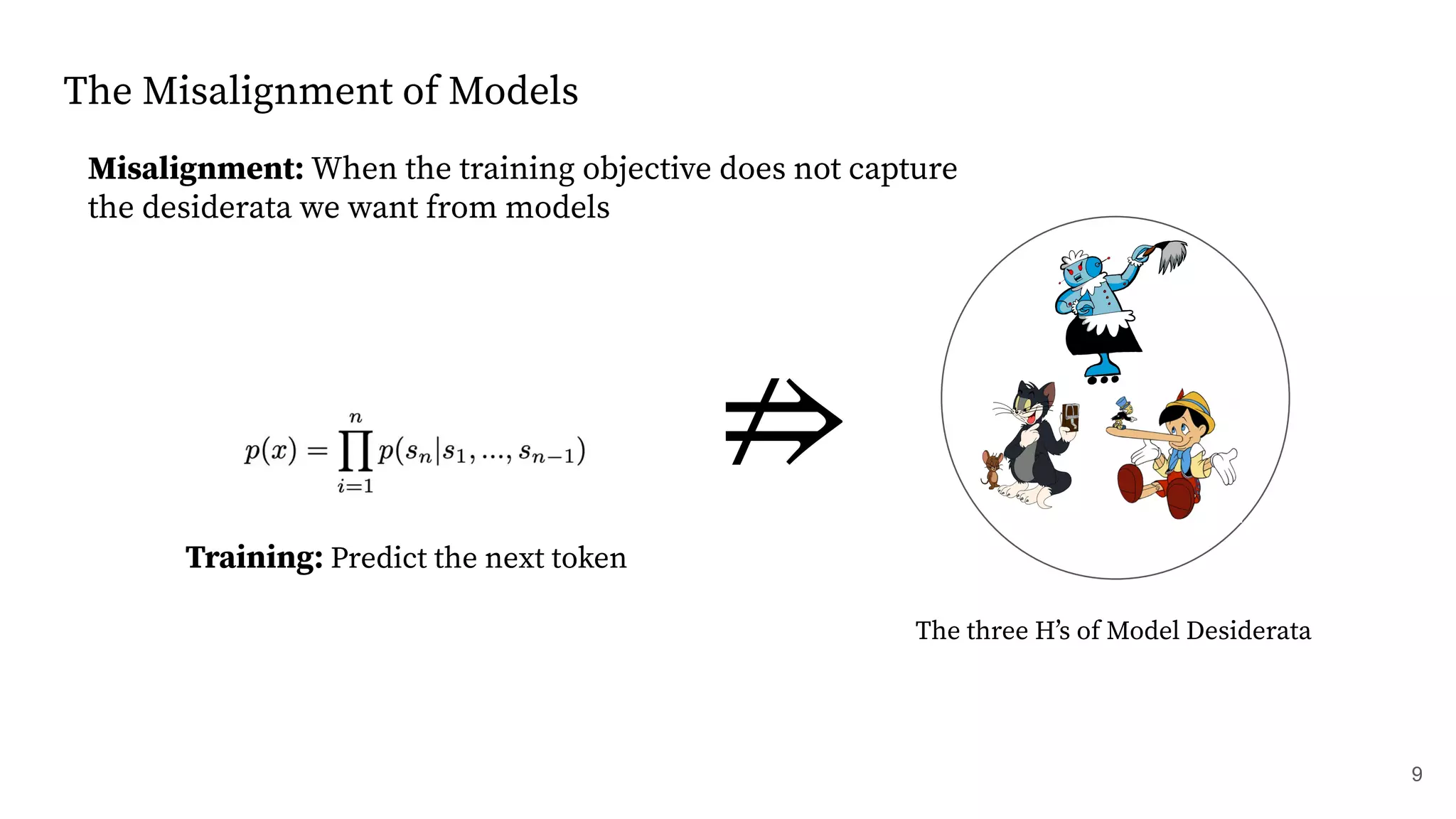
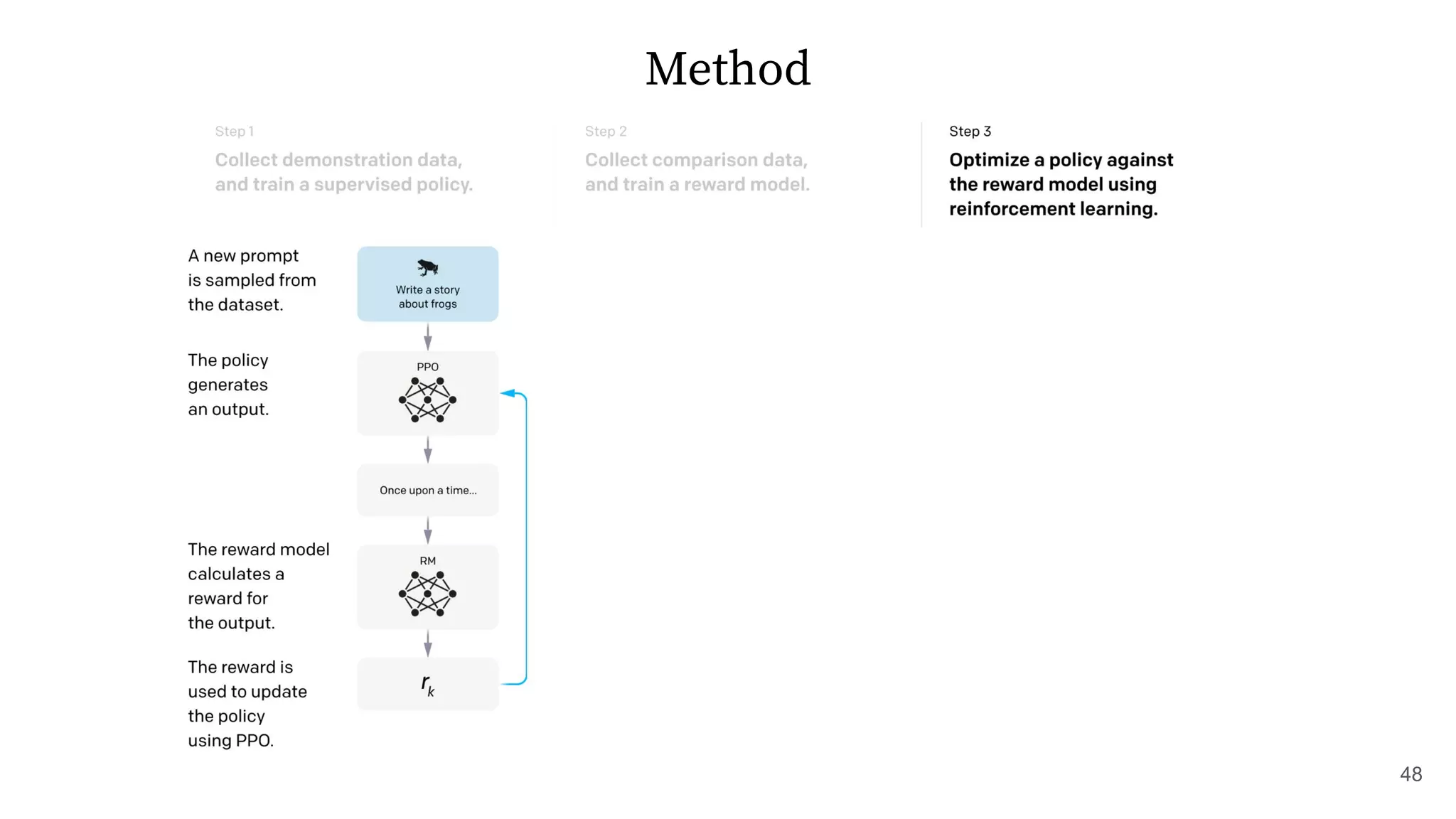
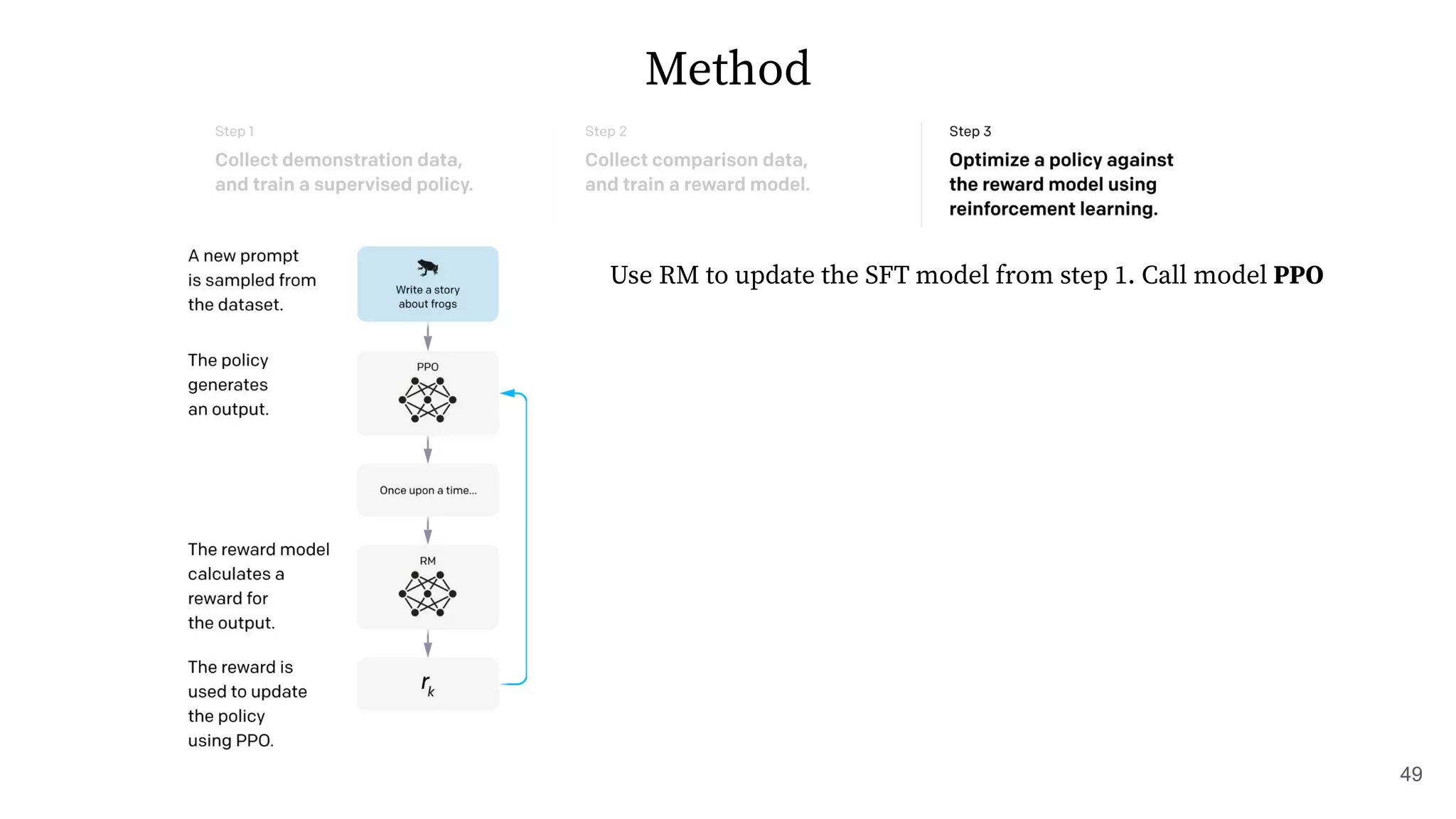
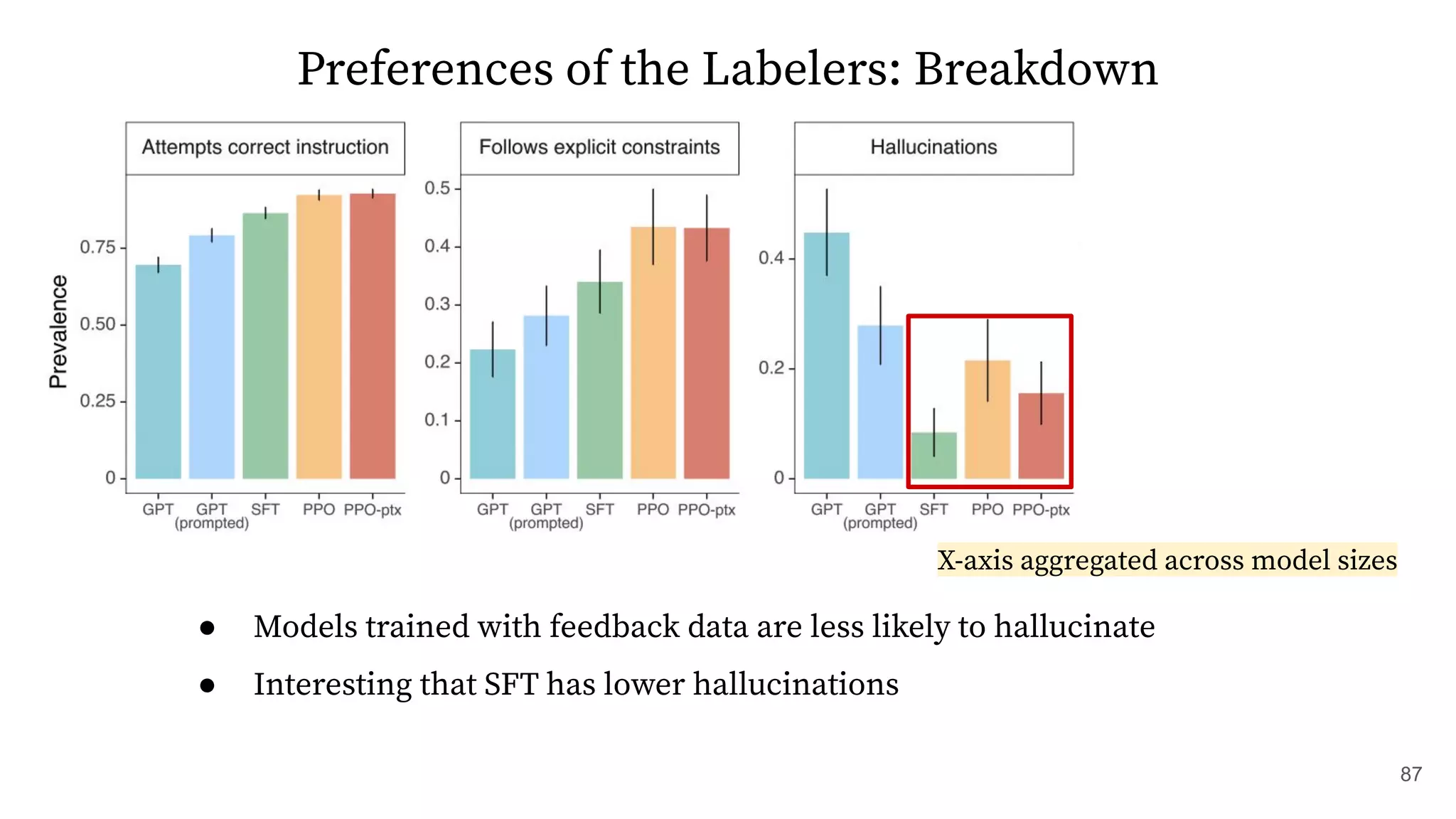
