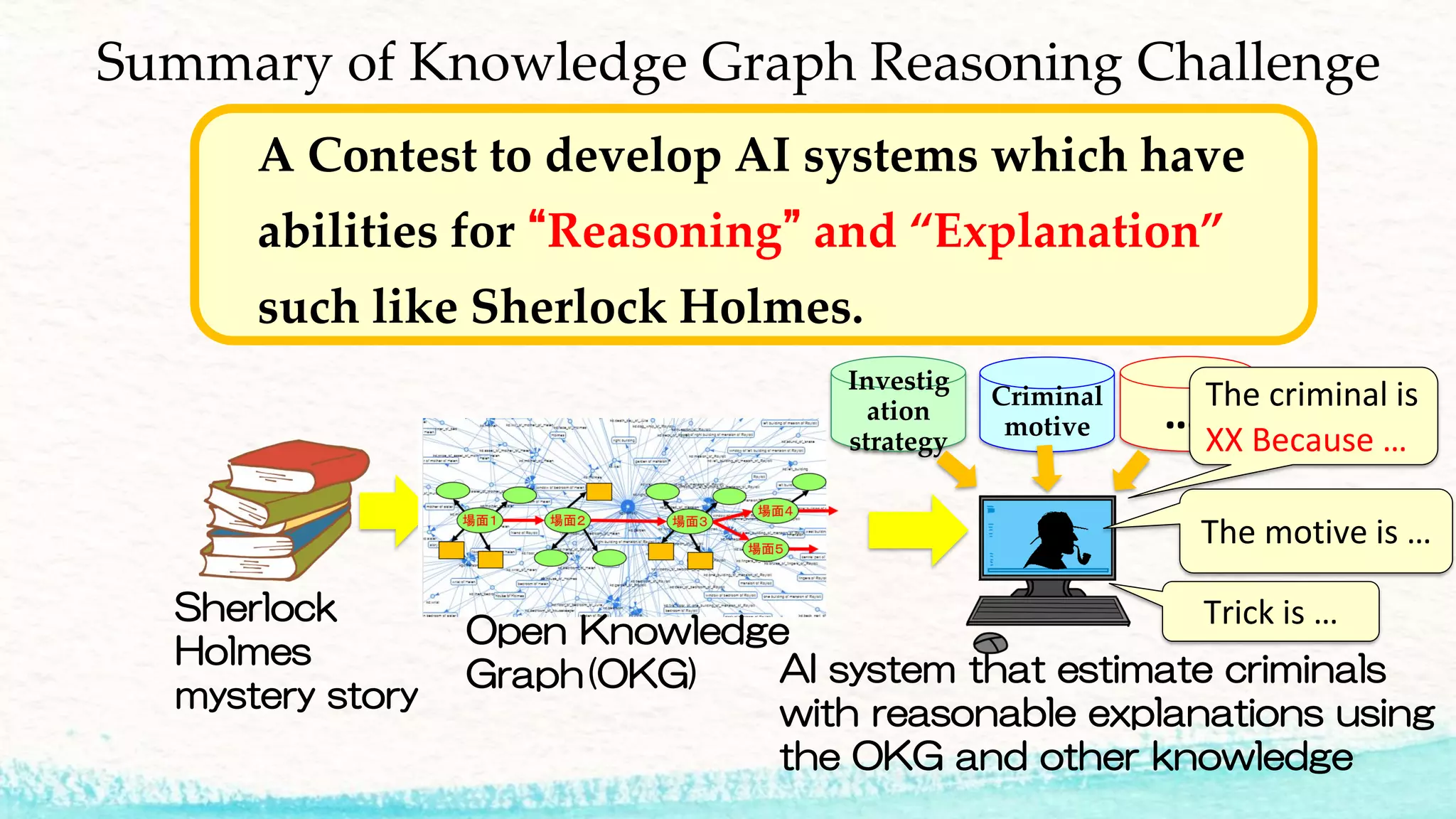
The 2018 Knowledge Graph Reasoning Challenge aimed to develop AI systems capable of reasoning and explanation, utilizing techniques exemplified by Sherlock Holmes. Key sessions included knowledge graph construction, evaluation of estimation methods, and subjective assessments from both experts and the public regarding explainability and performance. The document outlines the evaluation process, prize winners, and future challenges that build on this foundational work in explainable AI.















































































![[part 2]ナレッジグラフ推論チャレンジ・Tech Live!](https://cdn.slidesharecdn.com/ss_thumbnails/kgrctechlive-201023091455-thumbnail.jpg?width=640&height=640&fit=bounds)










![[part 1]ナレッジグラフ推論チャレンジ・Tech Live!](https://cdn.slidesharecdn.com/ss_thumbnails/kgrctechliive2020-1021-201023101135-thumbnail.jpg?width=640&height=640&fit=bounds)



















