Downloaded 17 times



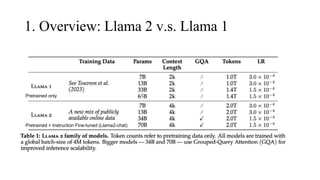
![Architecture
Llama 2 adopt most of the pretraining setting and model
architecture from Llama 1:
1) Pre-normalization with RMSNorm [GPT3]
SwiGLU activation function [PaLM]
Rotary Embeddings [GPTNeo]
Refer to my Llama 1 presentation for more details: Llama 1 @
YanAITalk Youtube channel
2. Approach
SwiGLU
Activation
Pos Embedding
The primary architectural differences from Llama 1
include increased context length and grouped-query
attention (GQA)](https://image.slidesharecdn.com/llama2-240517165624-f1827573/85/Llama-2-Open-Foundation-and-Fine-tuned-Chat-Models-4-320.jpg)
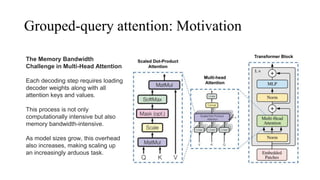
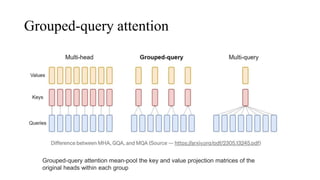
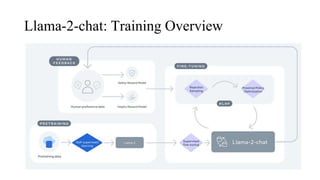
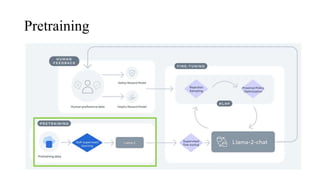
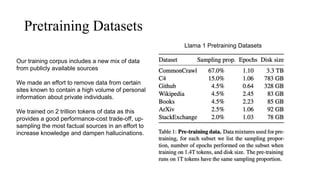
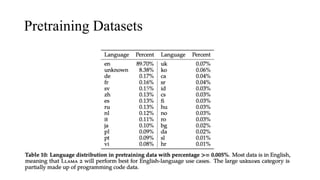
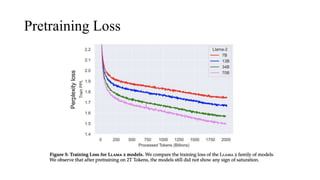
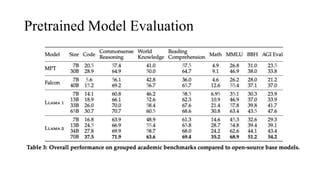
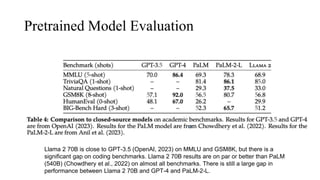
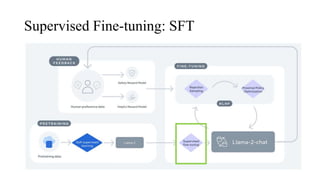

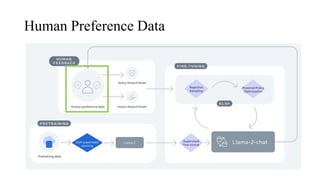

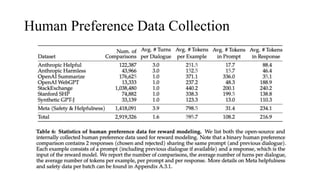


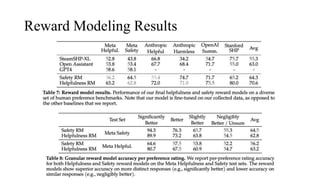

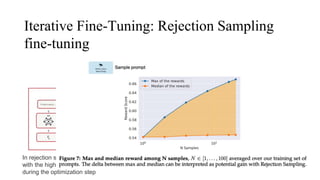
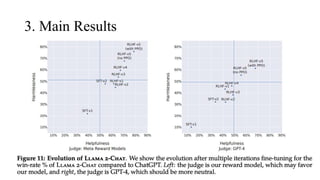
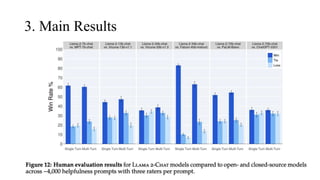
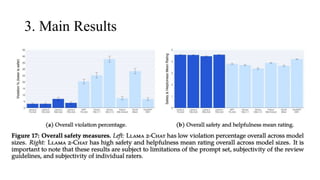



The document discusses the development and features of Llama 2, an advanced language model compared to its predecessor Llama 1, emphasizing architectural improvements like grouped-query attention and enhanced context length. It details the extensive pretraining on a diverse dataset aimed at improving knowledge and reducing hallucinations, along with a focus on user preference data to fine-tune the model for helpfulness and safety. Despite its competitiveness with other open-source models, it acknowledges performance gaps relative to proprietary models such as GPT-4.











![[DSC Europe 23] Dmitry Ustalov - Design and Evaluation of Large Language Models](https://cdn.slidesharecdn.com/ss_thumbnails/dmitryustalov-designandevaluationofllms-231128235048-b0b24f5d-thumbnail.jpg?width=640&height=640&fit=bounds)



































