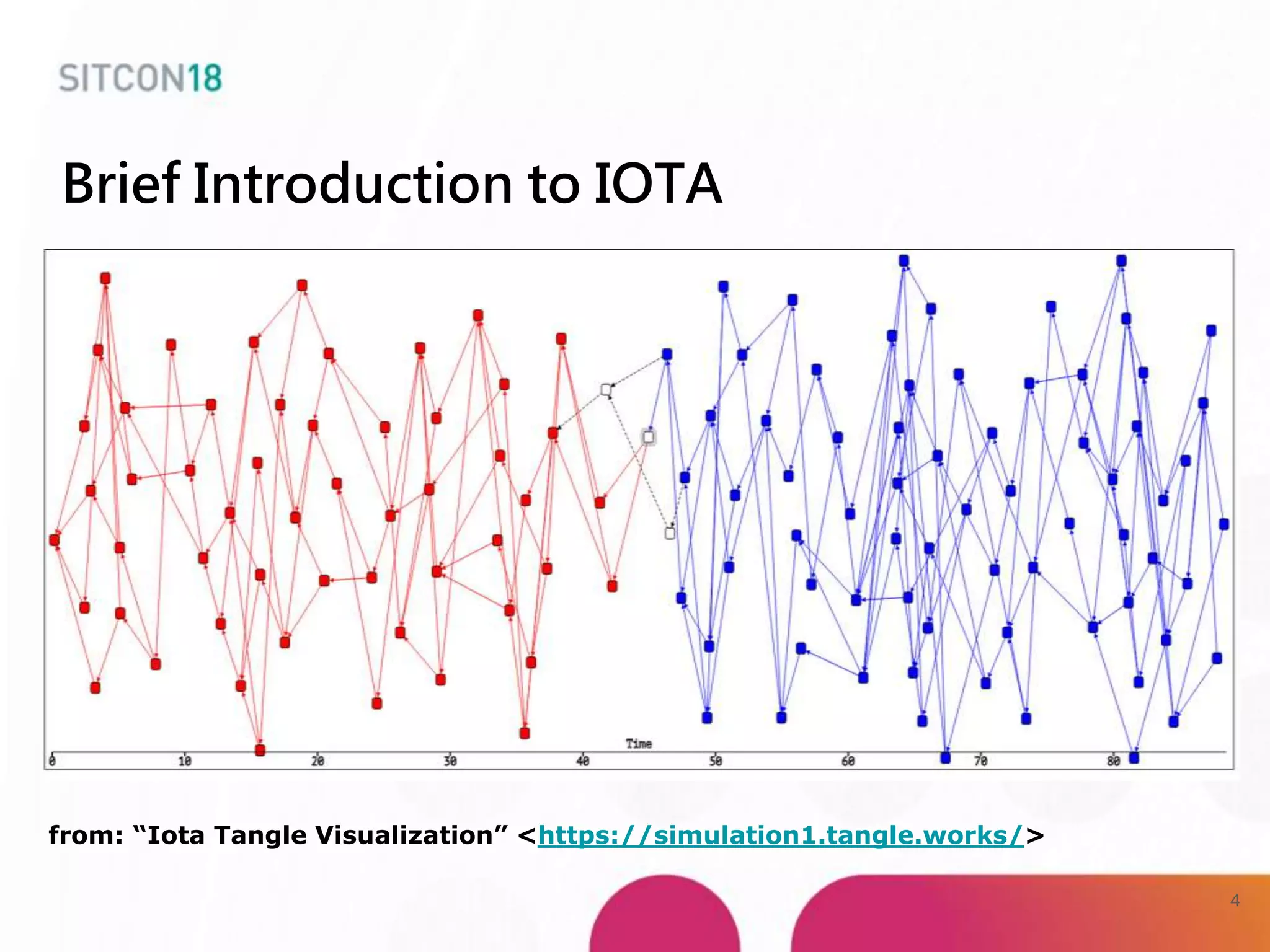
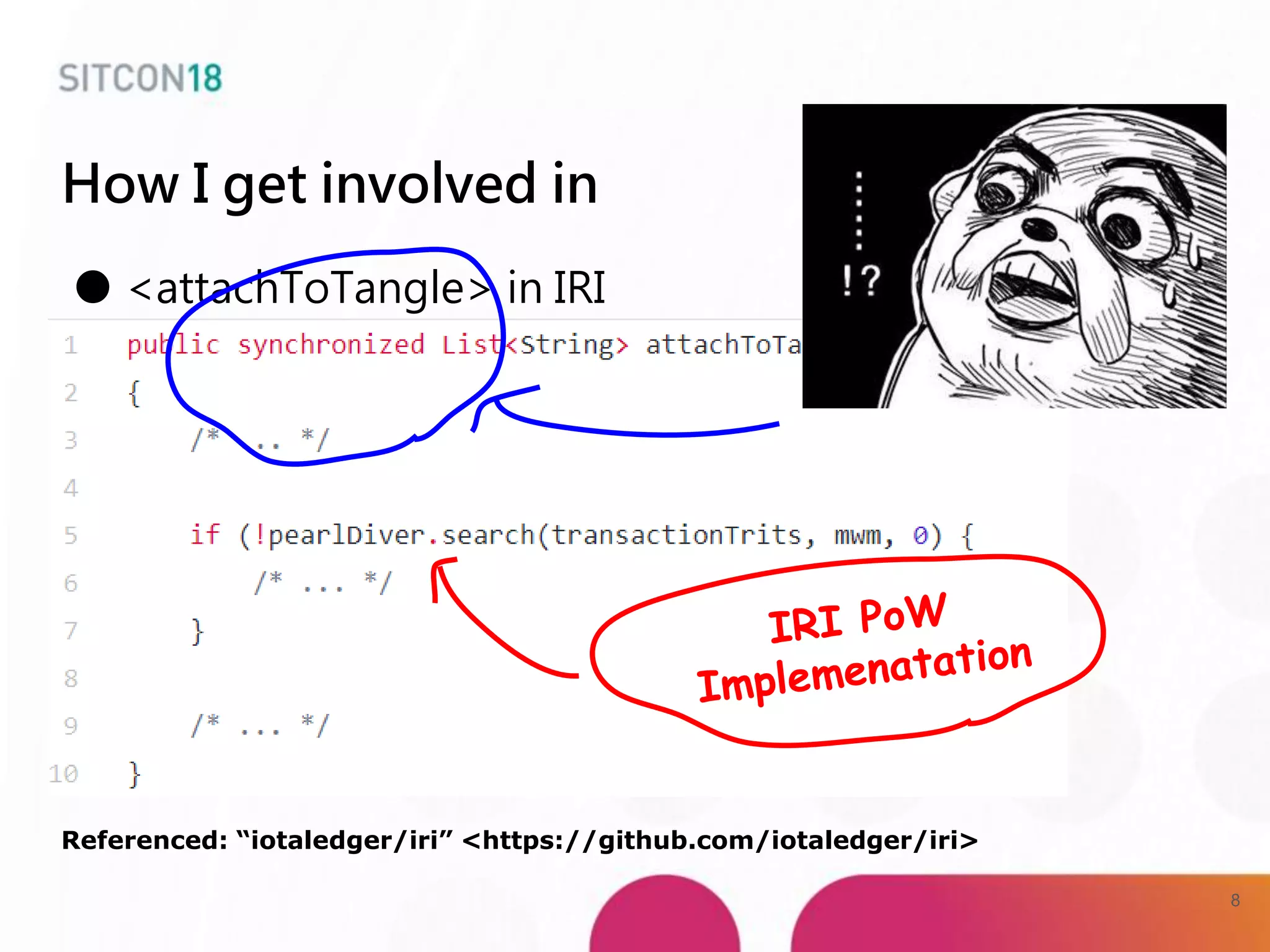
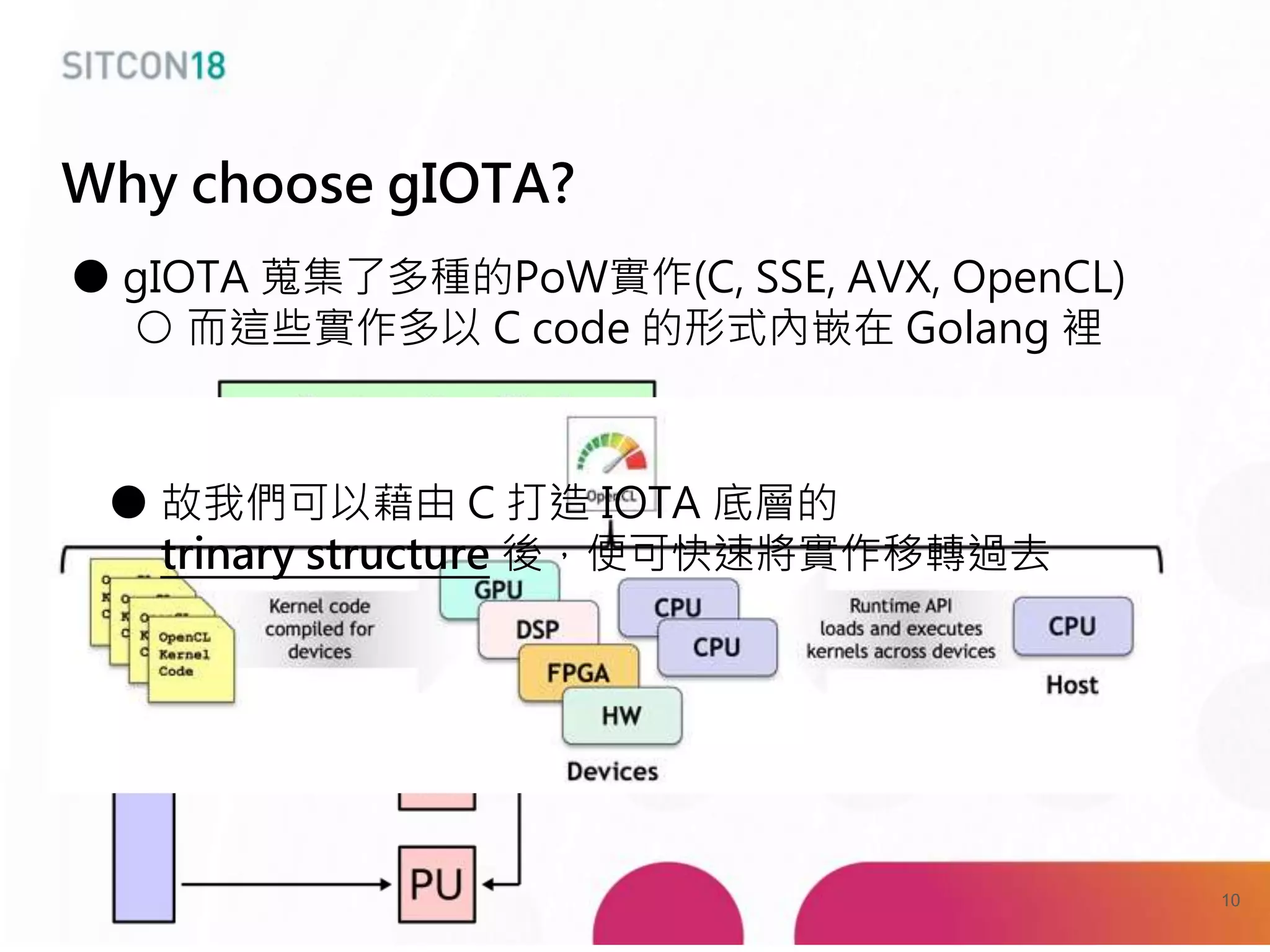
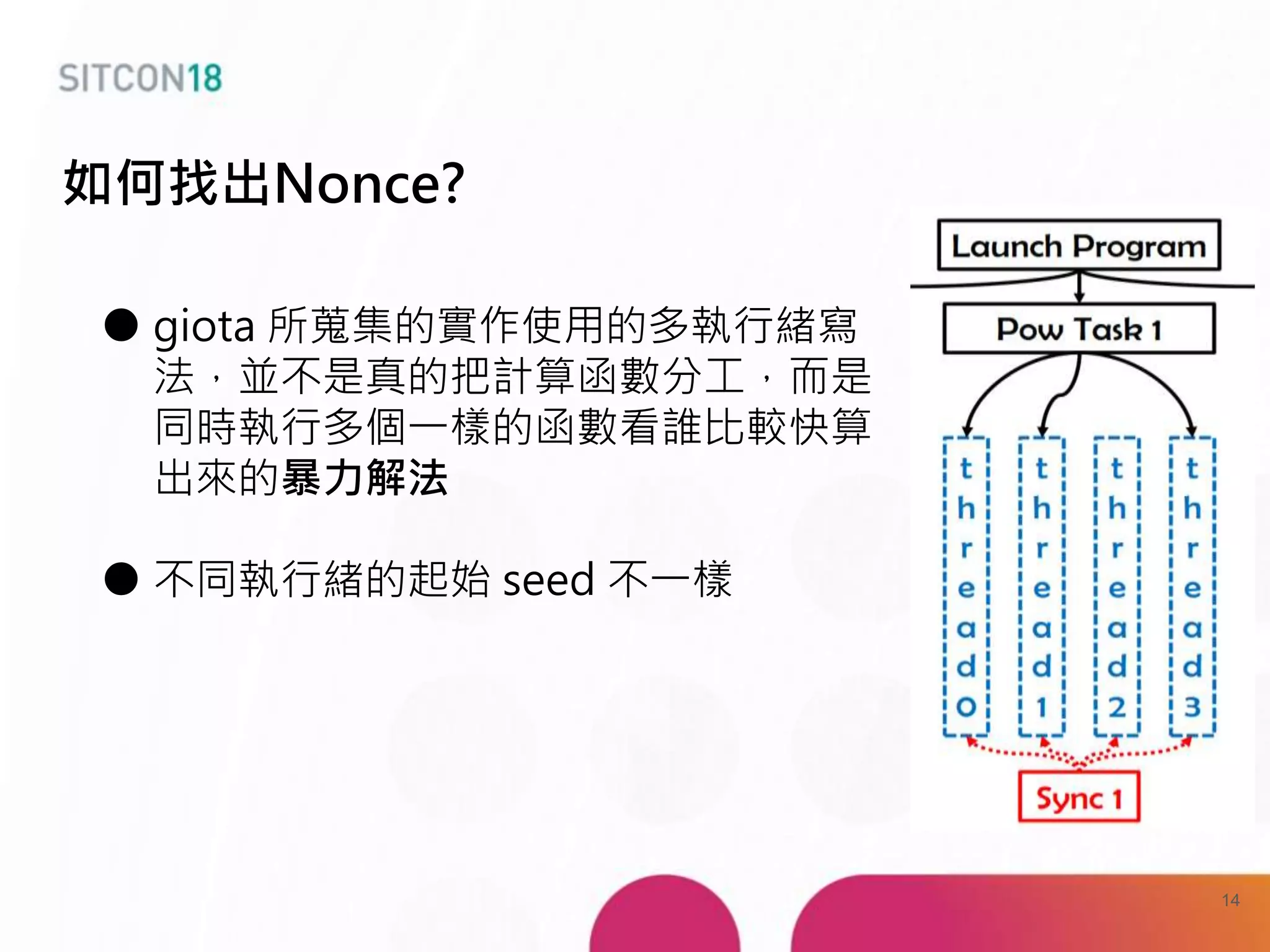
