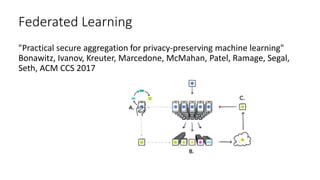
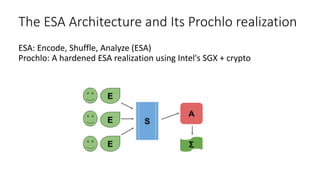
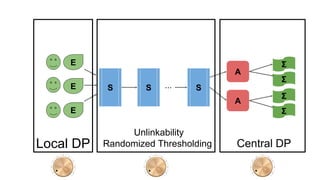
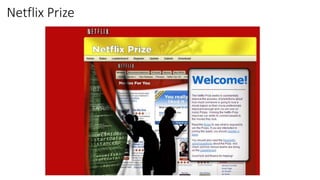
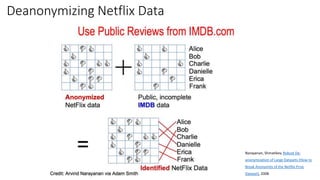
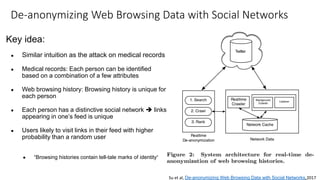
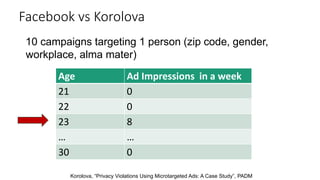
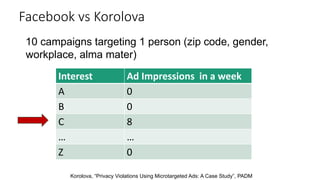
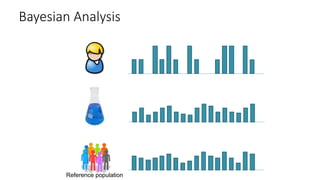
The document provides an overview of privacy-preserving data mining techniques in industry, focusing on challenges, lessons learned, and practical applications such as differential privacy. It discusses real-world privacy breaches and highlights Google's RAPPOR and Apple's on-device differential privacy as key case studies in maintaining user privacy. Key takeaways include the importance of understanding privacy techniques, the evolution of privacy breaches, and the development of methods that balance data utility with user privacy.
























