Module-2 Instruction Set Cpus.pdf
•
0 likes•16 views

Module-2 Instruction Set Cpus.pdf

Recommended
More Related Content
Similar to Module-2 Instruction Set Cpus.pdf
Similar to Module-2 Instruction Set Cpus.pdf (20)
More from Sitamarhi Institute of Technology
More from Sitamarhi Institute of Technology (20)
Recently uploaded
Recently uploaded (20)
Module-2 Instruction Set Cpus.pdf
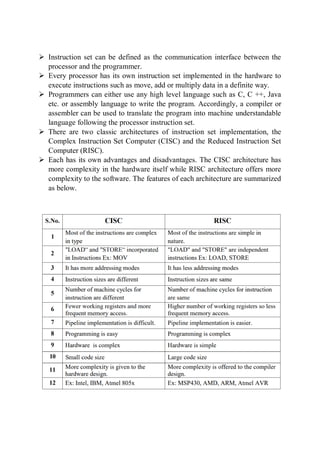
- 1. Instruction set can be defined as the communication interface between the processor and the programmer. Every processor has its own instruction set implemented in the hardware to execute instructions such as move, add or multiply data in a definite way. Programmers can either use any high level language such as C, C ++, Java etc. or assembly language to write the program. Accordingly, a compiler or assembler can be used to translate the program into machine understandable language following the processor instruction set. There are two classic architectures of instruction set implementation, the Complex Instruction Set Computer (CISC) and the Reduced Instruction Set Computer (RISC). Each has its own advantages and disadvantages. The CISC architecture has more complexity in the hardware itself while RISC architecture offers more complexity to the software. The features of each architecture are summarized as below.
- 2. ARM: Advanced RISC Machine (ARM) Processor is considered to be family of Central Processing Units that is used in music players, smartphones, wearables, tablets and other consumer electronic devices. The architecture of ARM processor is created by Advanced RISC Machines, hence name ARM. This needs very few instruction sets and transistors. It has very small size. This is reason that it is perfect fit for small size devices. It has less power consumption along with reduced complexity in its circuits. They can be applied to various designs such as 32-bit devices and embedded systems. They can even be upgraded according to user needs. The main features of ARM Processor are mentioned below : 1. Multiprocessing Systems – ARM processors are designed so that they can be used in cases of multiprocessing systems where more than one processors are used to process information. First AMP processor introduced by name of ARMv6K had ability to support 4 CPUs along with its hardware. 2. Tightly Coupled Memory – Memory of ARM processors is tightly coupled. This has very fast response time. It has low latency (quick response) that can also be used in cases of cache memory being unpredictable. 3. Memory Management – ARM processor has management section. This includes Memory Management Unit and Memory Protection Unit. These management systems become very important in managing memory efficiently. 4. Thumb-2 Technology – Thumb-2 Technology was introduced in 2003 and was used to create variable length instruction set. It extends 16-bit instructions of initial Thumb technology to 32-bit instructions. It has better performance than previously used Thumb technology. 5. One cycle execution time – ARM processor is optimized for each instruction on CPU. Each
- 3. instruction is of fixed length that allows time for fetching future instructions before executing present instruction. ARM has CPI (Clock Per Instruction) of one cycle. 6. Pipelining – Processing of instructions is done in parallel using pipelines. Instructions are broken down and decoded in one pipeline stage. The pipeline advances one step at a time to increase throughput (rate of processing). 7. Large number of registers – Large number of registers are used in ARM processor to prevent large amount of memory interactions. Registers contain data and addresses. These act as local memory store for all operations. Advantages of ARM Processor : 1. Affordable to create – ARM Processor is very affordable as it does not need expensive equipment’s for its creation. When compare to other processors, it is created at much lesser price. This is why they are apt for making of low cost Mobile phones and other electronic devices. 2. Low Power Consumption – AMP Processors have lesser power consumption. They were initially designed for performing at lesser power. They even have lesser transistors in their architecture. They have various other features that allow for this.
