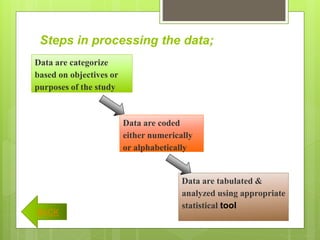
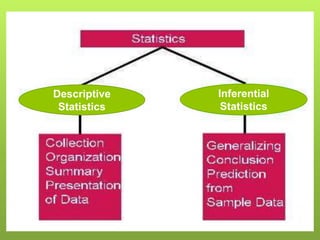
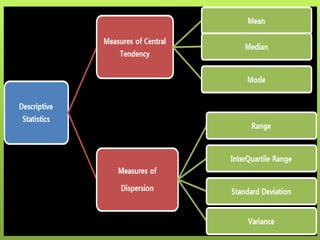
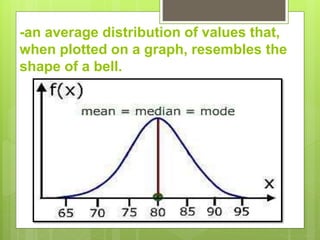
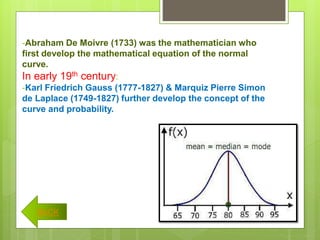
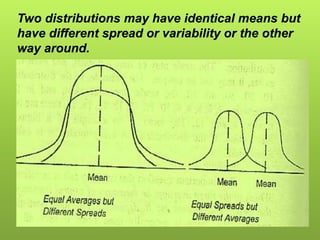
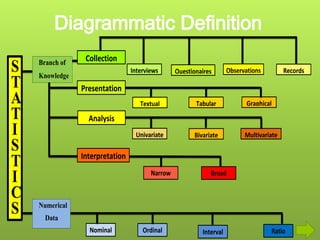
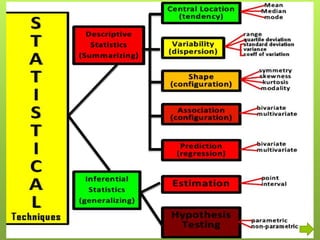
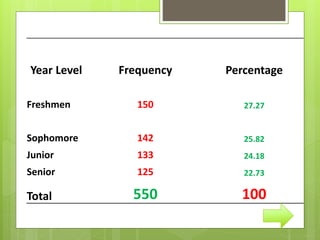
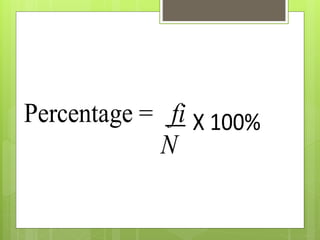After data is collected, it must be processed which includes verifying, organizing, transforming, and extracting the data for analysis. There are several steps to processing data including categorizing it based on the study objectives, coding it numerically or alphabetically, and tabulating and analyzing it using appropriate statistical tools. Statistics help remove researcher bias by interpreting data statistically rather than subjectively. Descriptive statistics are used to describe basic features of data like counts and percentages while inferential statistics are used to infer properties of a population from a sample.