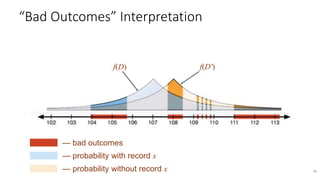
![33
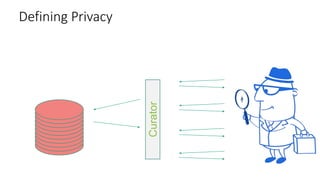
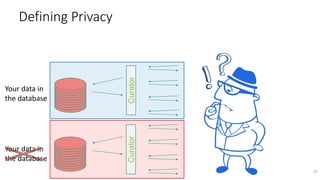
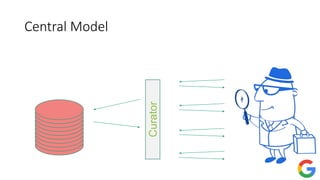
CuratorCurator
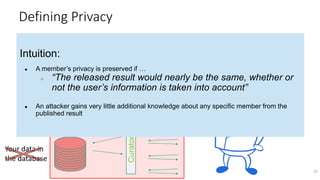
Databases D and D′ are neighbors if they differ in one person’s data.
Differential Privacy [DMNS06]: The distribution of the curator’s output M(D)
on database D is (nearly) the same as M(D′).
Differential Privacy
Your data in
the database
Your data in
the database](https://image.slidesharecdn.com/kdd2018privacytutorial-kenthapadimironovthakurta-180831222334/85/Privacy-preserving-Data-Mining-in-Industry-Practical-Challenges-and-Lessons-Learned-33-320.jpg)
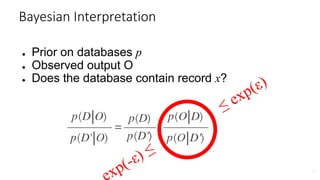
![ε-Differential Privacy: The distribution of the curator’s output M(D) on
database D is (nearly) the same as M(D′).
34
CuratorCurator
Parameter ε quantifies
information leakage
∀S: Pr[M(D)∊S] ≤ exp(ε) ∙ Pr[M(D′)∊S].
Differential Privacy
Your data in
the database
Your data in
the database
Dwork, McSherry, Nissim, Smith [TCC 2006]](https://image.slidesharecdn.com/kdd2018privacytutorial-kenthapadimironovthakurta-180831222334/85/Privacy-preserving-Data-Mining-in-Industry-Practical-Challenges-and-Lessons-Learned-34-320.jpg)
![(ε, δ)-Differential Privacy: The distribution of the curator’s output M(D) on
database D is (nearly) the same as M(D′).
35
Parameter ε quantifies
information leakage
Parameter δ allows for
a small probability of
failure
∀S: Pr[M(D)∊S] ≤ exp(ε) ∙ Pr[M(D′)∊S]+δ.
CuratorCurator
Dwork, McSherry, Nissim, Smith [TCC 2006]; Dwork, Kenthapadi, McSherry, Mironov, Naor [ EUROCRYPT 2006]
Your data in
the database
Your data in
the database
Differential Privacy](https://image.slidesharecdn.com/kdd2018privacytutorial-kenthapadimironovthakurta-180831222334/85/Privacy-preserving-Data-Mining-in-Industry-Practical-Challenges-and-Lessons-Learned-35-320.jpg)












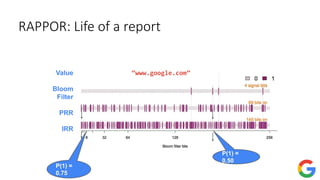




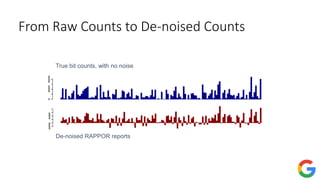
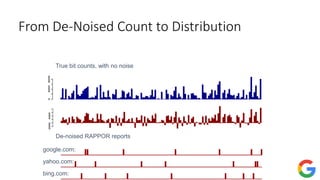
















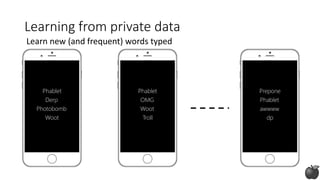
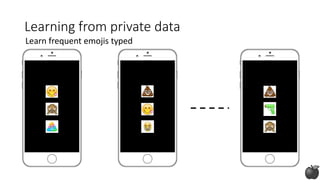



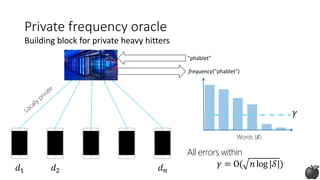

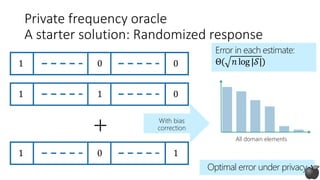
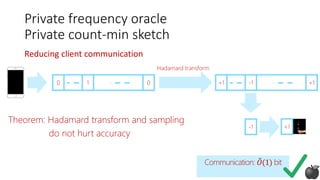
![Private frequency oracle:
Design constraints
Computational and communication constraints:
Client side:
size of the domain (|S|) and n
# characters > 3,000
For 8-character words:
size of the domain |S|=3,000^8
number of clients ~ 1B
Efficiently [BS15] ~ n
Our goal ~ O(log |S|)](https://image.slidesharecdn.com/kdd2018privacytutorial-kenthapadimironovthakurta-180831222334/85/Privacy-preserving-Data-Mining-in-Industry-Practical-Challenges-and-Lessons-Learned-90-320.jpg)