- 4. 3. Work Faster – ARM performs single operation at a time. This makes it work faster. It has lower latency that is quicker response time. 4. Multiprocessing feature – ARM processors are designed so that they can be used in cases of multiprocessing systems where more than one processors are used to process information. First AMP processor introduced by name of ARMv6K had ability to support 4 CPUs along with its hardware. 5. Better Battery Life – ARM Processors have better battery life. This is seen from administering devices that use ARM processors and those that do not. Those that used ARM processors worked for longer and got discharged later than those that did not work on ARM processors. 6. Load store architecture – The processor uses load store architecture that stores data in various registers (to reduce memory interactions). It has separate load and store instructions that are used to transfer data between external memory and register bank. 7. Simple Circuits – ARM processors have simple circuits, hence they are very compact and can be used in devices that are smaller in size (several devices are becoming smaller and more compact due to customer demands). Disadvantages of ARM Processor : 1. It is not compatible with X86 hence it cannot be used in Windows. 2. The speeds are limited in some processors which might create problems. 3. Scheduling instructions is difficult in case of ARM processors. 4. There must be proper execution of instructions by programmer. This is because entire performance of ARM processors depend upon their execution. 5. ARM Processor needs very highly skilled programmers. This is because of importance and complexity of execution (processor shows lesser performance when not executed properly.).
- 5. ARM Architecture: ARM cores are designed specifically for embedded systems. The needs of embedded systems can be satisfied only if features of RISC and CISC are considered together for processor design. So ARM architecture is not a pure RISC architecture. It has a blend of both RISC and CISC features. SHARC Processor The Analog Devices Super Harvard Architecture Single-Chip Computer (or “SHARC”) chip is a high performance DSP chip. Designed in 1994, the chips are capable of addressing an entire 32-bit word, and can implement 64- bit data processing. This makes it extremely well suited for audio processors, synthesizers, and A/D and D/A converters, because it has effectively unlimited headroom for audio. Since the 2000s, SHARC processors have become more and more common, often taking over for Motorola 56k DSP processors due to their more modern architecture. SHARC functions Program memory configurable as program and data memory parts (Princeton architecture) SHARC functions as VLIW (very large instruction word) processor. used in large number of DSP applications. Controlled power dissipation in floating point ALU. Different SHARCs can link by serial communication between them SHARC features ON chip memory 1 MB Program memory and data memory (Harvard architecture) External OFF chip memory OFF chip as well as ON-chip Memory can be configured for 32-bit or 48 bit words Integer operation features
- 6. Integer and saturation integer arithmetic both Saturation integer example─ integer after operation should limit to a maximum value ─ required in graphic processing Parallel Processing features Supports processing instruction level parallelism as well as memory access parallelism. Multiple data accesses in a single instruction Addressing Features SHARC 32-bit address space for accesses Accesses 16 GB or 20 GB or 24 GB as per the word size ( 32-bit, 40-bit or 48 bit) configured in the memory for each address. When word size = 32-bit then external memory configuration addressable space is 16 GB (232 × 4) bytes 2 Word size features Provides for two word sizes 32-bit and 48-bit. SHARC two full sets of 16 general-purpose registers, therfore fast context switching Allows multtasking OS and multithreading. Registers are called R0 to R15 or F0 o F15 depneding upon integer operation configuration or floating point configuration. Registers are of 32-bit. A few registers are special, of 48 bits that may also be accesses as pair of 16-bit and 32-bit registers. SHARC features Instruction word 48-bits 32-bit data word for integer and floating point operations and 40-bit extended floating point. Smaller 16 or 8 bit must also store as full 32-bit data. Therefore, the big endian or little endian data alignment is not considered during processing with carry also extended for rotating (RRX).
- 7. PROGRAMMING INPUT AND OUTPUT Then basic techniques for I/O programming can be understood relatively independent of the instruction set. In this section, we cover the basics of I/O programming and place them in the contexts of both the ARM and begin by discussing the basic characteristics of I/O devices so that we can understand the requirements they place on programs that communicate with them. INPUT AND OUTPUT DEVICES Input and output devices usually have some analog or non-electronic component— for instance, a disk drive has a rotating disk and analog read/write electronics. But the digital logic in the device that is most closely connected to the CPU very strongly resembles the logic you would expect in any computer system. Figure 2.1 shows the structure of a typical I/O device and its relationship to the CPU. The interface between the CPU and the device’s internals (e.g., the rotating disk and read/write electronics in a disk drive) is a set of registers. The CPU talks to the device by reading and writing the registers.
- 8. Devices typically have several registers, Data registers hold values that are treated as data by the device, such as the data read or written by a disk. Status registers provide information about the device’s operation, such as whether the current transaction has completed. Some registers may be read-only, such as a status register that indicates when the device is done, while others may be readable or writable. Application Example 2.1 describes a classic I/O device. CPU PERFORMANCE: Now that we have an understanding of the various types of instructions that CPUs can execute, we can move on to a topic particularly important in embedded computing: How fast can the CPU execute instructions? In this section, we consider three factors that can substantially influence program performance: pipelining and caching. 1. Pipelining Modern CPUs are designed as pipelined machines in which several instructions are executed in parallel. Pipelining greatly increases the efficiency of the CPU. But like any pipeline, a CPU pipeline works best when its contents flow smoothly. Some sequences of instructions can disrupt the flow of information in the pipeline and, temporarily at least, slow down the operation of the CPU. The ARM7 has a three-stage pipeline: Fetch the instruction is fetched from memory. Decode the instruction’s opcode and operands are decoded to determine what function to perform.
