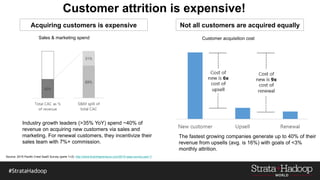
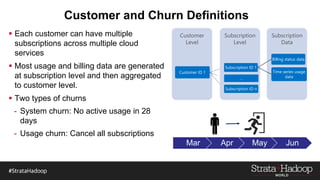
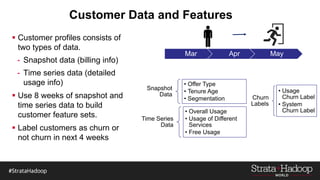
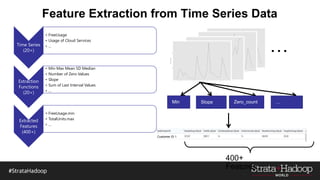
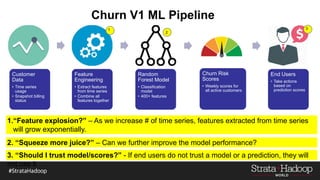
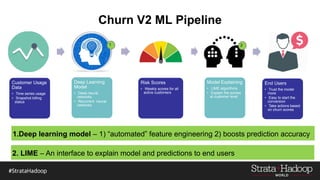
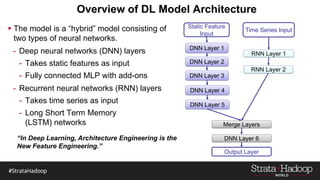
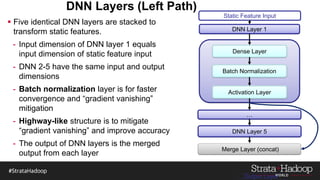
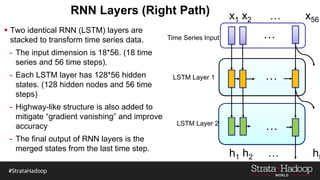
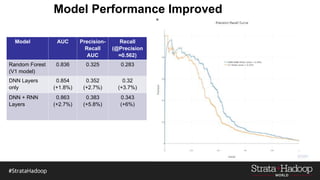
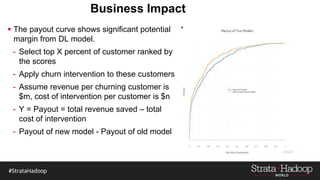
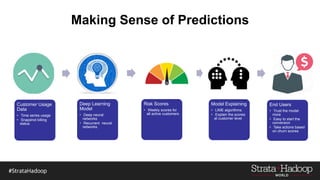
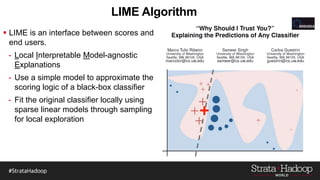
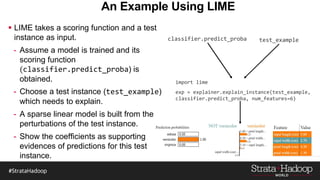
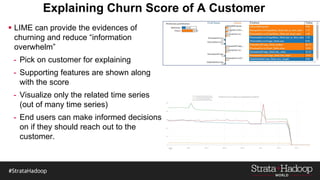
The document discusses the development of a predictive model for customer churn in Azure using deep learning techniques, with a focus on improving model performance and explaining predictions using LIME. It highlights the importance of customer retention, the significant costs associated with acquiring new customers, and the need for effective churn intervention strategies. Additionally, it outlines the use of deep neural networks and recurrent neural networks to enhance prediction accuracy and the role of LIME in making model predictions interpretable for end users.