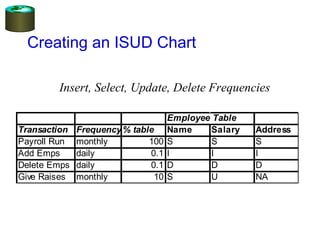
The document discusses physical database design and tuning. It covers topics such as understanding the workload, index selection guidelines, clustering and indexing tools. Database tuning involves tuning indexes, tuning the conceptual schema such as normalization, and tuning queries. The goal is to refine the initial design based on the actual database usage to improve performance.