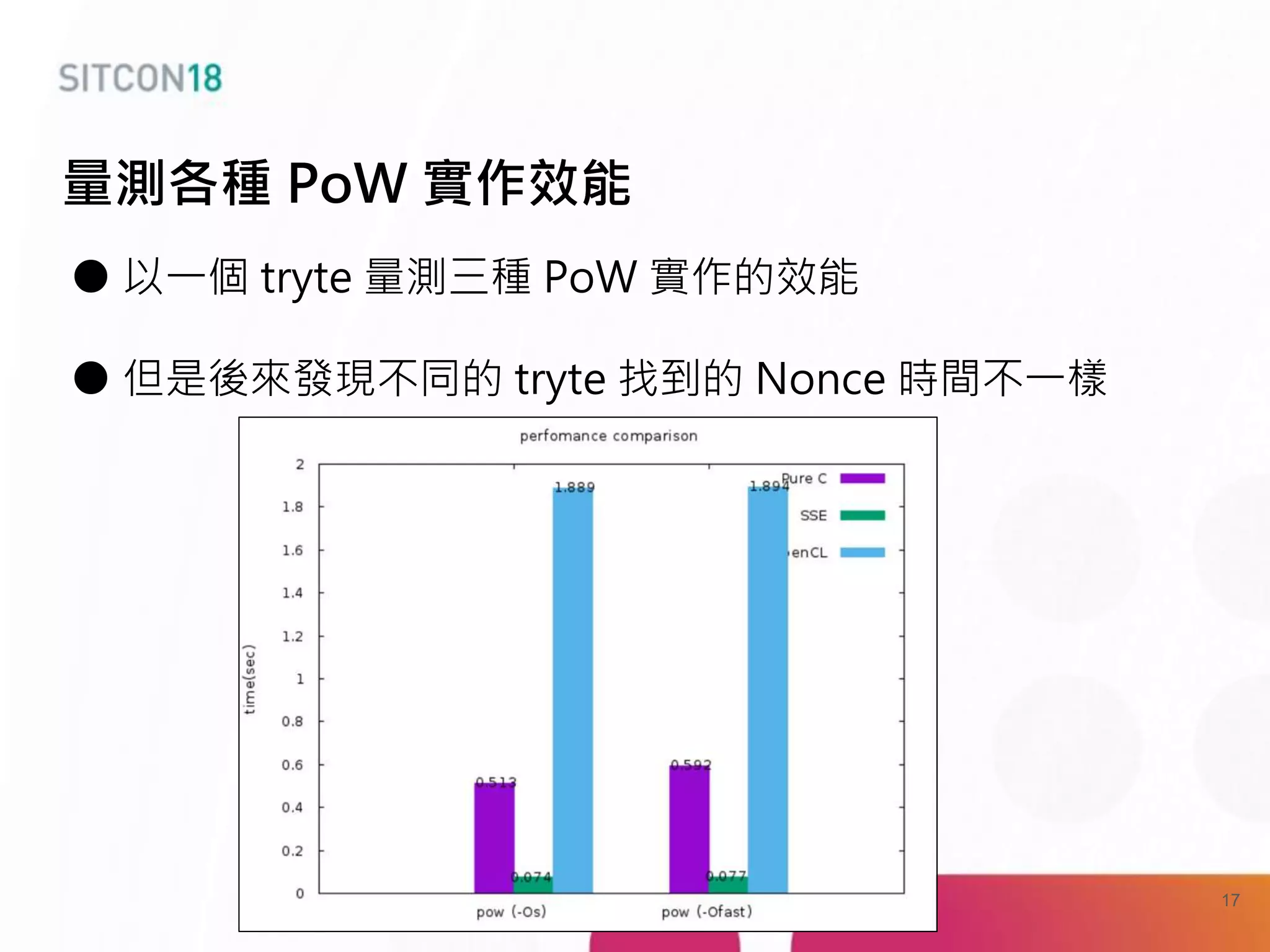
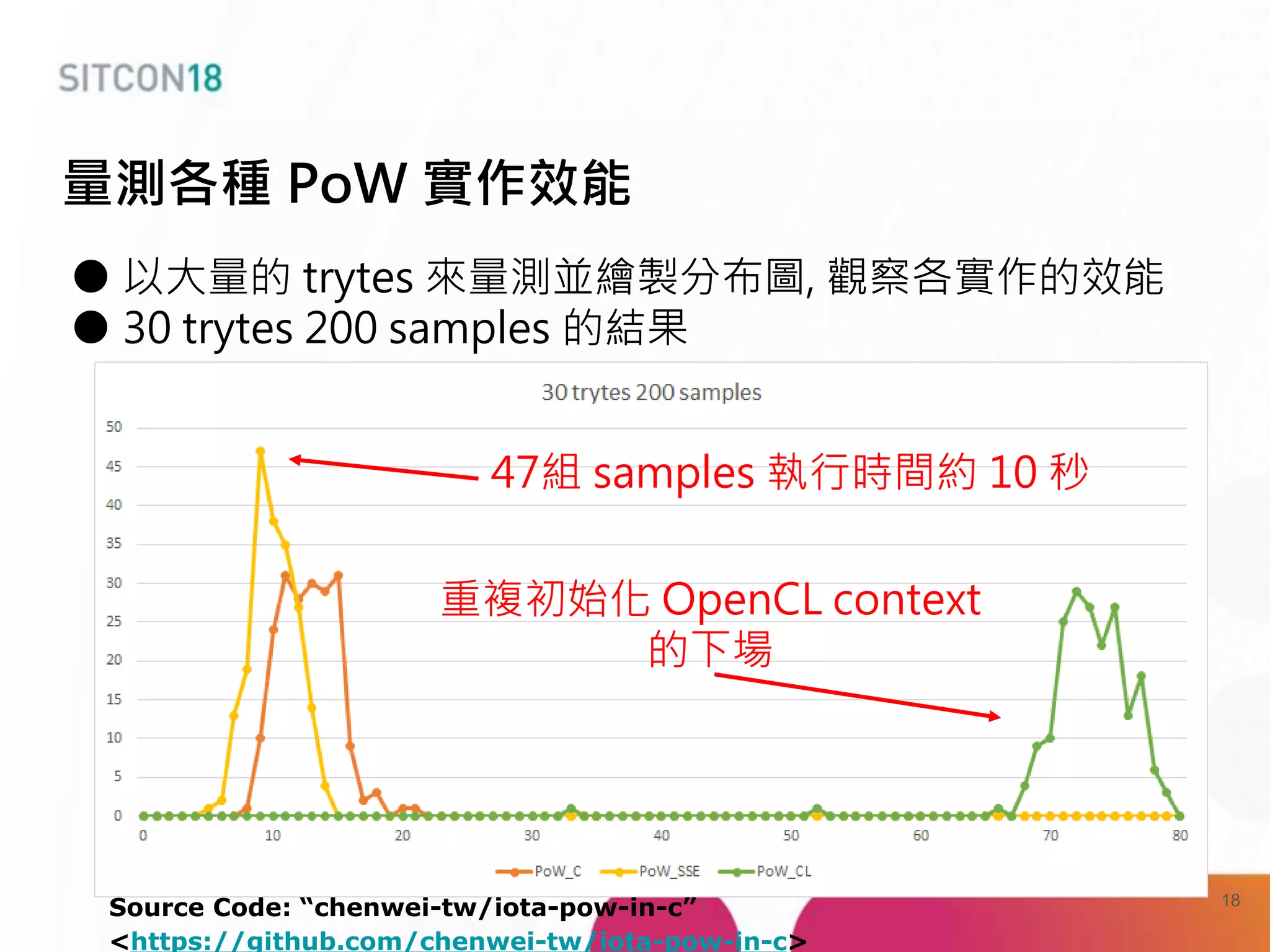
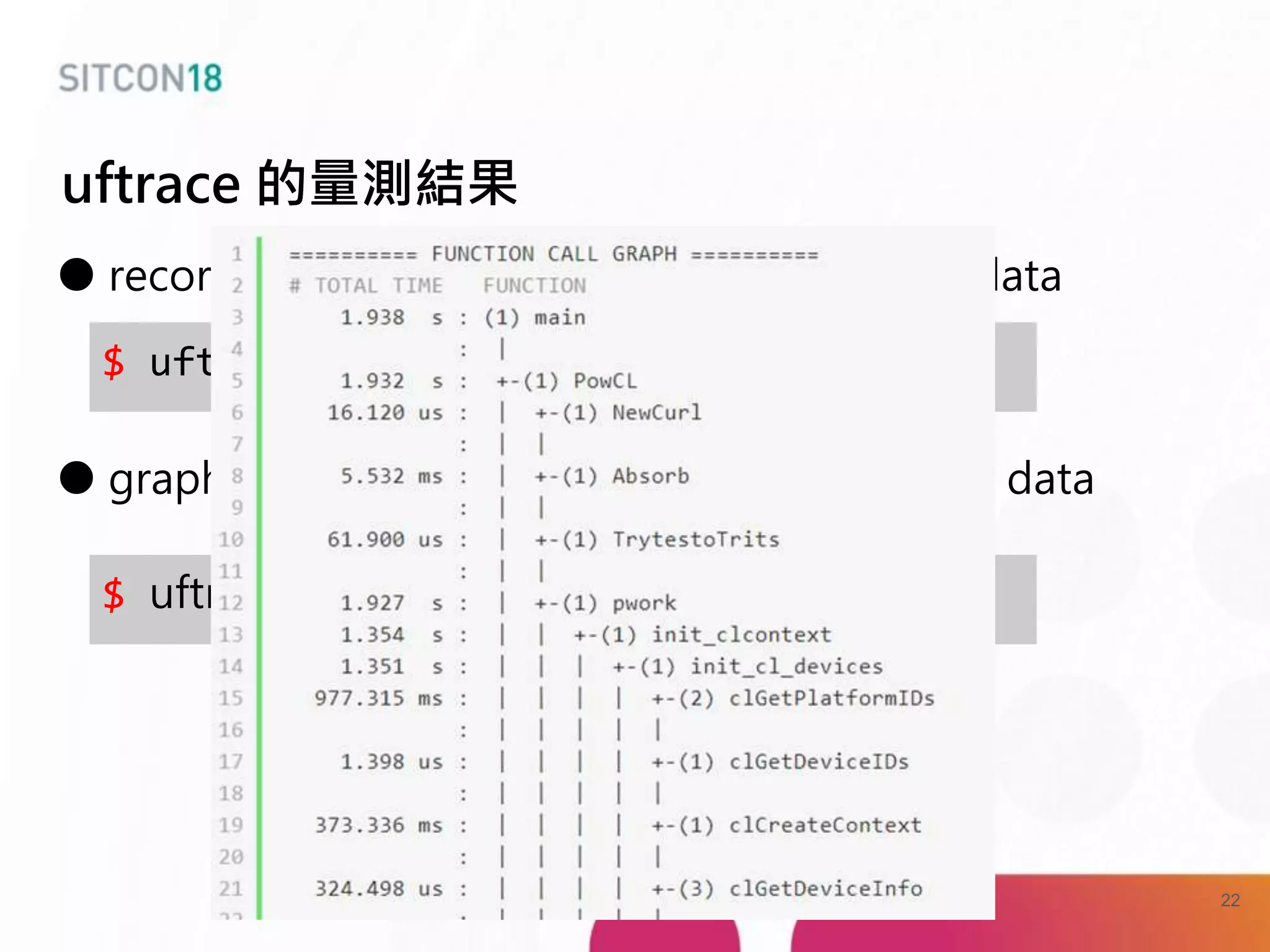
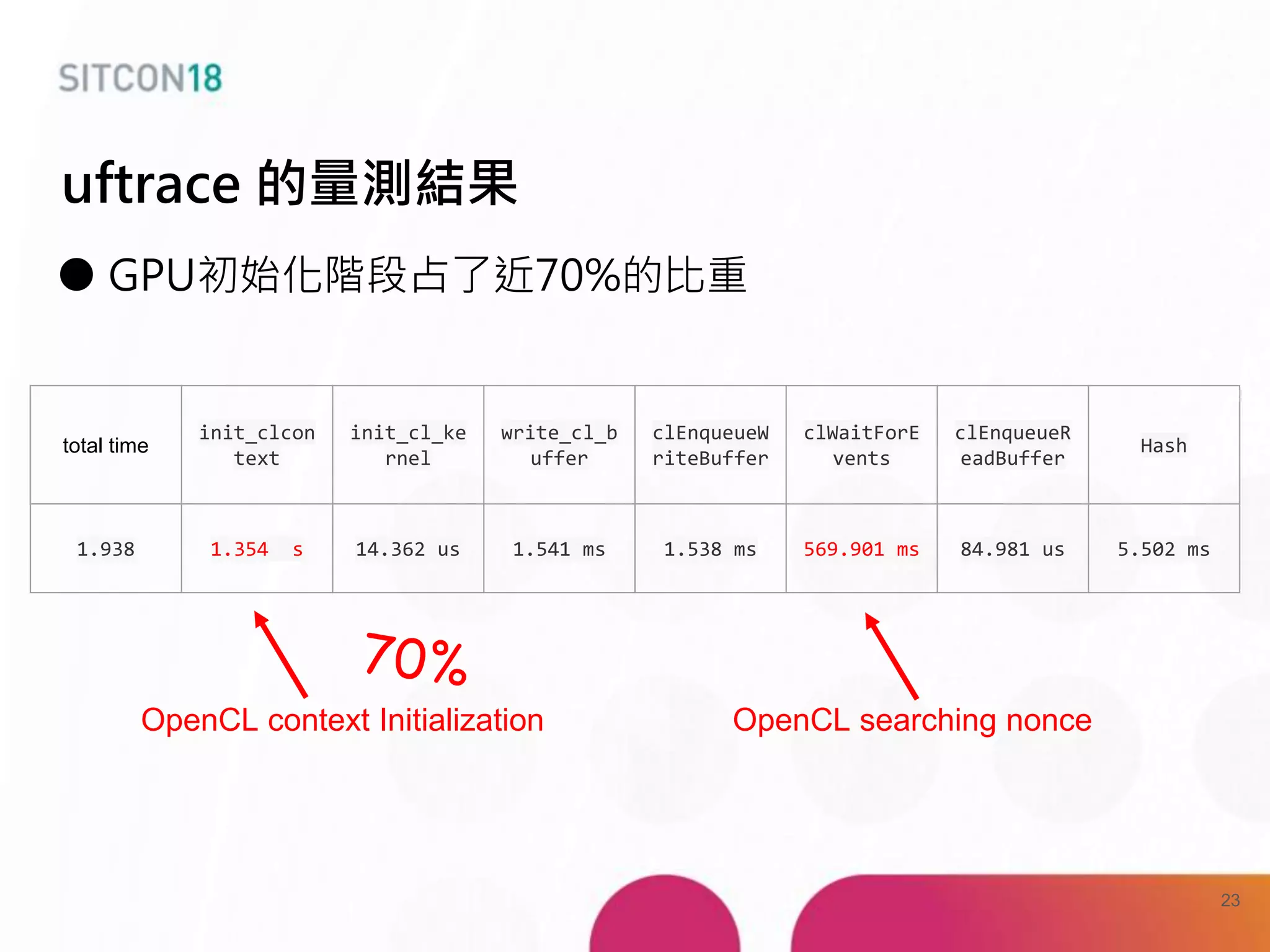
