Download to read offline




![11
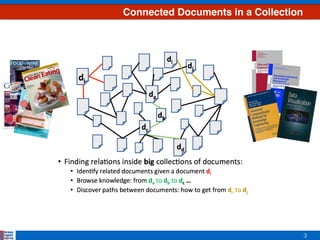
Scenario
[ 0.243, 0.145, 0.600, 0.022]
corpus Prob. Topic Model
Topic 1
Topic 2
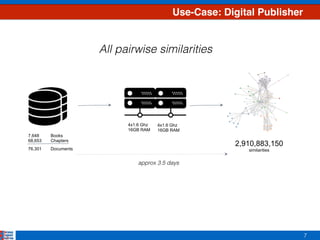
Topic 3
Dirichlet Distribution
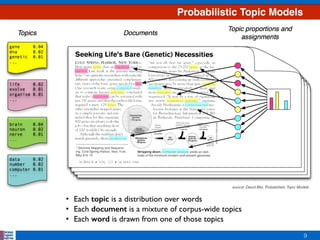
• Exponential family distribution over the simplex,
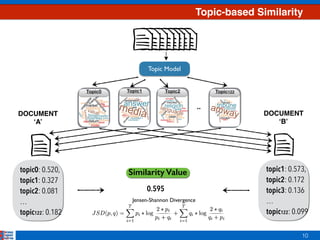
i.e. positive vectors that sum to one](https://image.slidesharecdn.com/efficientclustering-171215125442/85/Efficient-Clustering-from-Distributions-over-Topics-11-320.jpg)

![13
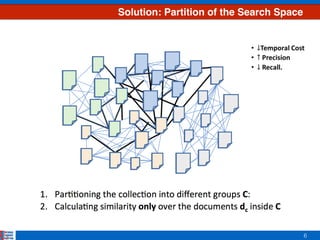
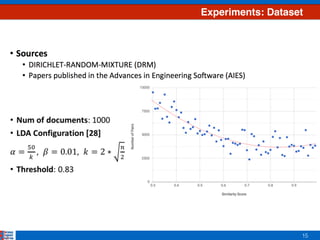
Approach 2: RDC
Ranking on Dirichlet-based Clustering (RDC)
• Only considering the top n topics from the ranked list of probability distribu7ons [29]
• Based on the assump7on that the highest weighted topics have a high influence in the
rest of topics when calcula7ng distances
0.23 0.18 0.33 0.13 0.13 n=2, P =
2 0 R =
1 0 2 3 4](https://image.slidesharecdn.com/efficientclustering-171215125442/85/Efficient-Clustering-from-Distributions-over-Topics-13-320.jpg)



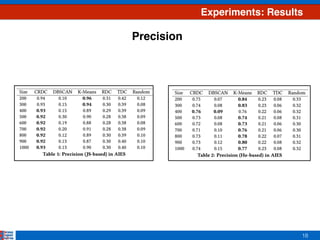
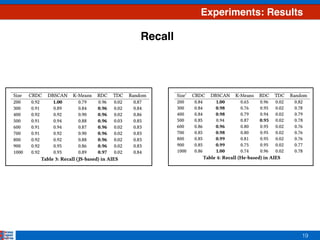
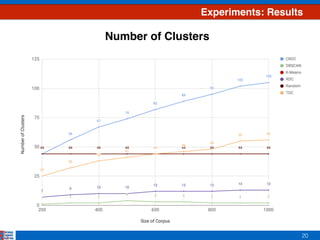
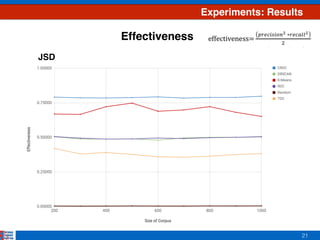
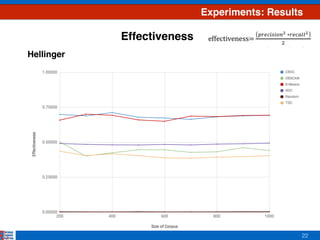
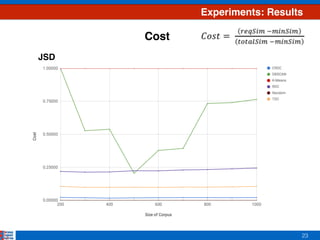
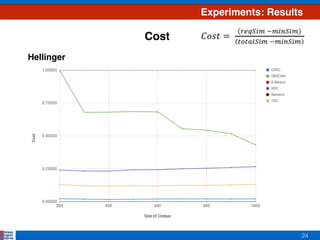
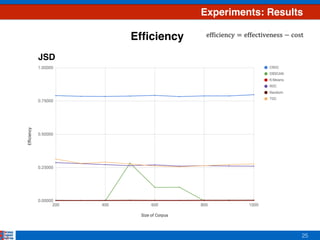
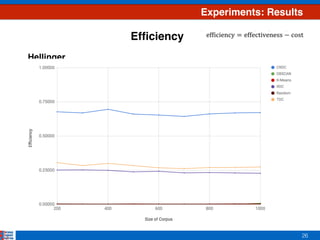


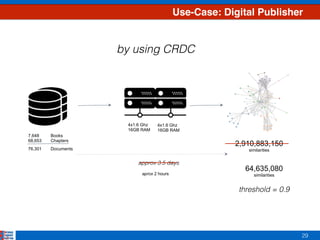


This document presents an efficient approach for clustering large document collections based on topic distributions generated by probabilistic topic models like LDA. It proposes three approaches - TDC, RDC, and CRDC - that cluster documents based on variations or rankings of their topic distributions rather than the distributions directly. An evaluation on Apache Commons Math dataset shows CRDC improves over baselines in effectiveness, cost and efficiency metrics. Future work will explore hybrid methods combining these approaches with existing techniques.





























































