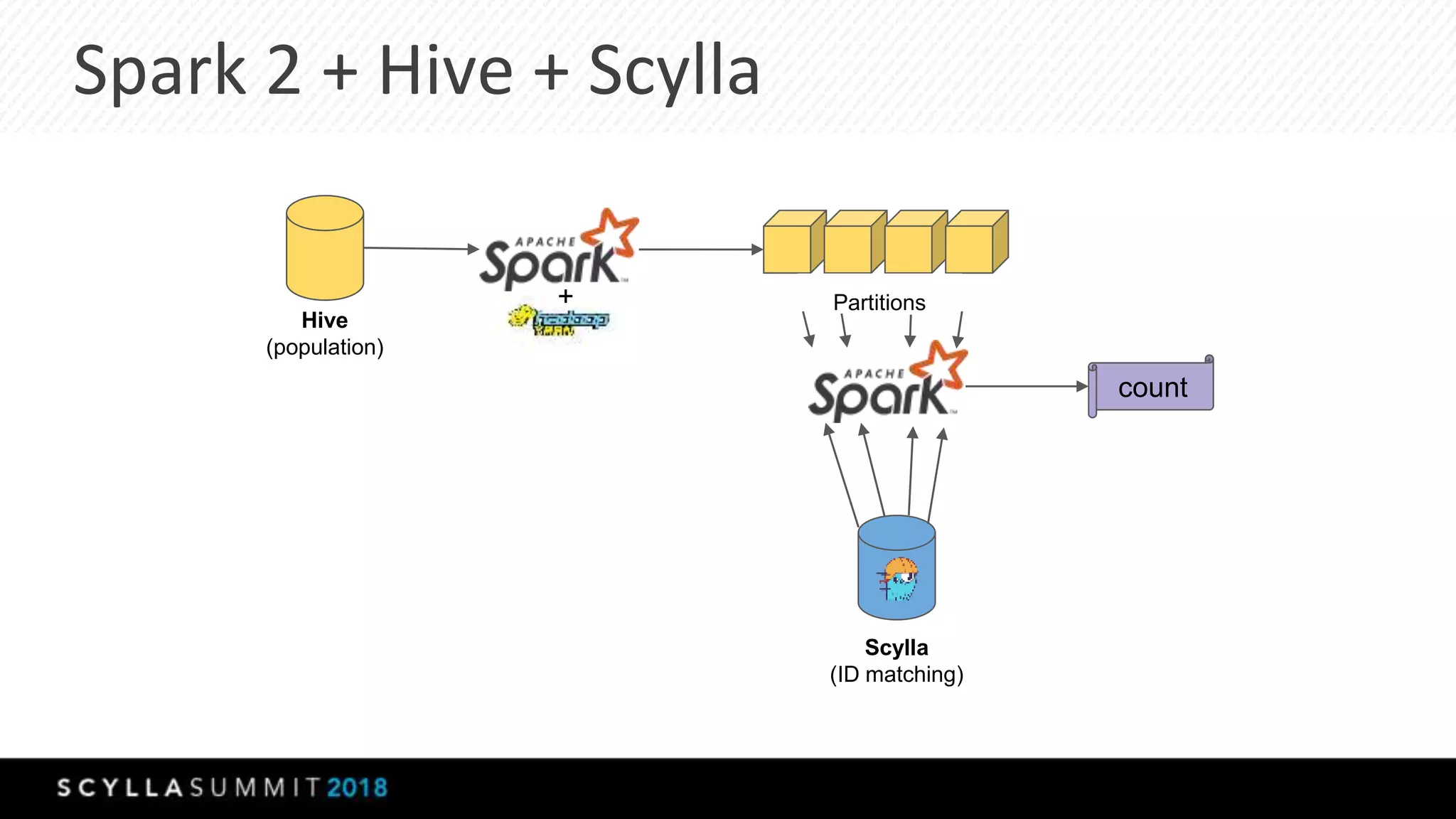





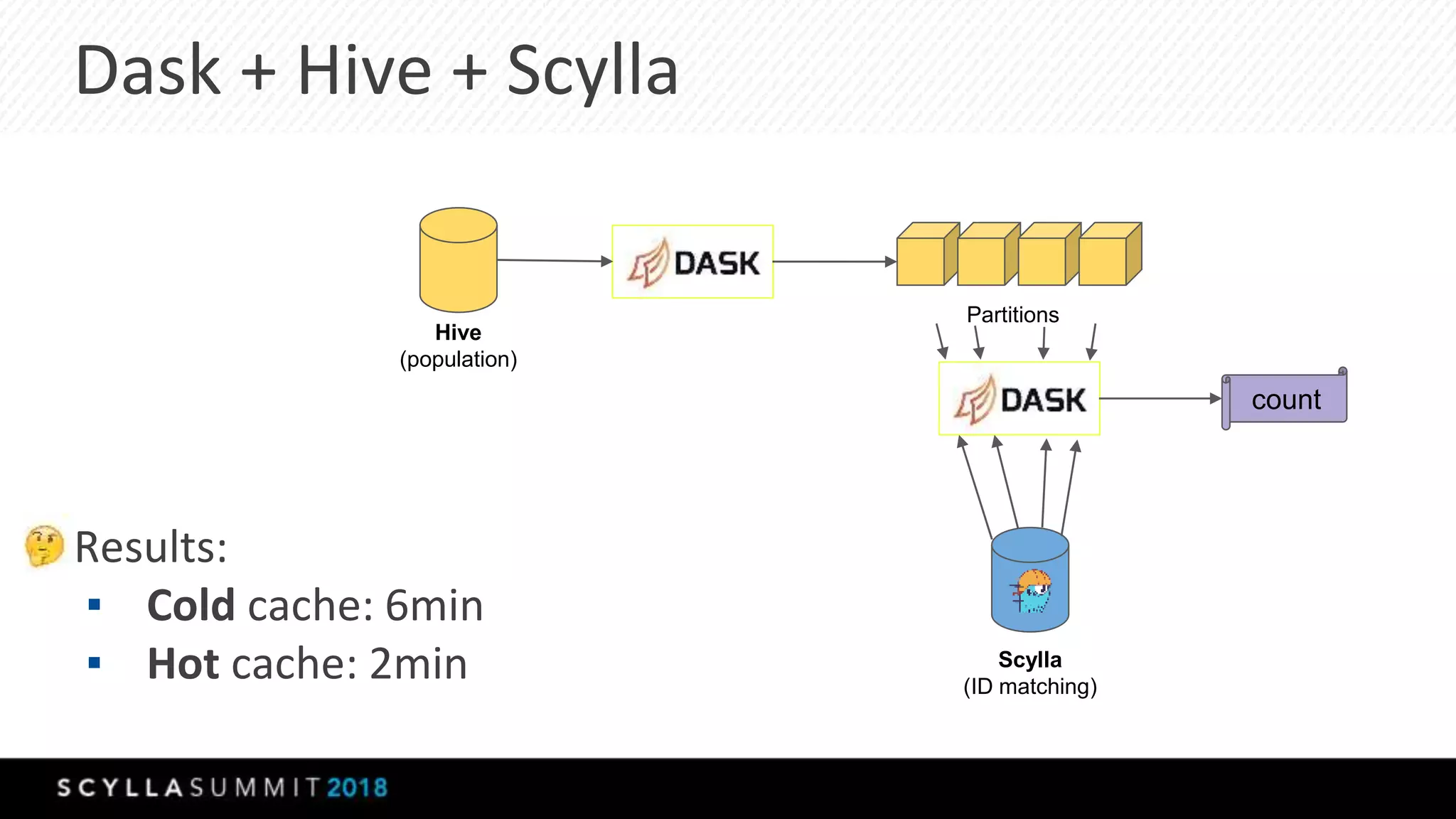
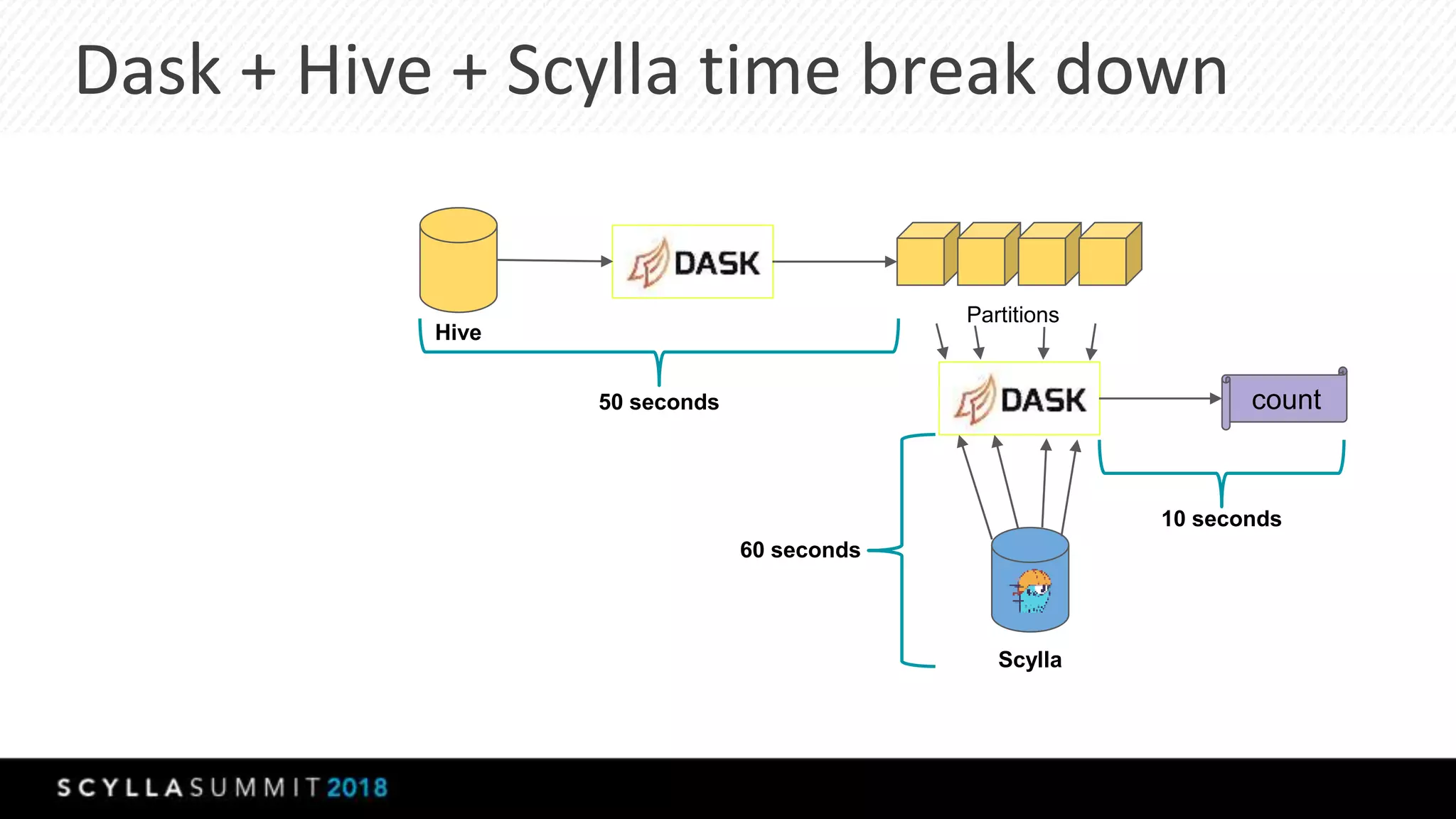
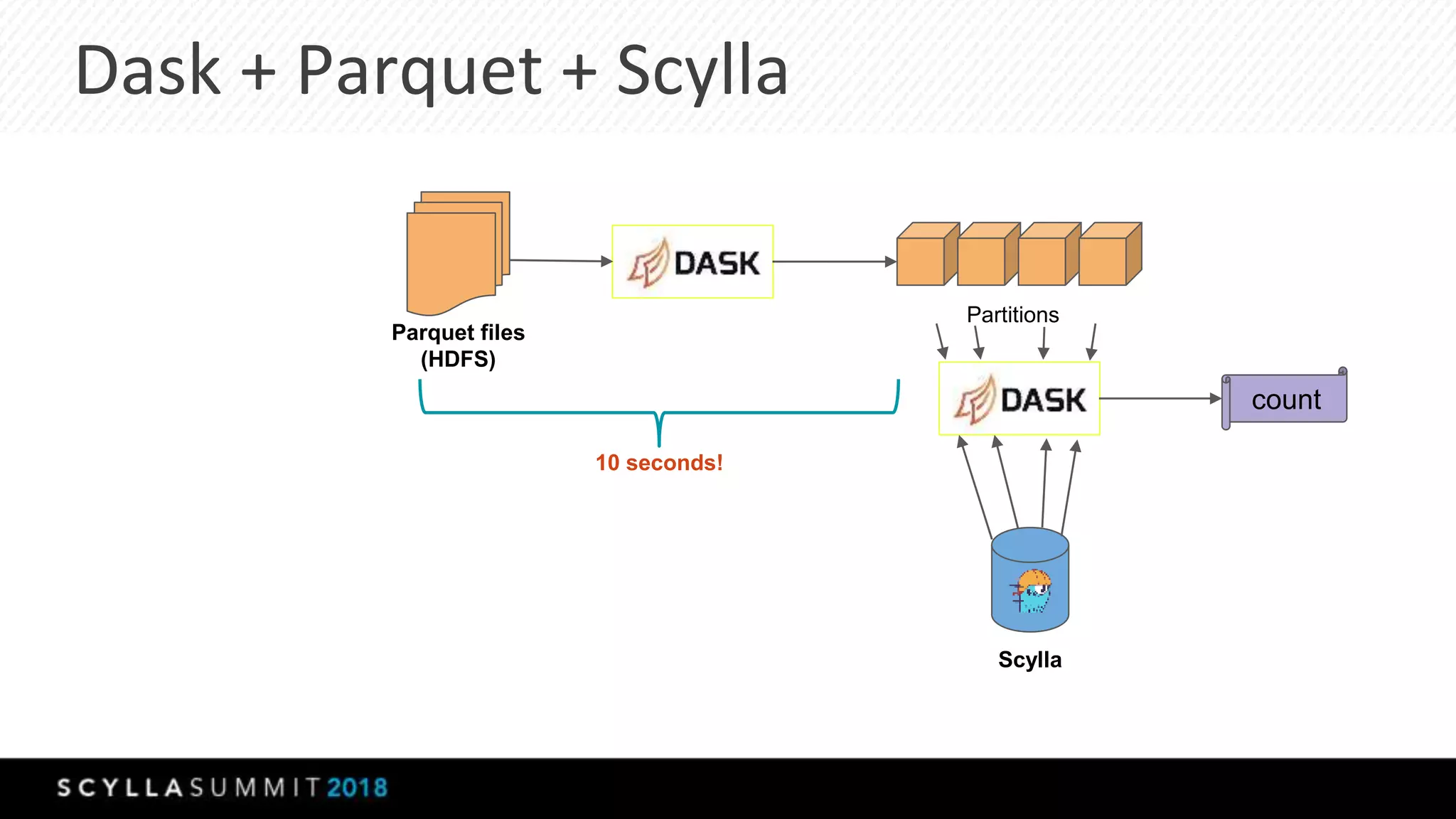

