Download to read offline



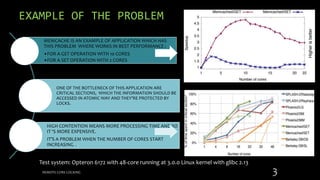
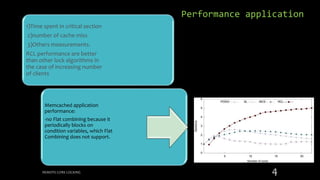
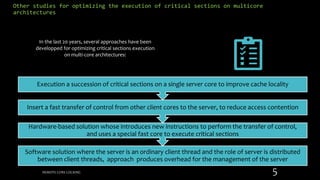


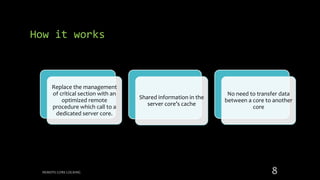







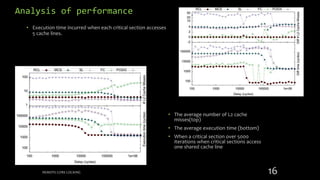



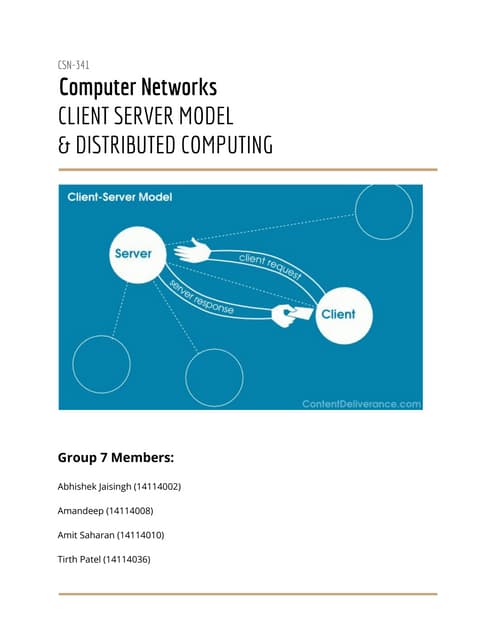
Remote Core Locking (RCL) is introduced to enhance the performance of multithreaded applications by optimizing critical section execution on multicore architectures, addressing issues like access contention and cache misses. By transferring critical section management to a designated server core, RCL achieves better efficiency compared to traditional lock algorithms. Future work includes developing an adaptive RCL runtime to dynamically switch locking strategies and balance loads across multiple servers.