Download as PDF, PPTX



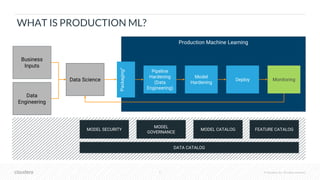
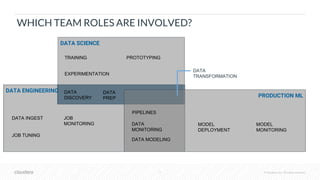

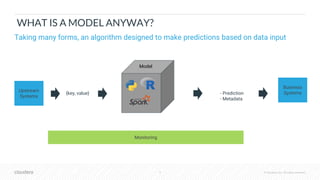
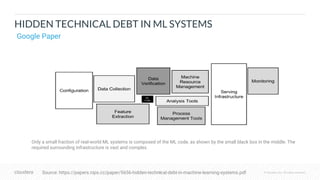
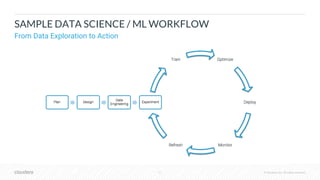
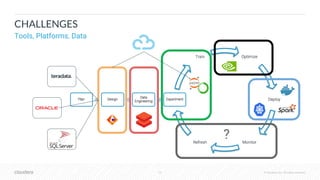
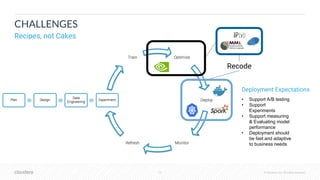

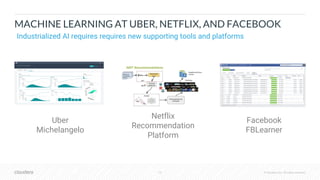
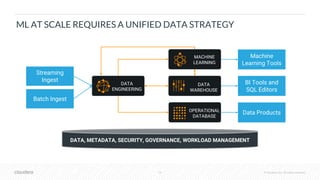




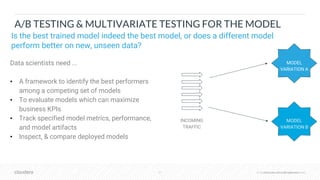


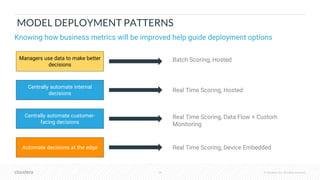




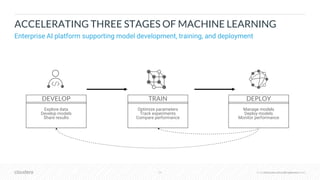
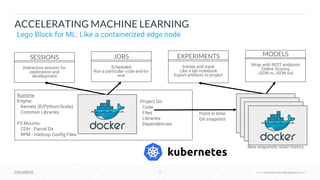





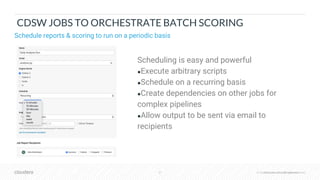



The document outlines the process of deploying machine learning models, emphasizing the transition from strategy to implementation within various organizational contexts. It discusses key roles involved, production machine learning practices, common challenges, and the significance of having a unified data strategy for successful model deployment and monitoring. Additionally, it highlights Cloudera's Data Science Workbench as a platform designed to streamline model development, training, and deployment while ensuring collaboration and security.





















































































