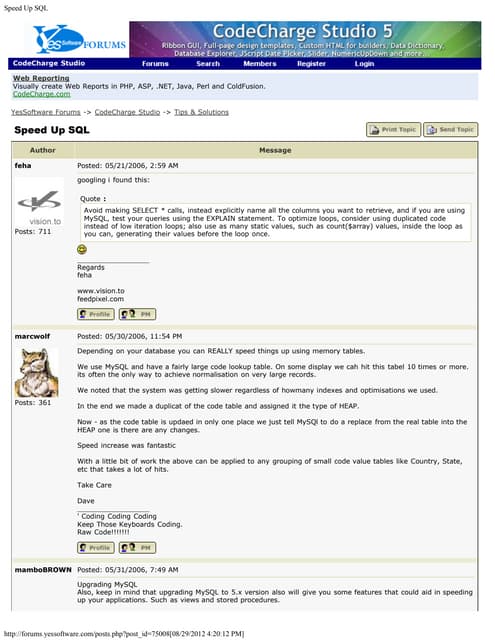
Downloaded 21 times


















This document provides tips to help developers work more efficiently with databases and SQL Server. It includes tips for using object-relational mapping tools, writing efficient T-SQL code, creating optimal indexes, and designing databases for performance. The tips cover topics such as parameterizing queries, writing stored procedures for complex reads, minimizing transactions and locks, and normalizing database structure. The goal is to help developers avoid common issues that can degrade database and application performance.