Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Jiro Nishitoba
PPTX, PDF
1,296 views
深層学習による自然言語処理勉強会3章前半
株式会社レトリバで行われた「深層学習による自然言語処理」勉強会で用いた資料です。
Technology
◦
Read more
2
Save
Share
Embed
Embed presentation
Download
Downloaded 15 times
1
/ 21
2
/ 21
3
/ 21
4
/ 21
5
/ 21
6
/ 21
7
/ 21
8
/ 21
9
/ 21
10
/ 21
11
/ 21
12
/ 21
13
/ 21
14
/ 21
15
/ 21
16
/ 21
17
/ 21
18
/ 21
19
/ 21
20
/ 21
21
/ 21
More Related Content
PDF
BERTに関して
by
Saitama Uni
PDF
第64回情報科学談話会(岡﨑 直観 准教授)
by
gsis gsis
PDF
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」(一部文字が欠けてます)
by
Hitomi Yanaka
PPTX
AI and Machine Learning Demystified by Carol Smith at Midwest UX 2017
by
Carol Smith
PPTX
深層学習による自然言語処理勉強会2章前半
by
Kei Shiratsuchi
PPTX
深層学習による自然言語処理勉強会2章前半
by
Jiro Nishitoba
PDF
「深層学習による自然言語処理」読書会 4.2記憶ネットワーク@レトリバ
by
scapegoat06
PPTX
nlpaper.challenge2 nlp1
by
Kense Todo
BERTに関して
by
Saitama Uni
第64回情報科学談話会(岡﨑 直観 准教授)
by
gsis gsis
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」(一部文字が欠けてます)
by
Hitomi Yanaka
AI and Machine Learning Demystified by Carol Smith at Midwest UX 2017
by
Carol Smith
深層学習による自然言語処理勉強会2章前半
by
Kei Shiratsuchi
深層学習による自然言語処理勉強会2章前半
by
Jiro Nishitoba
「深層学習による自然言語処理」読書会 4.2記憶ネットワーク@レトリバ
by
scapegoat06
nlpaper.challenge2 nlp1
by
Kense Todo
Similar to 深層学習による自然言語処理勉強会3章前半
PDF
[最新版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」
by
Yuki Arase
PPTX
深層学習による自然言語処理の研究動向
by
STAIR Lab, Chiba Institute of Technology
PDF
ニューラルネットワークを用いた自然言語処理
by
Sho Takase
PDF
Ism npblm-20120315
by
隆浩 安
PDF
Infer.NETを使ってLDAを実装してみた
by
正志 坪坂
PDF
東京大学2021年度深層学習(Deep learning基礎講座2021) 第8回「深層学習と自然言語処理」
by
Hitomi Yanaka
PPTX
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」
by
Hitomi Yanaka
PDF
TensorFlow math ja 05 word2vec
by
Shin Asakawa
PPTX
有名論文から学ぶディープラーニング 2016.03.25
by
Minoru Chikamune
PDF
[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」
by
Yuki Arase
PDF
言語と知識の深層学習@認知科学会サマースクール
by
Yuya Unno
PDF
Extract and edit
by
禎晃 山崎
PDF
100816 nlpml sec2
by
shirakia
PDF
Deep Learningの基礎と応用
by
Seiya Tokui
PDF
STAIR Lab Seminar 202105
by
Sho Takase
PPTX
最近の自然言語処理
by
naoto moriyama
DOCX
レポート深層学習Day3
by
ssuser9d95b3
PDF
Data-Intensive Text Processing with MapReduce ch6.1
by
Sho Shimauchi
PPTX
数式がわからなくたってDeep Learningやってみたい!人集合- dots. DeepLearning部 発足!
