Downloaded 163 times





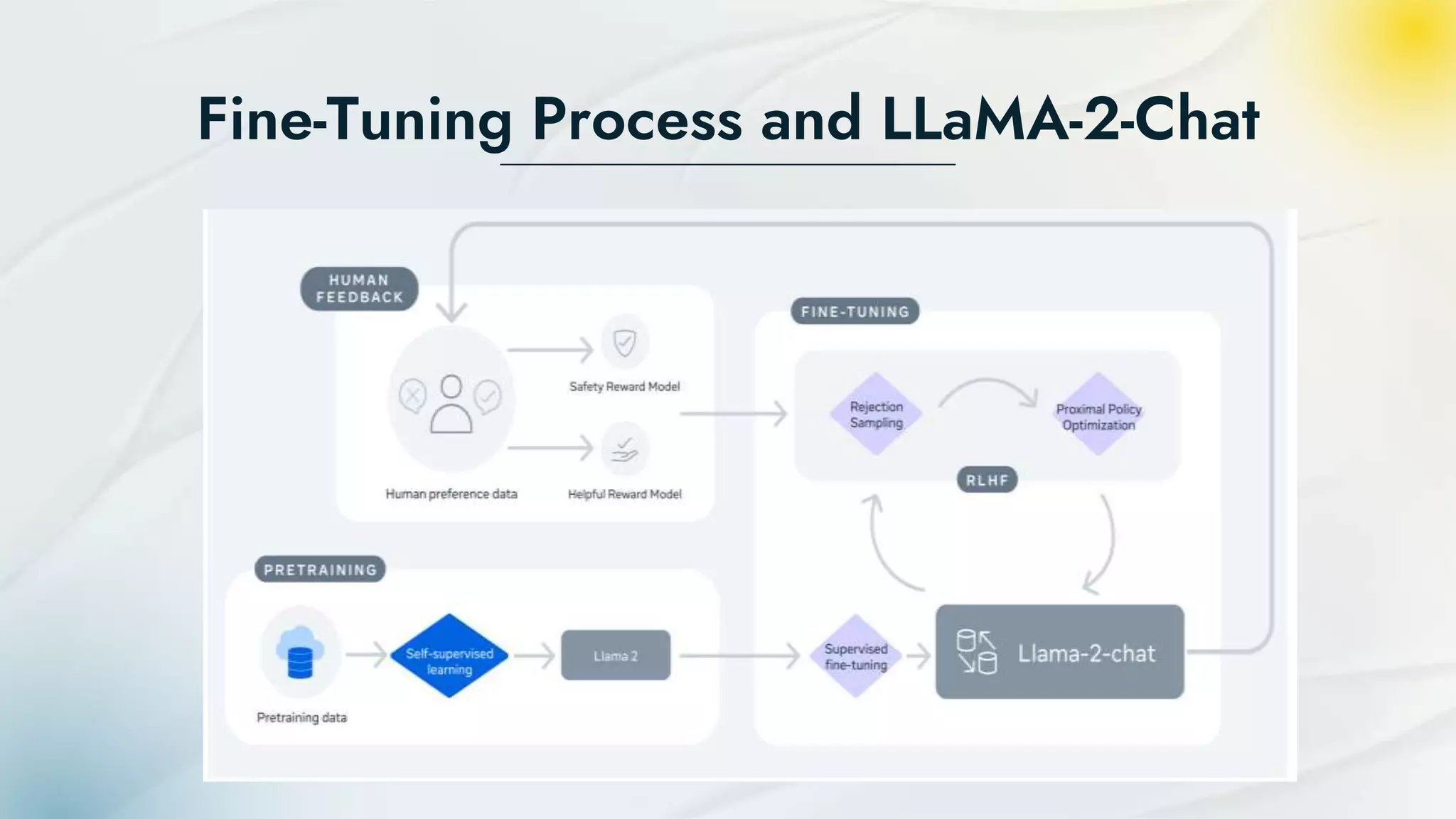
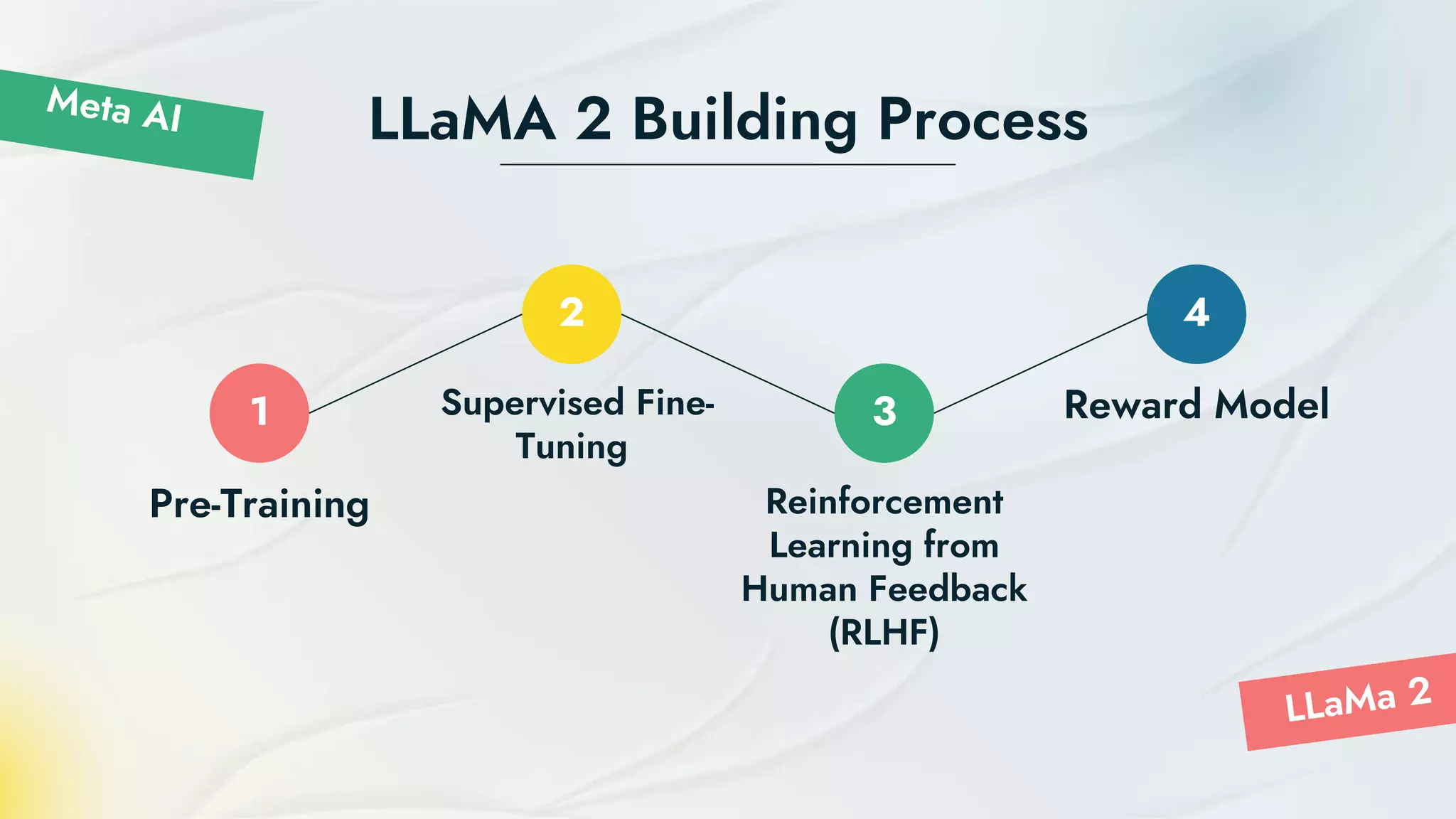









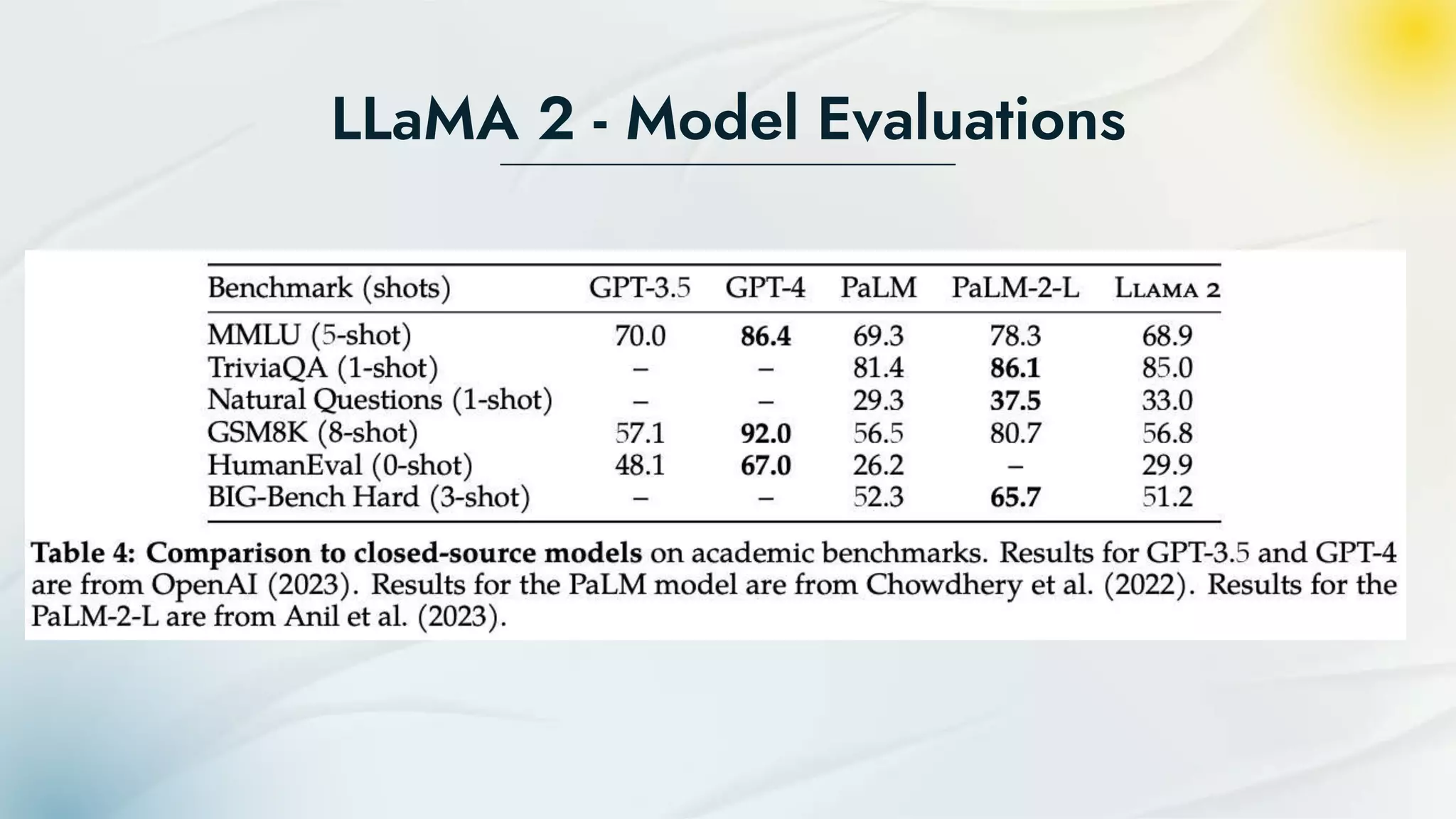



- LLaMA 2 is a family of large language models developed by Meta in partnership with Microsoft and others. It has been pretrained on 2 trillion tokens and has three model sizes up to 70 billion parameters. - LLaMA 2 was trained using an auto-regressive transformer and reinforcement learning from human feedback to improve safety and alignment. It can generate text, translate languages, and answer questions. - The models were pretrained on Meta's research supercomputers then fine-tuned for dialog using supervised learning and reinforcement learning from human feedback to further optimize safety and usefulness.























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