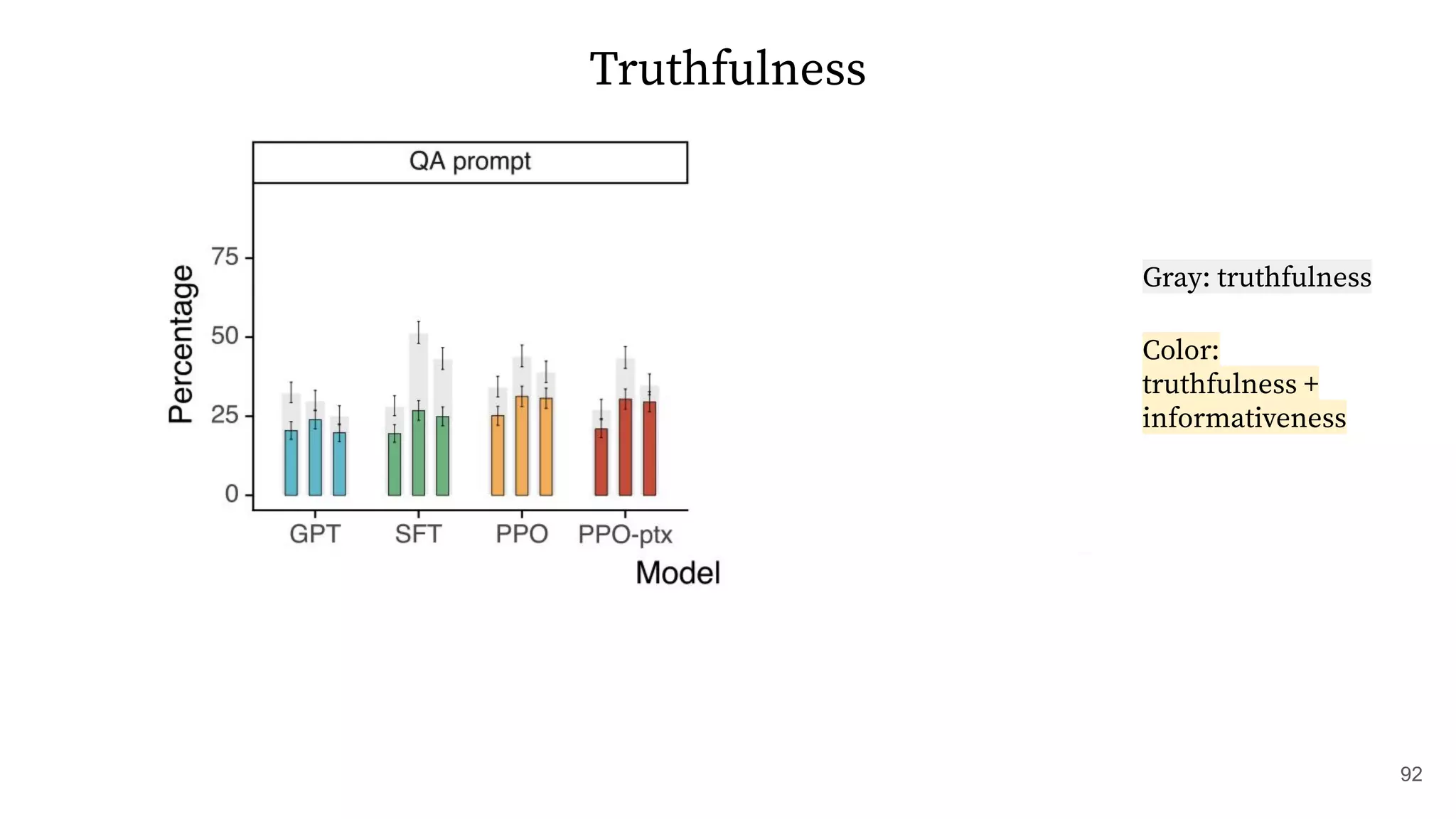
The document discusses methods for training language models to follow instructions with human feedback. It proposes a method called SFT that uses human annotators to provide feedback on model responses to prompts. An initial model is fine-tuned on this demonstration data to create an SFT Model. The SFT Model responses are then ranked by users. A reward model is trained on the rankings to provide rewards. The reward model is then used to update the SFT Model via policy gradients, creating a PPO Model. A KL penalty is added to prevent the PPO Model from deviating too much from the SFT Model.
















































