- 9. Execute the decoded instruction is executed. Each of these operations requires one clock cycle for typical instructions. Thus, a normal instruction requires three clock cycles to completely execute, known as the latency of instruction execution. But since the pipeline has three stages, an instruction is completed in every clock cycle. In other words, the pipeline has a throughput of one instruction per cycle. Figure 1.22 illustrates the position of instructions in the pipeline during execution using the notation introduced by Hennessy and Patterson [Hen06]. A vertical slice through the timeline shows all instructions in the pipeline at that time. By following an instruction horizontally, we can see the progress of its execution. The C55x includes a seven-stage pipeline [Tex00B]: Fetch. Decode. Address computes data and branch addresses. Access 1 reads data. Access 2 finishes data read. Read stage puts operands onto internal busses. Execute performs operations. RISC machines are designed to keep the pipeline busy. CISC machines may display a wide variation in instruction timing. Pipelined RISC machines typically have more regular timing characteristics most instructions that do not have pipeline hazards display the same latency.
- 10. 2. Caching We have already discussed caches functionally. Although caches are invisible in the programming model, they have a profound effect on performance. We introduce caches because they substantially reduce memory access time when the requested location is in the cache. However, the desired location is not always in the cache since it is considerably smaller than main memory. As a result, caches cause the time required to access memory to vary considerably. The extra time required to access a memory location not in the cache is often called the cache miss penalty. The amount of variation depends on several factors in the system architecture, but a cache miss is often several clock cycles slower than a cache hit. The time required to access a memory location depends on whether the requested location is in the cache. However, as we have seen, a location may not be in the cache for several reasons. At a compulsory miss, the location has not been referenced before.
- 11. At a conflict miss, two particular memory locations are fighting for the same cache line. At a capacity miss, the program’s working set is simply too large for the cache. The contents of the cache can change considerably over the course of execution of a program. When we have several programs running concurrently on the CPU, CPU PERFORMANCE: Now that we have an understanding of the various types of instructions that CPUs can execute, we can move on to a topic particularly important in embedded computing: How fast can the CPU execute instructions? In this section, we consider three factors that can substantially influence program performance: pipelining and caching. 1. Pipelining Modern CPUs are designed as pipelined machines in which several instructions are executed in parallel. Pipelining greatly increases the efficiency of the CPU. But like any pipeline, a CPU pipeline works best when its contents flow smoothly. Some sequences of instructions can disrupt the flow of information in the pipeline and, temporarily at least, slow down the operation of the CPU. The ARM7 has a three-stage pipeline: Fetch the instruction is fetched from memory.
- 12. Decode the instruction’s opcode and operands are decoded to determine what function to perform. Execute the decoded instruction is executed. Each of these operations requires one clock cycle for typical instructions. Thus, a normal instruction requires three clock cycles to completely execute, known as the latency of instruction execution. But since the pipeline has three stages, an instruction is completed in every clock cycle. In other words, the pipeline has a throughput of one instruction per cycle. Figure 1.22 illustrates the position of instructions in the pipeline during execution using the notation introduced by Hennessy and Patterson [Hen06]. A vertical slice through the timeline shows all instructions in the pipeline at that time. By following an instruction horizontally, we can see the progress of its execution. The C55x includes a seven-stage pipeline [Tex00B]: Fetch. Decode. Address computes data and branch addresses. Access 1 reads data. Access 2 finishes data read. Read stage puts operands onto internal busses. Execute performs operations. RISC machines are designed to keep the pipeline busy. CISC machines may display a wide variation in instruction timing. Pipelined RISC machines typically have more regular timing characteristics most instructions that do not have pipeline hazards display the same latency.
- 13. 2. Caching We have already discussed caches functionally. Although caches are invisible in the programming model, they have a profound effect on performance. We introduce caches because they substantially reduce memory access time when the requested location is in the cache. However, the desired location is not always in the cache since it is considerably smaller than main memory. As a result, caches cause the time required to access memory to vary considerably. The extra time required to access a memory location not in the cache is often called the cache miss penalty. The amount of variation depends on several factors in the system architecture, but a cache miss is often several clock cycles slower than a cache hit. The time required to access a memory location depends on whether the requested location is in the cache. However, as we have seen, a location may not be in the cache for several reasons. At a compulsory miss, the location has not been referenced before.