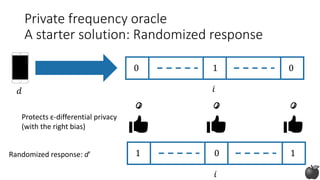

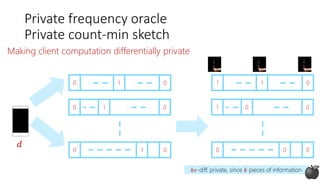
![𝑑
0 01
0 01
0 01
Hash function: ℎ1
Hash function: ℎ2
Hash function: ℎ 𝑘
Number of hash bins: 𝑛
Computation= 𝑂(log|𝒮|)
𝑘 ≈ log|𝒮|
Private frequency oracle
Non-private count-min sketch [CM05]](https://image.slidesharecdn.com/kdd2018privacytutorial-kenthapadimironovthakurta-180831222334/85/Privacy-preserving-Data-Mining-in-Industry-Practical-Challenges-and-Lessons-Learned-95-320.jpg)
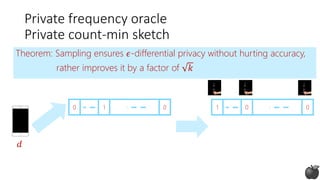
![0 01
0 01
0 01
0 01
1 00
0 11
1
𝑘
1
+
245
127
9123
2132
𝑛
Reducing server computation
Private frequency oracle
Non-private count-min sketch [CM05]](https://image.slidesharecdn.com/kdd2018privacytutorial-kenthapadimironovthakurta-180831222334/85/Privacy-preserving-Data-Mining-in-Industry-Practical-Challenges-and-Lessons-Learned-96-320.jpg)
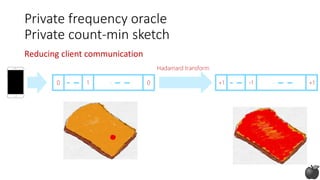
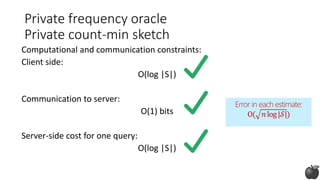
![Reducing server computation
1
𝑘
1
Phablet
245
127
9123
2132
𝑛
9146
2212
Frequency estimate:
min (9146, 2212, 2132)
Error in each estimate:
O( 𝑛log|𝒮|)
Server side query cost:
𝑂(log|𝒮|)
𝑘 ≈ log |𝒮|
Private frequency oracle
Non-private count-min sketch [CM05]
"phablet"](https://image.slidesharecdn.com/kdd2018privacytutorial-kenthapadimironovthakurta-180831222334/85/Privacy-preserving-Data-Mining-in-Industry-Practical-Challenges-and-Lessons-Learned-97-320.jpg)

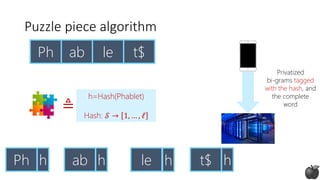
![Puzzle piece algorithm
(works well in practice, no theoretical guarantees)
[Bassily Nissim Stemmer Thakurta, 2017 and Apple differential privacy team, 2017]](https://image.slidesharecdn.com/kdd2018privacytutorial-kenthapadimironovthakurta-180831222334/85/Privacy-preserving-Data-Mining-in-Industry-Practical-Challenges-and-Lessons-Learned-105-320.jpg)
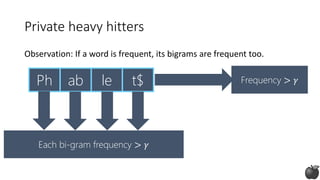