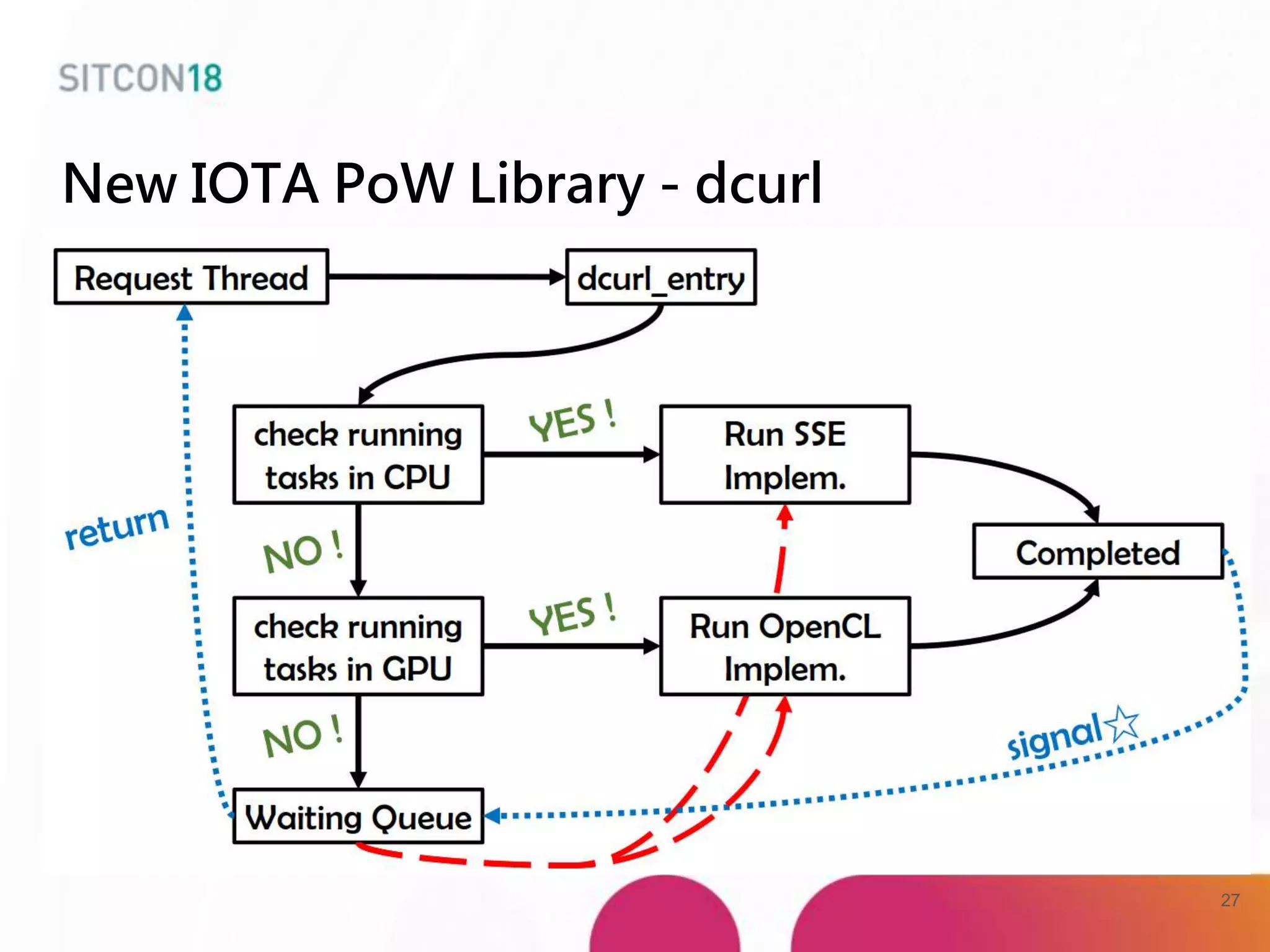
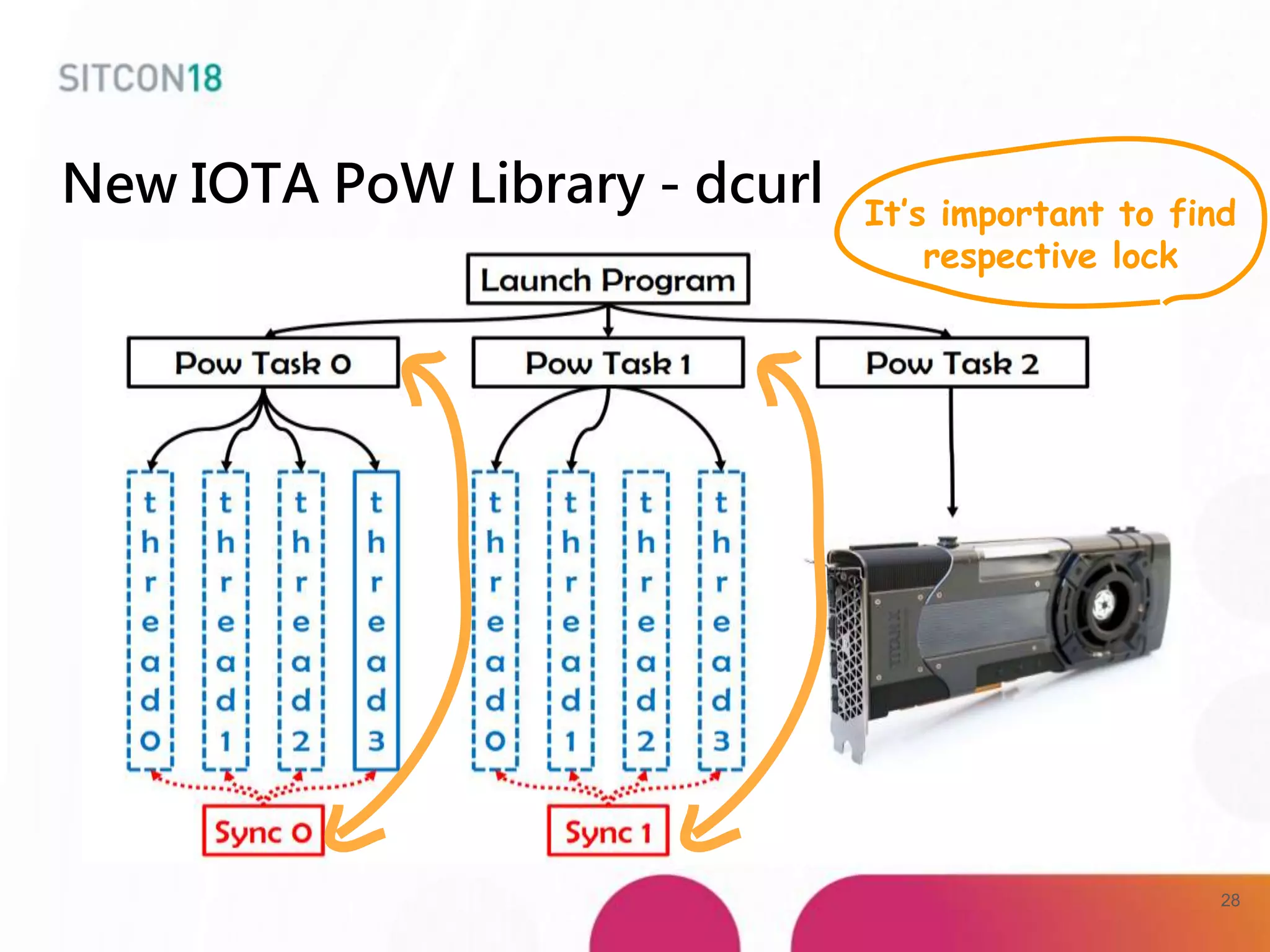
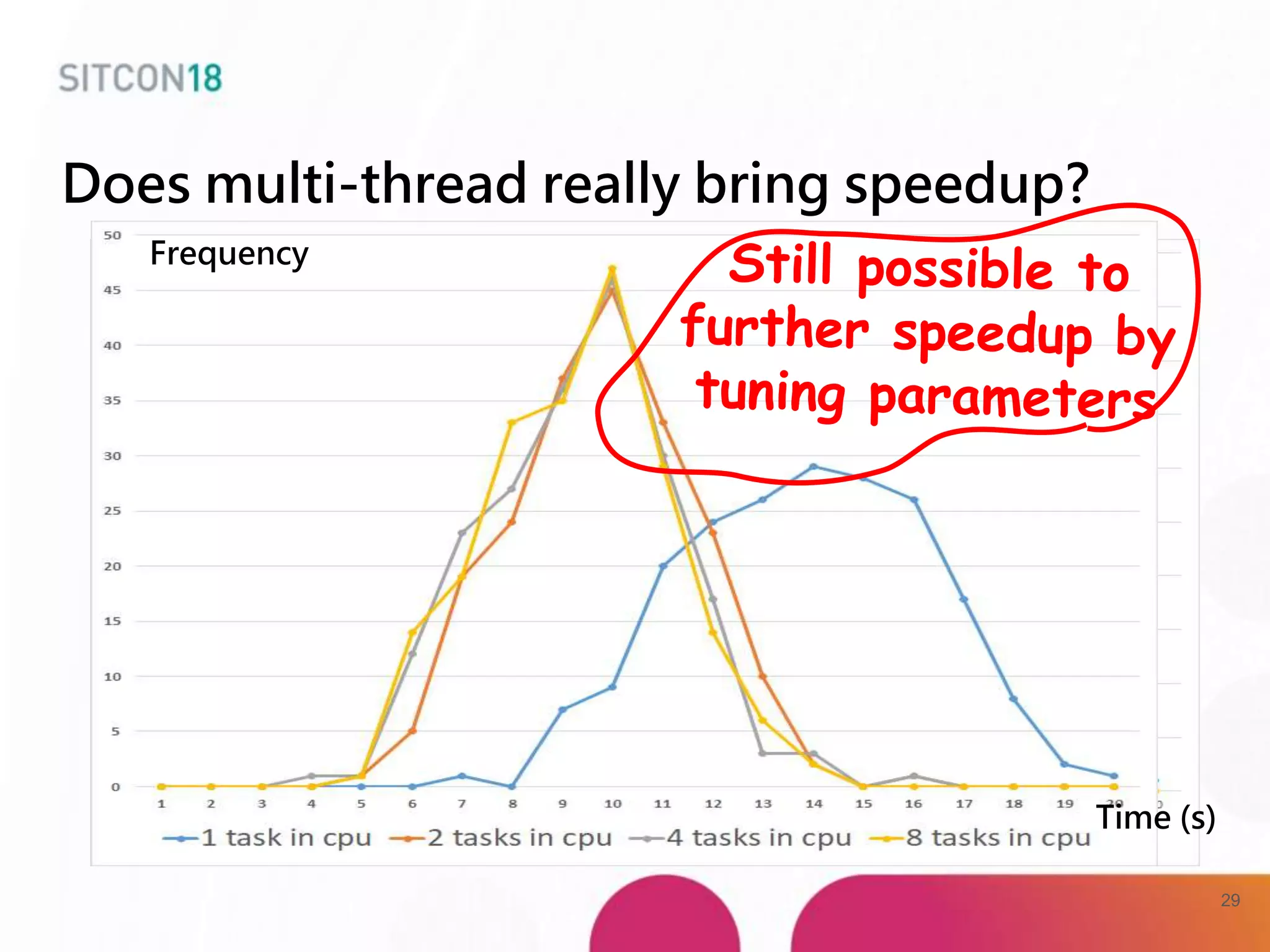
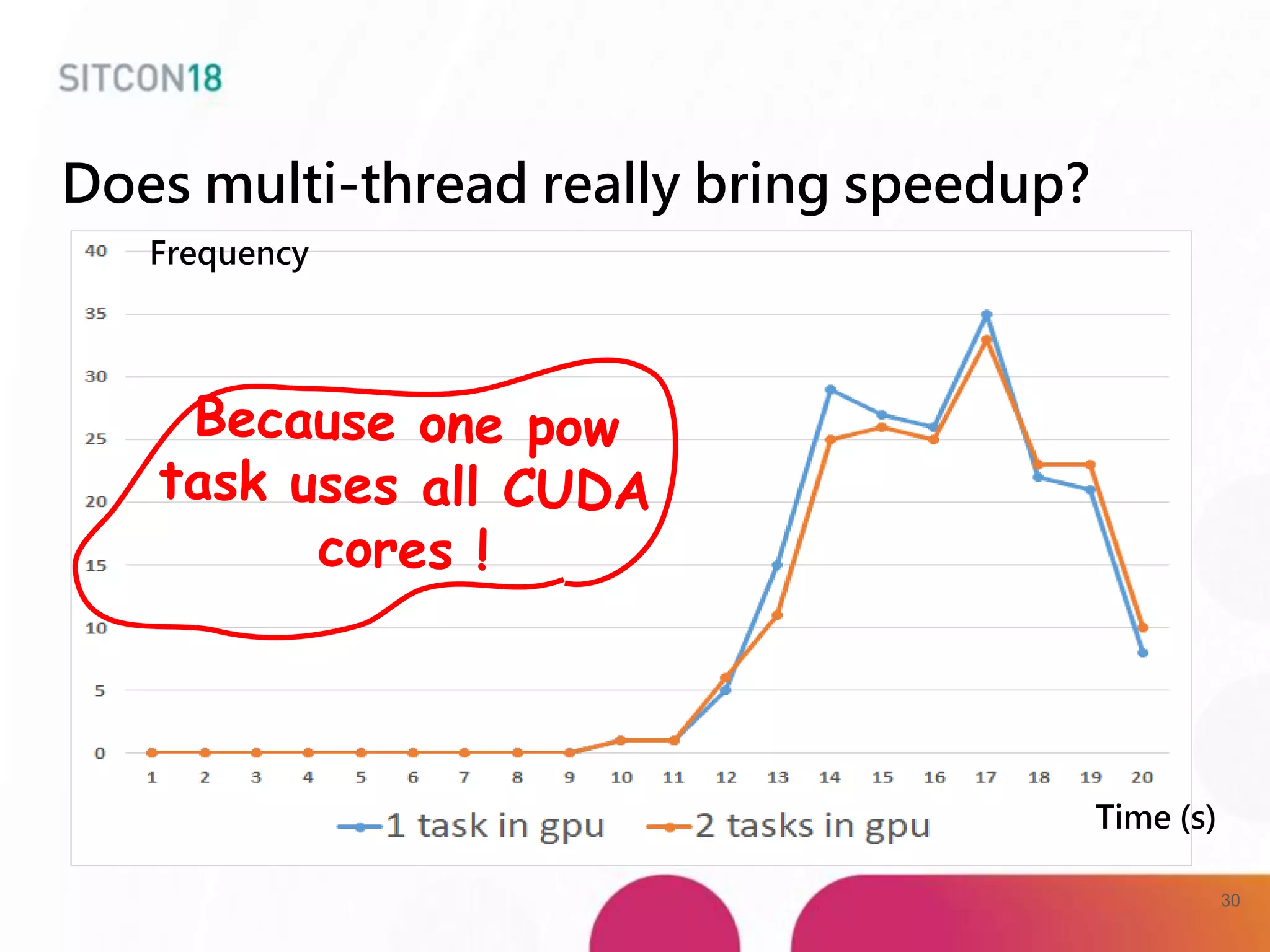