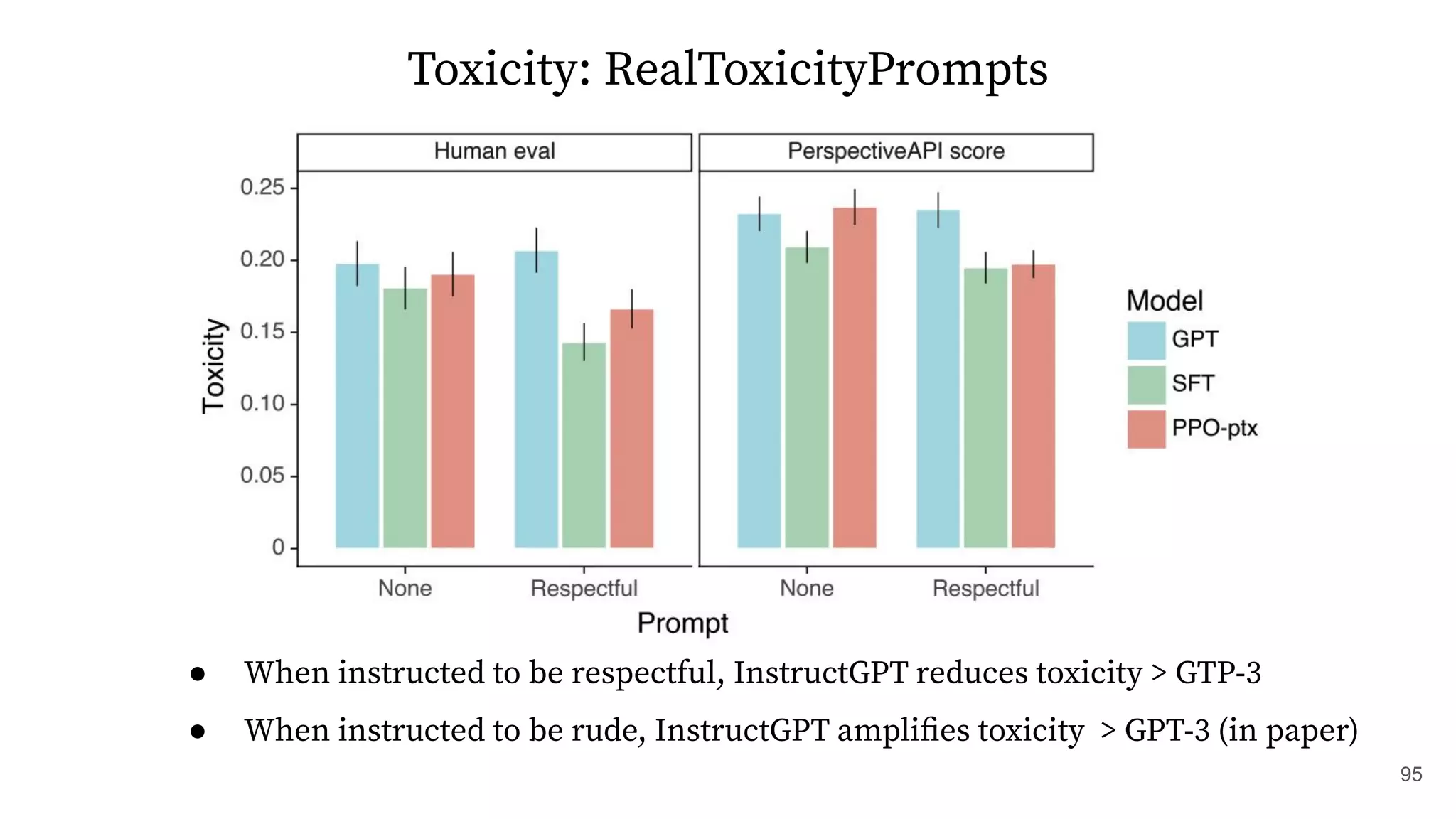
![Toxicity: RealToxicityPrompts
96
(Quark: Controllable Text Generation with Reinforced [Un]learning, Lu et al., 2022)
PPO-style training, not the exact InstructGPT model](https://image.slidesharecdn.com/rlhf-230614023605-ba55bd80/75/rlhf-pdf-92-2048.jpg)























































































