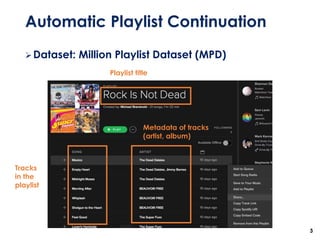
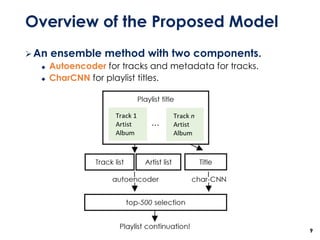
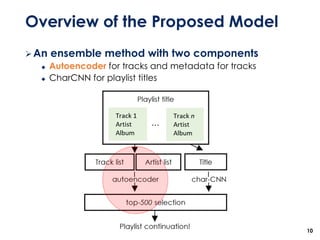
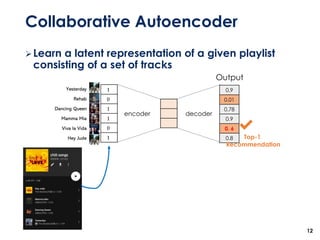
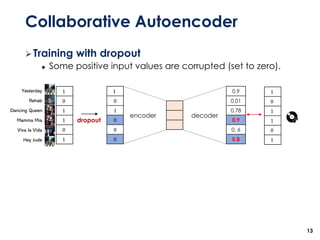
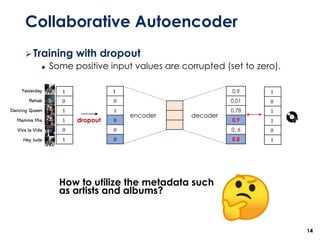
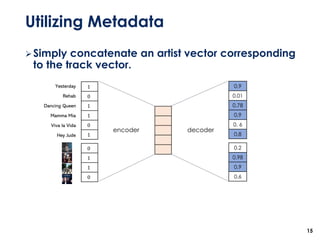
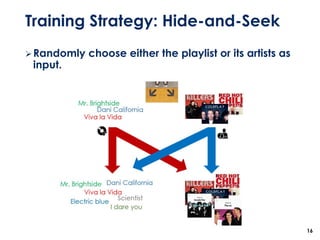
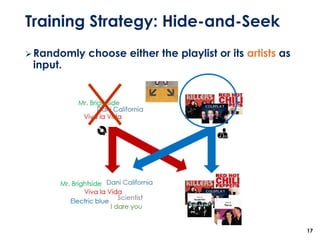
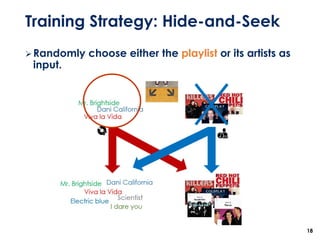
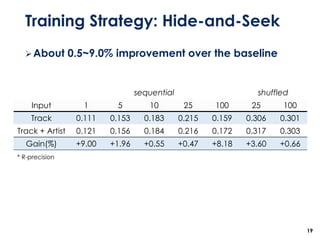
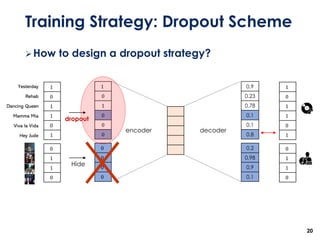
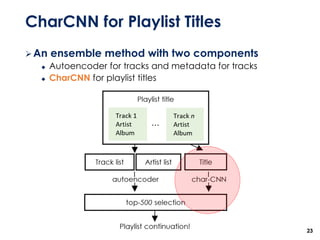
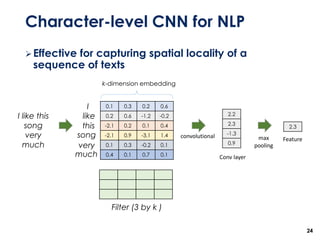
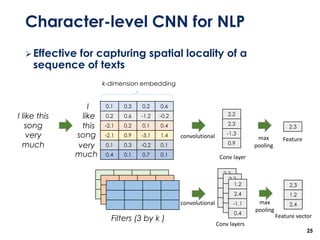
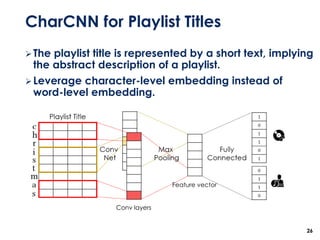
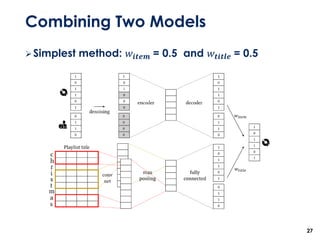
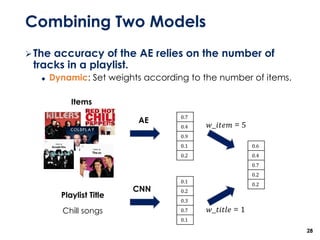
The document discusses the development of a multimodal collaborative filtering model for automatic playlist continuation, presented by a team from Sungkyunkwan University, which achieved 2nd place in a competition. The proposed model combines an autoencoder for track metadata with a character-level CNN for playlist titles, addressing various challenges such as dealing with sparse information and different input types. Experimental results indicate significant improvements in recommendation accuracy through innovative training strategies and model combinations.














![[222]누구나 만드는 내 목소리 합성기 (부제: 그게 정말 되나요?)](https://cdn.slidesharecdn.com/ss_thumbnails/222voice-181012004315-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]Pervasive Attention: 2D Convolutional Neural Networks for Sequence-to-...](https://cdn.slidesharecdn.com/ss_thumbnails/20180907pervasiveattention2dconvolutionalneuralnetworksforsequence-to-sequenceprediction-180907000649-thumbnail.jpg?width=640&height=640&fit=bounds)







![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MarketIN팀] : 디지털 마케팅 헬스체킹 서비스](https://cdn.slidesharecdn.com/ss_thumbnails/09marketin-220124105610-thumbnail.jpg?width=640&height=640&fit=bounds)



![[211] 인공지능이 인공지능 챗봇을 만든다](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=640&height=640&fit=bounds)








