by
Hideto Masuoka
PPTX
ラビットチャレンジレポート 深層学習Day3
by
ssuserf4860b
[最新版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」
by
Yuki Arase
深層学習による自然言語処理の研究動向
by
STAIR Lab, Chiba Institute of Technology
ニューラルネットワークを用いた自然言語処理
by
Sho Takase
Ism npblm-20120315
by
隆浩 安
Infer.NETを使ってLDAを実装してみた
by
正志 坪坂
東京大学2021年度深層学習(Deep learning基礎講座2021) 第8回「深層学習と自然言語処理」
by
Hitomi Yanaka
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」
by
Hitomi Yanaka
TensorFlow math ja 05 word2vec
by
Shin Asakawa
有名論文から学ぶディープラーニング 2016.03.25
by
Minoru Chikamune
[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」
by
Yuki Arase
言語と知識の深層学習@認知科学会サマースクール
by
Yuya Unno
Extract and edit
by
禎晃 山崎
100816 nlpml sec2
by
shirakia
Deep Learningの基礎と応用
by
Seiya Tokui
STAIR Lab Seminar 202105
by
Sho Takase
最近の自然言語処理
by
naoto moriyama
レポート深層学習Day3
by
ssuser9d95b3
Data-Intensive Text Processing with MapReduce ch6.1
by
Sho Shimauchi
数式がわからなくたってDeep Learningやってみたい!人集合- dots. DeepLearning部 発足!
by
Hideto Masuoka
ラビットチャレンジレポート 深層学習Day3
by
ssuserf4860b
More from Jiro Nishitoba
PPTX
Icml読み会 deep speech2
by
Jiro Nishitoba
PPTX
Emnlp読み会資料
by
Jiro Nishitoba
PPTX
全体セミナー20170629
by
Jiro Nishitoba
PPTX
全体セミナーWfst
by
Jiro Nishitoba
PPTX
Retrieva seminar jelinek_20180822
by
Jiro Nishitoba
PPTX
全体セミナー20180124 final
by
Jiro Nishitoba
PPTX
ChainerでDeep Learningを試す為に必要なこと
by
Jiro Nishitoba
PPTX
20180609 chainer meetup_es_pnet
by
Jiro Nishitoba
PPTX
20190509 gnn public
by
Jiro Nishitoba
PDF
Chainer meetup20151014
by
Jiro Nishitoba
PPTX
Hessian free
by
Jiro Nishitoba
Icml読み会 deep speech2
by
Jiro Nishitoba
Emnlp読み会資料
by
Jiro Nishitoba
全体セミナー20170629
by
Jiro Nishitoba
全体セミナーWfst
by
Jiro Nishitoba
Retrieva seminar jelinek_20180822
by
Jiro Nishitoba
全体セミナー20180124 final
by
Jiro Nishitoba
ChainerでDeep Learningを試す為に必要なこと
by
Jiro Nishitoba
20180609 chainer meetup_es_pnet
by
Jiro Nishitoba
20190509 gnn public
by
Jiro Nishitoba
Chainer meetup20151014
by
Jiro Nishitoba
Hessian free
by
Jiro Nishitoba
Recently uploaded
PDF
20260119_VIoTLT_vol22_kitazaki_v1___.pdf
by
Ayachika Kitazaki
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
PDF
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
PDF
アジャイル導入が止まる3つの壁 ─ 文化・他部門・組織プロセスをどう乗り越えるか
by
Graat(グラーツ)
20260119_VIoTLT_vol22_kitazaki_v1___.pdf
by
Ayachika Kitazaki
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
アジャイル導入が止まる3つの壁 ─ 文化・他部門・組織プロセスをどう乗り越えるか
by
Graat(グラーツ)
深層学習による自然言語処理勉強会3章前半
1.
深層学習による自然言語処理 勉強会第2回後半 株式会社レトリバ 取締役 リサーチャー 西鳥羽
二郎
2.
今回の範囲 • 第3章 言語処理における深層 学習の基礎 •
3.1 準備: 記号の世界とベクト ルの世界の橋渡し • 3.2 言語モデル • 3.2.1 概要 • 3.2.2 確率モデルの定義 • 3.2.3 順伝搬型ニューラル言語モ デル(FFNN言語モデル) • 3.2.4 再帰ニューラル言語モデル (RNNLM) • 3.2.5 言語モデルの評価 • 3.2.6 言語モデルからの文生成 • 3.2.7 文字単位の言語モデル • 3.3 分散表現 • 3.3.1 概要 • 3.3.2 歴史的背景 • 3.3.3 獲得方法 • 3.3.4 利用方法 • 3.3.5 今後の発展
3.