- 14. At a conflict miss, two particular memory locations are fighting for the same cache line. At a capacity miss, the program’s working set is simply too large for the cache. The contents of the cache can change considerably over the course of execution of a program. When we have several programs running concurrently on the CPU, CPU PERFORMANCE: Now that we have an understanding of the various types of instructions that CPUs can execute, we can move on to a topic particularly important in embedded computing: How fast can the CPU execute instructions? In this section, we consider three factors that can substantially influence program performance: pipelining and caching. 1. Pipelining Modern CPUs are designed as pipelined machines in which several instructions are executed in parallel. Pipelining greatly increases the efficiency of the CPU. But like any pipeline, a CPU pipeline works best when its contents flow smoothly. Some sequences of instructions can disrupt the flow of information in the pipeline and, temporarily at least, slow down the operation of the CPU. The ARM7 has a three-stage pipeline:
- 15. Fetch the instruction is fetched from memory. Decode the instruction’s opcode and operands are decoded to determine what function to perform. Execute the decoded instruction is executed. Each of these operations requires one clock cycle for typical instructions. Thus, a normal instruction requires three clock cycles to completely execute, known as the latency of instruction execution. But since the pipeline has three stages, an instruction is completed in every clock cycle. In other words, the pipeline has a throughput of one instruction per cycle. Figure 1.22 illustrates the position of instructions in the pipeline during execution using the notation introduced by Hennessy and Patterson [Hen06]. A vertical slice through the timeline shows all instructions in the pipeline at that time. By following an instruction horizontally, we can see the progress of its execution. The C55x includes a seven-stage pipeline [Tex00B]: Fetch. Decode. Address computes data and branch addresses. Access 1 reads data. Access 2 finishes data read. Read stage puts operands onto internal busses. Execute performs operations. RISC machines are designed to keep the pipeline busy. CISC machines may display a wide variation in instruction timing. Pipelined RISC machines typically have more regular timing characteristics most instructions that do not have pipeline hazards display the same latency.
- 16. 2. Caching We have already discussed caches functionally. Although caches are invisible in the programming model, they have a profound effect on performance. We introduce caches because they substantially reduce memory access time when the requested location is in the cache. However, the desired location is not always in the cache since it is considerably smaller than main memory. As a result, caches cause the time required to access memory to vary considerably. The extra time required to access a memory location not in the cache is often called the cache miss penalty. The amount of variation depends on several factors in the system architecture, but a cache miss is often several clock cycles slower than a cache hit. The time required to access a memory location depends on whether the requested location is in the cache. However, as we have seen, a location may not be in the cache for several reasons. At a compulsory miss, the location has not been referenced before. At a conflict miss, two particular memory locations are fighting for the same cache line.
- 17. At a capacity miss, the program’s working set is simply too large for the cache. The contents of the cache can change considerably over the course of execution of a program. When we have several programs running concurrently on the CPU, CPU POWER CONSUMPTION: Power consumption is, in some situations, as important as execution time. In this section we study the characteristics of CPUs that influence power consumption and mechanisms provided by CPUs to control how much power they consume. First, it is important to distinguish between energy and power. Power is, of course, energy consumption per unit time. Heat generation depends on power consumption. Battery life, on the other hand, most directly depends on energy consumption. Generally, we will use the term power as shorthand for energy and power consumption, distinguishing between them only when necessary. The high-level power consumption characteristics of CPUs and other system components are derived from the circuits used to build those components. Today, virtually all digital systems are built with complementary metal oxide semiconductor (CMOS) circuitry. The detailed circuit characteristics are best left to a study of VLSI design [Wol08], but the basic sources of CMOS power consumption are easily identified and briefly described below. ■ Voltage drops: The dynamic power consumption of a CMOS circuit is proportional to the square of the power supply voltage (V2 ). Therefore, by reducing the power supply voltage to the lowest level that provides the required performance, we can significantly reduce power consumption. We also may be able to add parallel hardware and even further reduce the power supply voltage while maintaining required performance.
- 18. ■ Toggling: A CMOS circuit uses most of its power when it is changing its output value. This provides two ways to reduce power consumption. By reducing the speed at which the circuit operates, we can reduce its power consumption (although not the total energy required for the operation, since the result is available later).We can actually reduce energy consumption by eliminating unnecessary changes to the inputs of a CMOS circuit—eliminating unnecessary glitches at the circuit outputs eliminates unnecessary power consumption.