Downloaded 182 times
















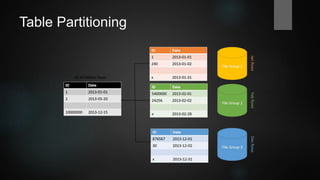

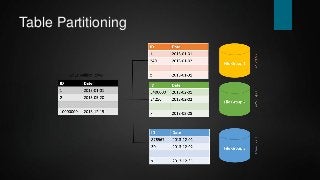






This document provides an overview of database performance tuning with a focus on SQL Server. It begins with background on the author and history of databases. It then covers topics like indices, queries, execution plans, transactions, locking, indexed views, partitioning, and hardware considerations. Examples are provided throughout to illustrate concepts. The goal is to present mostly vendor-independent concepts with a "SQL Server flavor".