3 言語処理における深層学習の基礎 3.1 準備:
記号の世界とベクトルの世界の橋渡し • 記号変換が必要 • 自然言語処理におけるデータは離散的な「記号」 • ニューラルネットで扱えるのは連続値の「ベクトル」 • 変換方法 • One-hot ベクトル(記号からベクトルへ) • Softmax関数(ベクトルから記号へ)
4.
3.2 言語モデル 3.2.1 概要 •
(確率的)言語モデル • 自然言語による文が生成される確率をモデル化したものであり、文や 文書の自然言語らしさを求めるのに使われる • BOS, EOSを追加した単語列を全てベクトル化して算出する • 言語モデルの例 • N-gram • 出現頻度の数え上げで求められるので計算コストが低い • ニューラル言語モデル • N-gramと比較して計算コストが非常に高い • N-gramよりも性能が優れている
5.
3.2.2 確率モデルの定義: 条件付き分布への分解 •
文の生成確率を直接モデル化するのは難しい • そのために仮定を置く • 単語の出現確率はそれ以前に出現した単語により決まる • 文の生成確率はBOSから始まりEOSで終わる単語列が先頭から順に生 成される確率を掛け合わせて算出する • 単語の出現確率は直前数N個に出現した単語により決まる ← N-gram
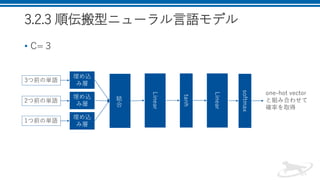
6.
3.2.3 順伝搬型ニューラル言語モデル • C=3 結 合 3つ前の単語 2つ前の単語 1つ前の単語 埋め込 み層 埋め込 み層 埋め込 み層 Linear tanh Linear softmax one-hot
vector と組み合わせて 確率を取得
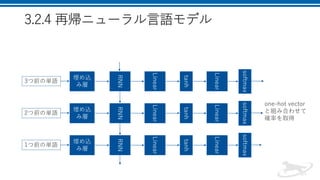
7.
3.2.4 再帰ニューラル言語モデル RNN 3つ前の単語 埋め込 み層 Linear tanh Linear softmax one-hot vector と組み合わせて 確率を取得RNN 2つ前の単語 埋め込 み層 Linear tanh Linear softmax RNN 1つ前の単語 埋め込 み層
Linear tanh Linear softmax
8.
3.2.5 言語モデルの評価 • 言語モデルはパープレキシティ(perplexity,
PPL)で行う • 次の単語を予測する確率分布にどれだけのばらつきがあるかを表す • 非負の値 • 全体的に確率が0に近づけば大きな正の値になる • 確率が1に近づけば0に近づく • 良い言語モデルはデータと一致する単語だけ高い確率をもったばらつきの小 さい分布になるはずなので0に近づく • 有名データセット • Penn Treebank • One Billion Word • Hutter
9.
3.2.6 言語モデルからの文生成 • 言語モデルは単語の生成確率なのでそれをもとにサンプリング を行うと「それっぽい」文ができる •
注意点 • 言語モデルはあくまで「文が自然言語っぽいか」をモデル化したもの なので文生成のためのものではない • 言語モデルはそれ以前に出現していた単語を全部知っている必要があ るが文生成では自ら生成した単語を次の単語のサンプリングのために 用いて代用している
10.
3.2.7 文字単位での言語モデル • 日本語のように単語の区切りが難しい場合は文字単位で扱うの は魅力的 •
単語の区切りを気にしなくて済む • 未知の単語に対応できる • でも難しい • (単語や句などの)長い依存関係を学習する必要がある • 系列長が長くなるので中間層の計算が大変になる
11.
3.3 分散表現 • 分散表現 •
記号を計算機上で扱うための方法論 • ニューラルネット的には部品という位置づけ • 自然言語処理的にはそれ単体でも研究されている
12.
