Downloaded 78 times









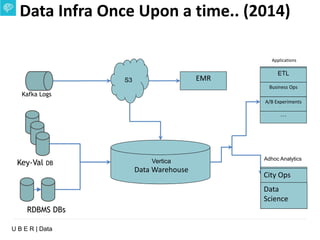


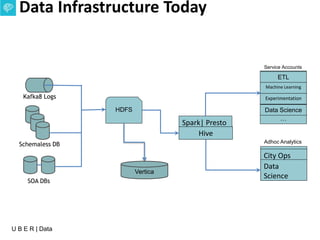





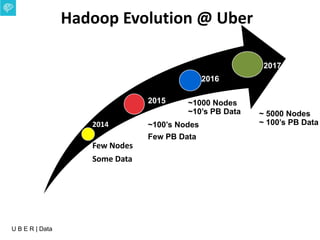
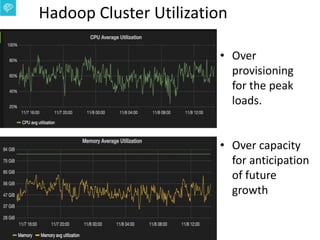
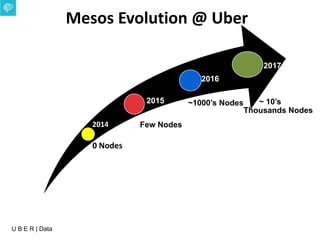
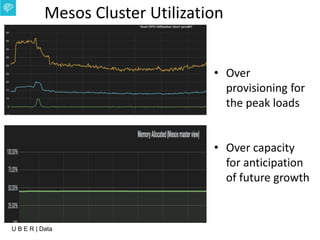
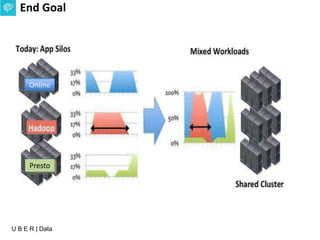


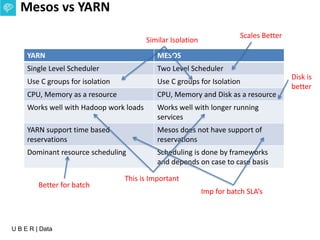



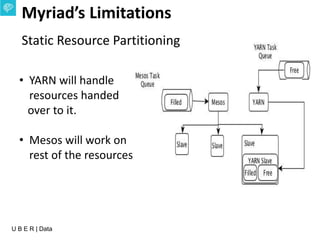
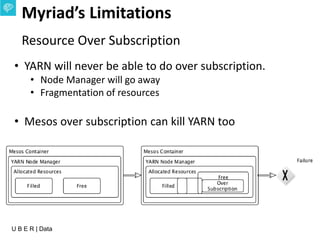
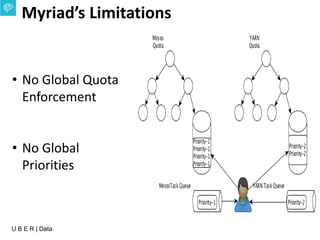




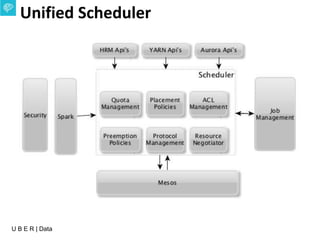
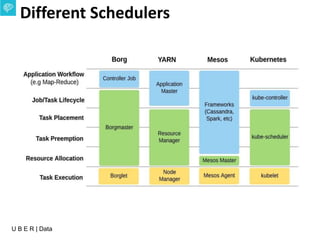
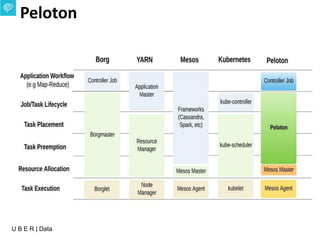
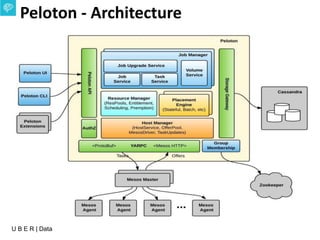
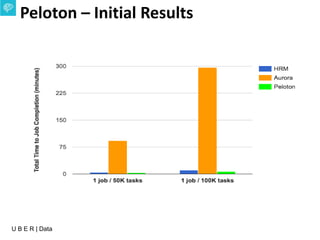








The document presents an overview of Uber's data infrastructure evolution from 2014 to present, highlighting challenges such as scalability and reliability in data management. It discusses the integration of various tools like Hadoop, Mesos, and a unified scheduler for efficient resource management and data processing. Future directions include improvements in batch workload support and the development of the Peloton framework for enhanced scheduling capabilities.






















































