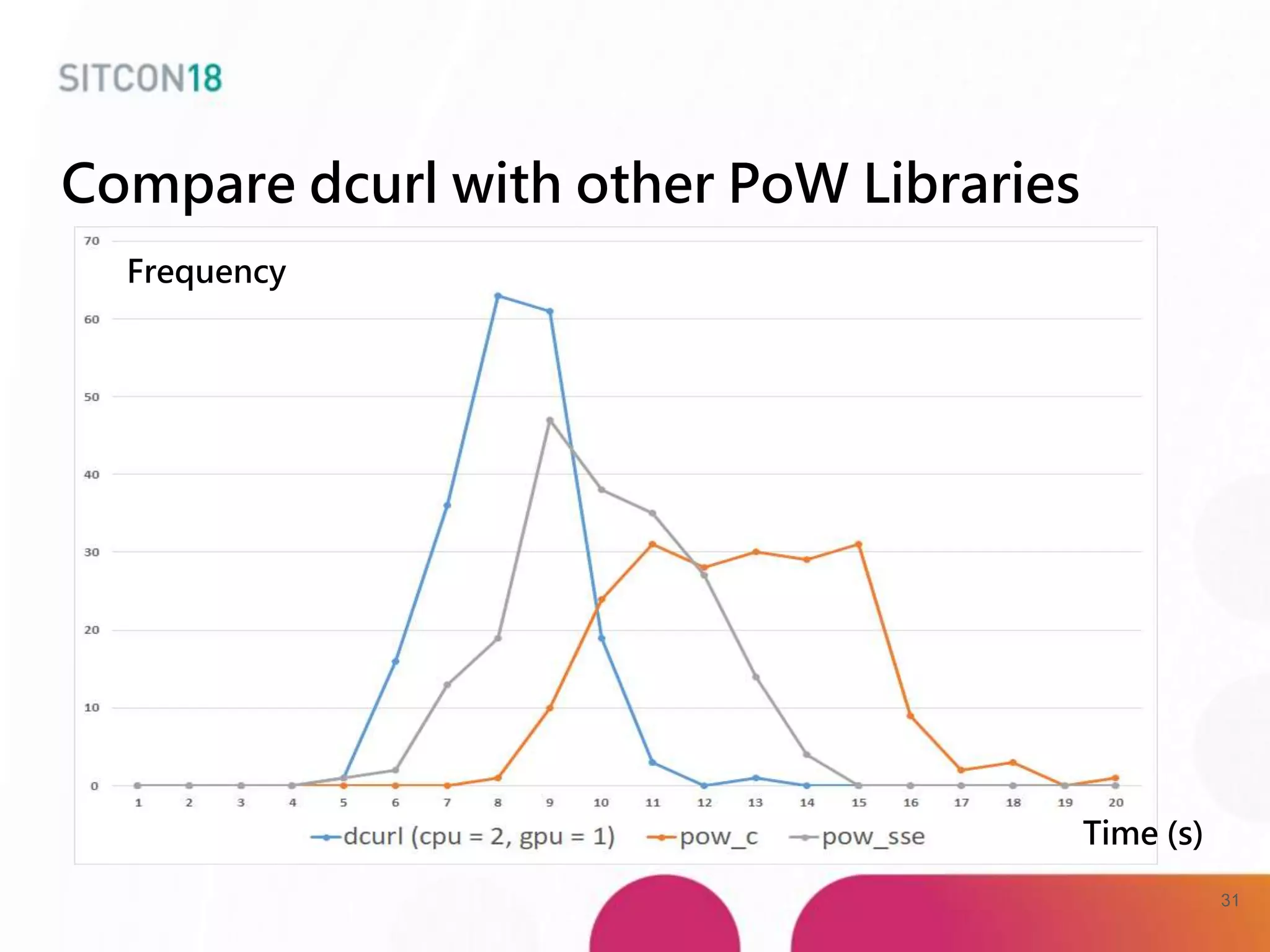
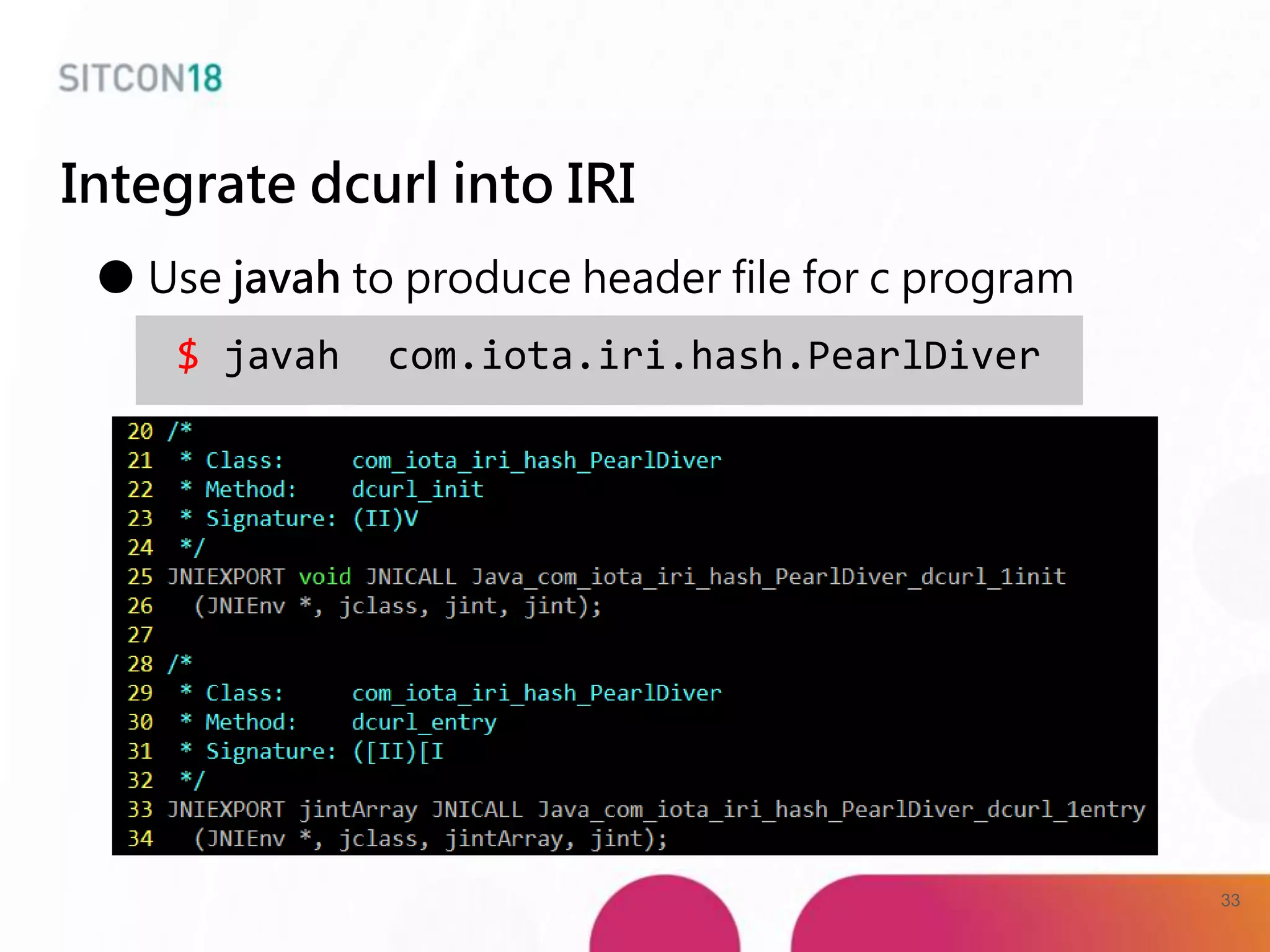
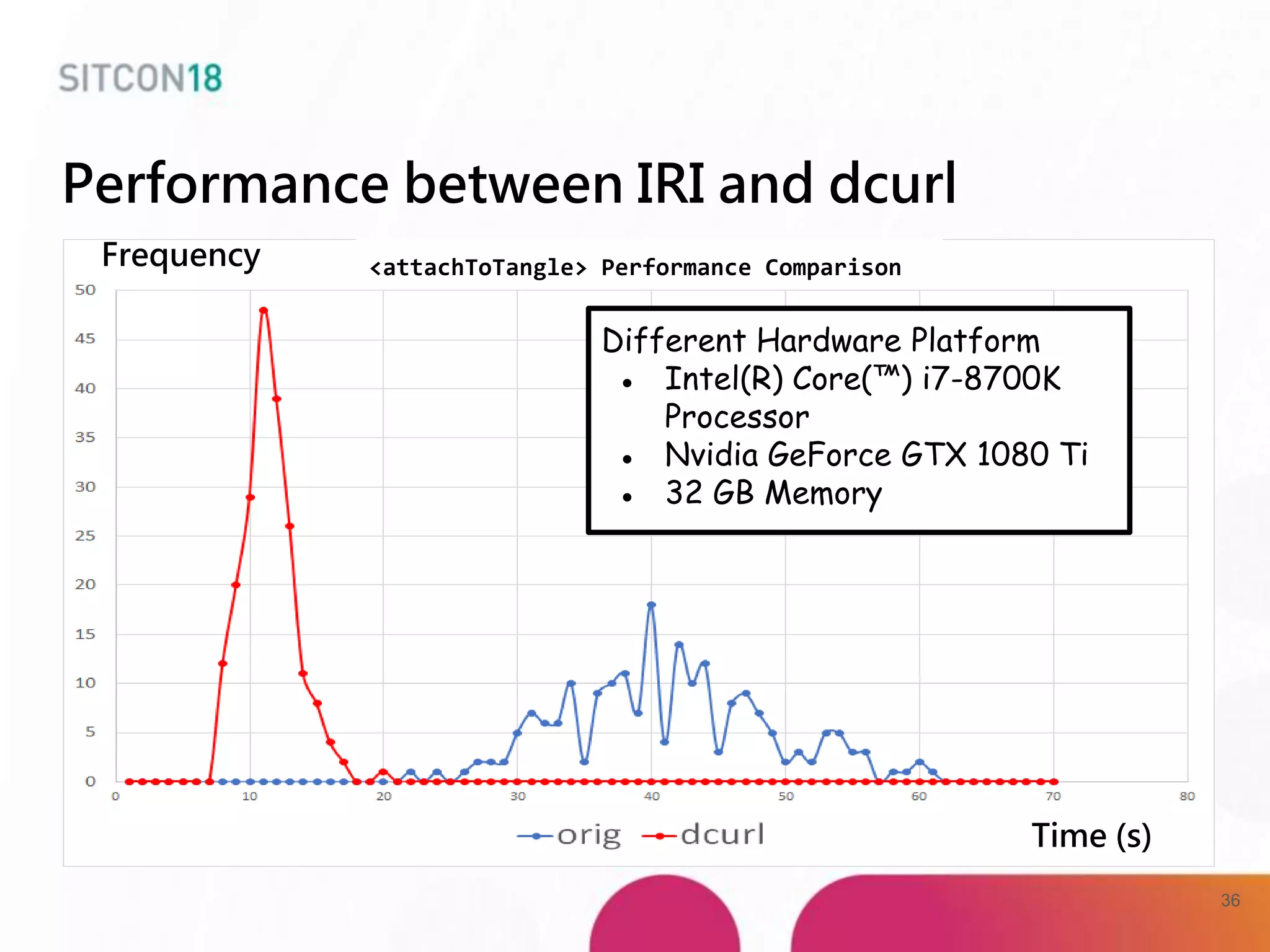
This document discusses analysis and improvements made to the Proof of Work (PoW) implementation used in IOTA. It begins with introductions of the authors and provides background on IOTA and how transactions work. It then analyzes the performance of different PoW implementations in the gIOTA library and identifies issues with the OpenCL version. A new library called dcurl is created to optimize PoW performance by enabling multi-threaded execution and leveraging different hardware. dcurl is integrated into IRI and shown to provide significant performance improvements over the existing PoW implementation when attached to the Tangle. Future work areas are also discussed.