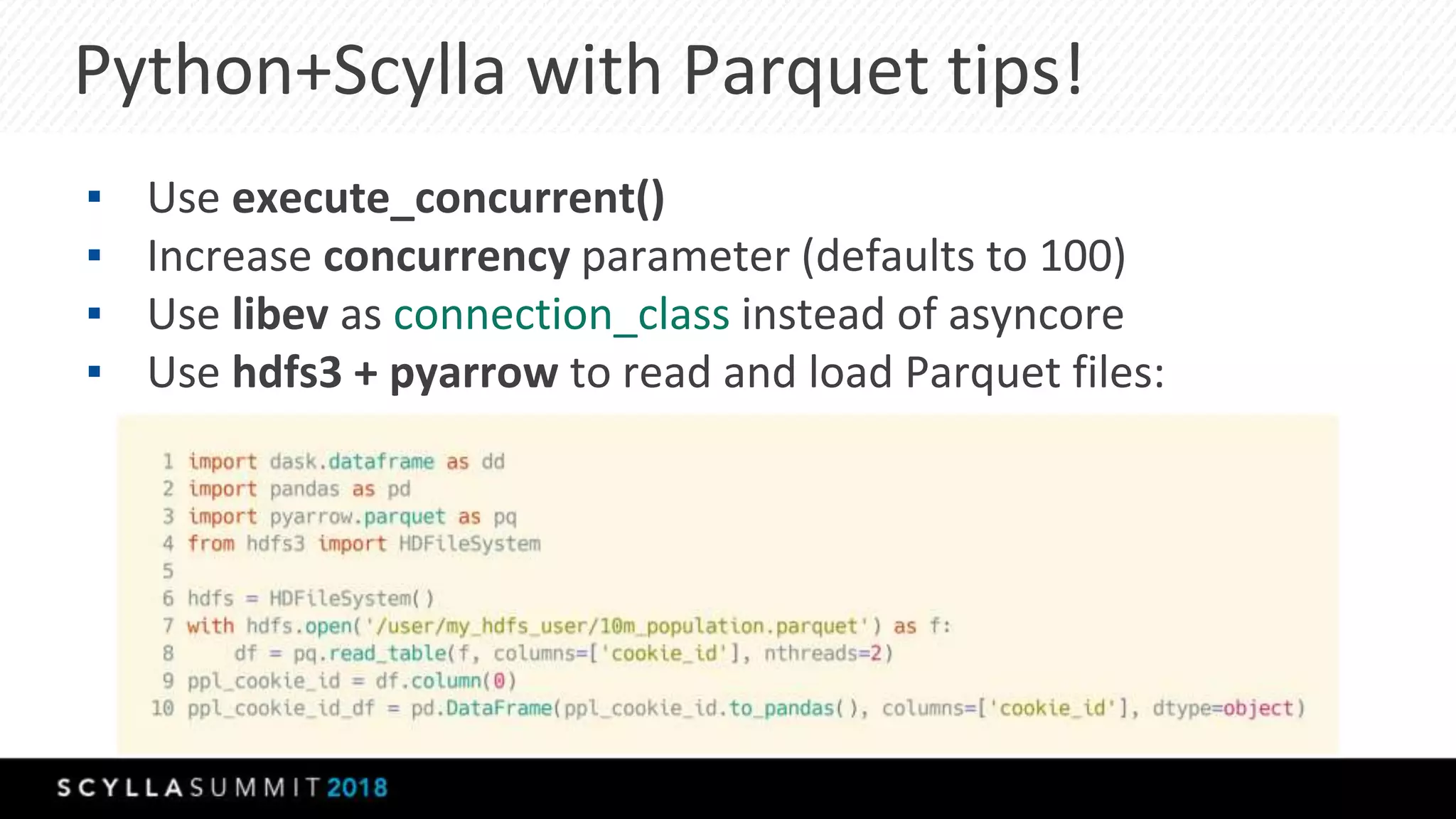




The document discusses the transition from MongoDB and Hive to Scylla for managing large datasets at Numberly, emphasizing improved performance in data joining and retrieval. It outlines the business context, implementation strategies, and performance metrics achieved with Scylla, including benchmarks for cold and hot cache scenarios. The document also addresses migration challenges and technical configurations for optimizing Spark and Scylla integration.






















































































