Downloaded 172 times












![2.1: Zen 2: The AMD 7nm Energy-Efficient High-Performance x86-64 Microprocessor Core© 2020 IEEE
International Solid-State Circuits Conference
18 of 33
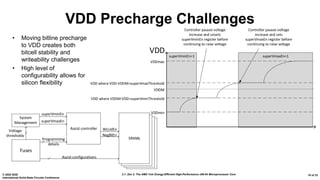
L2/L3 Cache Changes
• Zen had an on-die LDO
to generate VDDM
supply for use by cache
arrays
• Zen 2’s package choices
make using package
layers for VDDM
distribution impossible
• Moved the bitline
precharge from VDDM to
VDD to reduce current
VDDM VDDM
BLT[]
BLC[]
WRCS[]
RDCSX[]
SAPCX
SAEN
WDT_X
WDC_X
XCENX
SAT
SAC
SAC_INT SAT_INT
BLPCX
WL[N:0]
BLT[]
BLC[]
WRCS[]
RDCSX[]
SAPCX
SAEN
XCENX
SAT
SAC
SAT SAC
BLPCX
WL[N:0]
NegBL Write DriverWDT_X
WDC_X](https://image.slidesharecdn.com/isscc2020zen2finalfordistribution-20200224-200224225255/85/Zen-2-The-AMD-7nm-Energy-Efficient-High-Performance-x86-64-Microprocessor-Core-18-320.jpg)


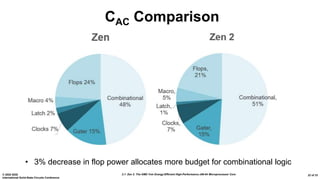
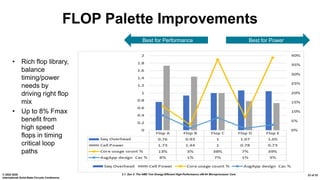

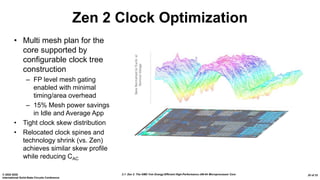
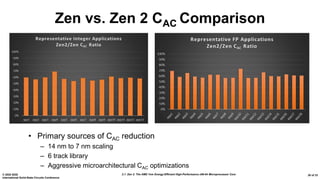
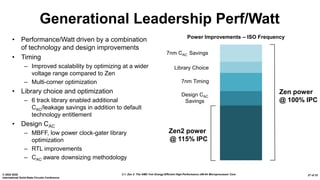
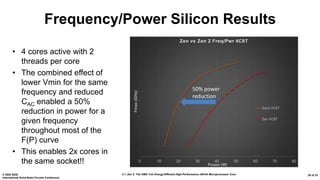
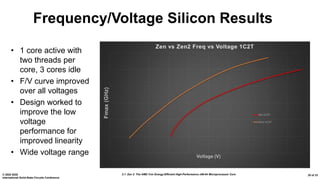




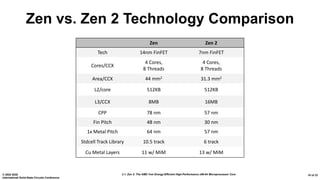
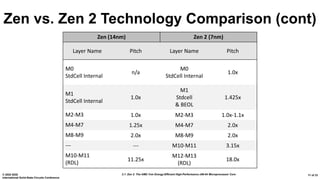
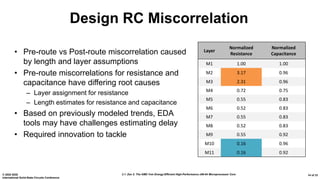
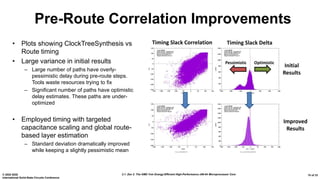
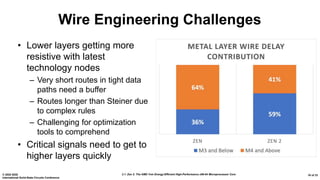
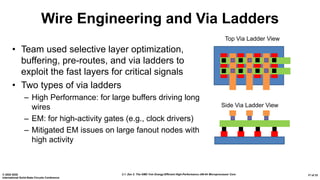
The document presents an overview of AMD's Zen 2 microprocessor architecture, detailing improvements over its predecessor, including performance enhancements, increased core counts, and power efficiency achieved through various technological innovations. It highlights specific changes in architecture, core complex configurations, and cache hierarchy, as well as the challenges and solutions involved in the design and implementation process. The analysis culminates in demonstrating substantial gains in single-thread performance and reductions in power consumption relative to the previous generation.





























![[IGC2018] AMD Don Woligroski - WHY Ryzen](https://cdn.slidesharecdn.com/ss_thumbnails/igc2018amddonwoligroski-whyryzen-181023014303-thumbnail.jpg?width=640&height=640&fit=bounds)




















