3.3.1 概要 • 離散オブジェクト •
人や物の名前、概念のように物理的に計測できる量を伴わず、通常記号を用 いて離散的に表現するもの • 分散表現 • 任意の離散オブジェクトの集合Vに対して、各離散オブジェクトv∈Vにそれ ぞれD次元のベクトルを割り当て、離散オブジェクトをD次元ベクトルで表現 したもの • 自然言語処理で単語を対象にした場合、「単語分散表現」「単語埋め込み」 という • ベクトル空間により距離や演算が定義できるのでそれを関係性や類 似度にマッピングして用いる
13.
3.3.2 歴史的背景 • ニューラルネット研究からの視点:
分散表現 • 人間の脳が新しい概念を覚える際に既知の事象や概念を結びつけて覚 えるため • 個々の事象は多様な特徴で表現されると考えれていたため • local representation(局所表現)は逆にほとんど疎のベクトル • one-hot vectorはlocal representationに分類される • 2000年ごろにニューラル言語モデルに単語埋め込みが導入され、そこ から分散表現が普及した
14.
3.3.2 歴史的背景 • 自然言語処理からの視点 •
自然言語処理の基本単位である「単語」が持つ「意味」を計算機でど う扱うかという研究から始まる • 分布仮説(単語の意味はその単語が出現した際の前後に出現した単語に より決まる)を元に単語の類似度を与える • 主成分分析(PCA) • ディリクレ配分(LDA)
15.
3.3.2 歴史的背景 • 両分野の融合 •
ニューラル言語モデルの登場により上記二つの研究が融合 • 共に同じ条件からベクトルを取得 • ニューラル言語モデル: 前数単語を利用 • 自然言語処理: 前の単語のみを利用した分布仮説 • distributional と distributedがあるが深層学習の文脈ではdistributedを 用いる
16.
3.3.3 獲得方法 • よい分散表現の条件 •
意味的により類似するオブジェクトはより近い位置に配置 • 逆の意味になる離散オブジェクトは原点を挟んで逆側に配置 • ニューラル言語モデルを用いた獲得方法 • 普通にニューラル言語モデルを学習する • 埋め込み層の変換層が各単語の分散表現に一致
17.
3.3.3 獲得方法 • 対数双線形モデルを用いる獲得方法 •
計算量的な課題に対応するためにニューラル言語モデルから派生し、 単語分散表現を獲得するのに特化した方法 • ニューラル言語モデルはデータ量が大きいほど性能があがるが実際には大規模な ニューラル言語モデルを計算するのは困難 • 数百万語彙のニューラル言語モデルを計算するのは困難 • word2vec(及び対数双線形モデル)の登場 • Continuous Bag of Words • Skip-gram
18.
word2vecの比較 CBOW Skip-gram は 良い
天気 は 良い 天気です ね です ね 天気 天気
19.
3.3.3 獲得方法 • 負例サンプリング •
詳細は4.3.4章にて • 識別モデルを学習していることに相当 • 実データの確率分布からサンプリングされたデータ • 別の確率分布からサンプリングされたデータ • (3.22)と(3.25)を比較するとモデルの形式が変わっていることがわかる
20.
3.3.4 利用例 • (5章で紹介する)機械翻訳、質問応答、対話タスクをはじめとす る応用タスクで分散表現は使われている •
単語や言語的特徴が意味的に似ているか似ていないかの指標 • 意味関係の演算として利用 • 構文解析や意味解析など言語解析ツールの素性情報 • 深層学習で用いる埋め込み行列の初期値
21.
3.3.5 今後の発展 • 今現在だったらword2vecを使うのがよい •
単語以外にも分散表現を求める方法があるが、決定的ではない • 句 • 文 • 文章 • word2vecは汎用的に使える表現を得るがタスクに応じた「観 点」が入れられる分散表現も欲しい
Download




























![[最新版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180607030706-thumbnail.jpg?width=640&height=640&fit=bounds)








![[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180606065226-thumbnail.jpg?width=640&height=640&fit=bounds)






