![Tree histogram algorithm
(works well in practice + optimal theoretical guarantees)
[Bassily Nissim Stemmer Thakurta, 2017]](https://image.slidesharecdn.com/kdd2018privacytutorial-kenthapadimironovthakurta-180831222334/85/Privacy-preserving-Data-Mining-in-Industry-Practical-Challenges-and-Lessons-Learned-113-320.jpg)
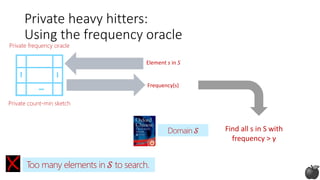
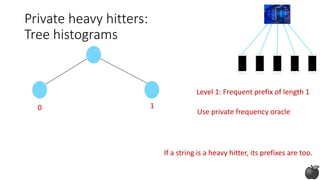
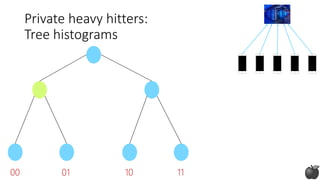
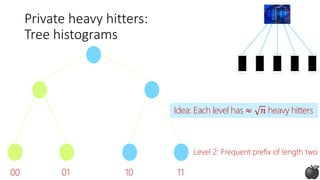
![Private heavy hitters:
Tree histograms (based on [CM05])
1 0 0
Any string in 𝒮:
log |𝒮| bits
Idea: Construct prefixes of the heavy hitter bit by bit](https://image.slidesharecdn.com/kdd2018privacytutorial-kenthapadimironovthakurta-180831222334/85/Privacy-preserving-Data-Mining-in-Industry-Practical-Challenges-and-Lessons-Learned-114-320.jpg)











![Differential Privacy? [Dwork et al, 2006]
• Rich privacy literature (Adam-Worthmann, Samarati-Sweeney, Agrawal-Srikant, …,
Kenthapadi et al, Machanavajjhala et al, Li et al, Dwork et al)
• Limitation of anonymization techniques (as discussed in the first part)
• Worst case sensitivity of quantiles to any one user’s compensation data is
large
• Large noise to be added, depriving reliability/usefulness
• Need compensation insights on a continual basis
• Theoretical work on applying differential privacy under continual observations
• No practical implementations / applications
• Local differential privacy / Randomized response based approaches (Google’s RAPPOR; Apple’s
iOS differential privacy; Microsoft’s telemetry collection) not applicable](https://image.slidesharecdn.com/kdd2018privacytutorial-kenthapadimironovthakurta-180831222334/85/Privacy-preserving-Data-Mining-in-Industry-Practical-Challenges-and-Lessons-Learned-132-320.jpg)
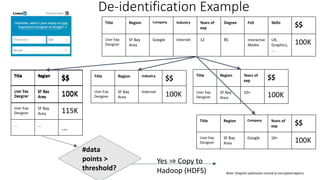
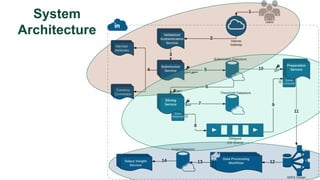
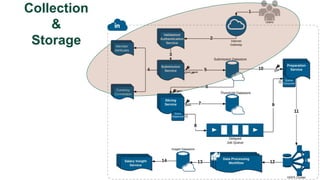
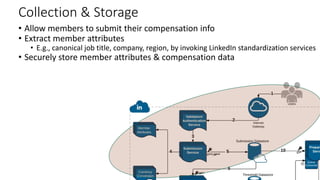
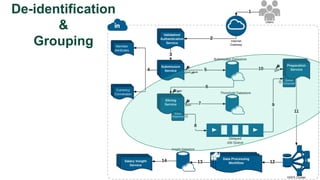
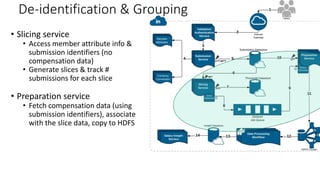
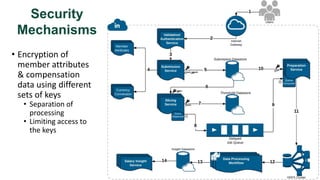
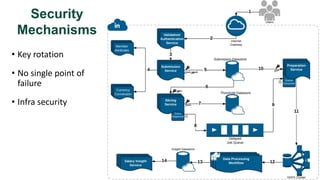
![De-identification & Grouping
• Approach inspired by k-Anonymity [Samarati-Sweeney]
• “Cohort” or “Slice”
• Defined by a combination of attributes
• E.g, “User experience designers in SF Bay Area”
• Contains aggregated compensation entries from corresponding individuals
• No user name, id or any attributes other than those that define the cohort
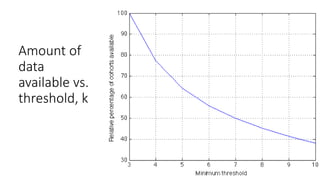
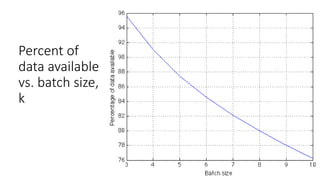
• A cohort available for offline processing only if it has at least k entries
• Apply LinkedIn standardization software (free-form attribute canonical version)
before grouping
• Analogous to the generalization step in k-Anonymity](https://image.slidesharecdn.com/kdd2018privacytutorial-kenthapadimironovthakurta-180831222334/85/Privacy-preserving-Data-Mining-in-Industry-Practical-Challenges-and-Lessons-Learned-138-320.jpg)
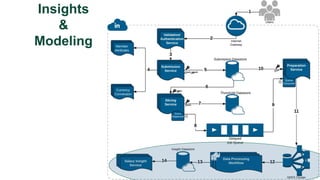
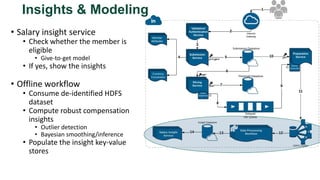
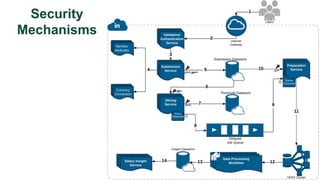


