Download to read offline















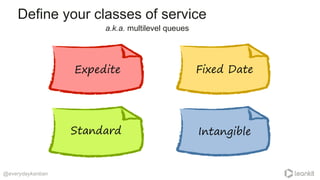

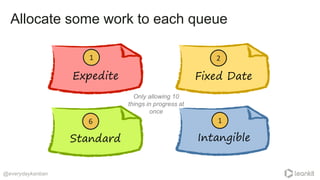




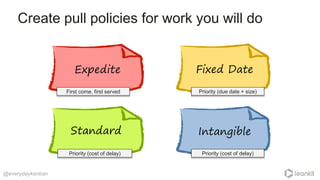




The document discusses strategies for effective work scheduling in order to minimize chaos and enhance productivity, highlighting the importance of flow over mere busyness. Key considerations include defining classes of service, monitoring job starvation, and making policies that prioritize meaningful work while allowing for flexibility in handling various types of tasks. It emphasizes the need for clear goals and explicit policies that optimize work processes, along with resources for further learning on these topics.























































