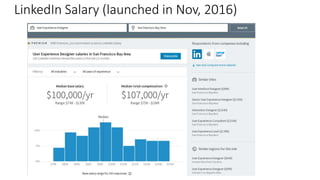
![Key takeaway points
• LinkedIn Salary: a new internet application, with
unique privacy/modeling challenges
• Privacy vs. Modeling Tradeoffs
• Potential directions
• Privacy-preserving machine learning models in a practical setting
[e.g., Chaudhuri et al, JMLR 2011; Papernot et al, ICLR 2017]
• Provably private submission of compensation entries?](https://image.slidesharecdn.com/kdd2018privacytutorial-kenthapadimironovthakurta-180831222334/85/Privacy-preserving-Data-Mining-in-Industry-Practical-Challenges-and-Lessons-Learned-150-320.jpg)


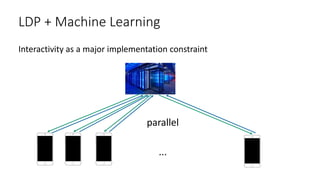
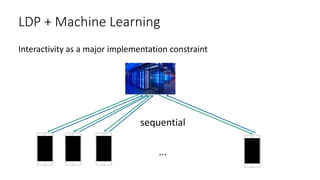
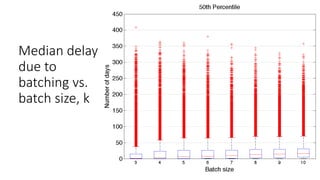
!["Is interaction necessary for distributed private
learning?" [STU 2017]
• Single parameter learning (e.g., median):
• Maximal accuracy with full parallelism
• Multi-parameter learning:
• Polylog number of iterations
• Lower bounds](https://image.slidesharecdn.com/kdd2018privacytutorial-kenthapadimironovthakurta-180831222334/85/Privacy-preserving-Data-Mining-in-Industry-Practical-Challenges-and-Lessons-Learned-155-320.jpg)